Nvidia Announces It Has Trained the Largest Language Model in the World, GPT-2 8B!
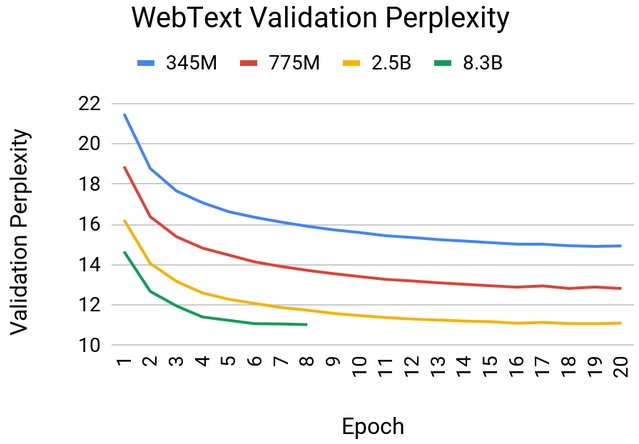
The model uses 8.3 billion parameters and is 24 times larger than BERT and 5 times larger than the previously largest GPT-2 from OpenAI. Nvidia employed parallelism that…

The model uses 8.3 billion parameters and is 24 times larger than BERT and 5 times larger than the previously largest GPT-2 from OpenAI. Nvidia employed parallelism that divided the neural network into chunks that always fit into the memory of a single GPU.
Nvidia also announced the fastest training times for the BERT model. They managed to train the BERT-Large model using optimised PyTorch software and a DGX-SuperPOD with 1472 GPUs (V100) in a record-breaking 53 minutes! Just earlier this year, we were calculating this performance in terms of weeks!
Source: https://devblogs.nvidia.com/training-bert-with-gpus/
Github: https://github.com/nvidia/megatron-lm
Original source: wordpress