Blog
The Oldest AI Blog in the Czech Republic
We have been writing about artificial intelligence since 2017. 1000+ articles, thousands of pages of thoughts, experiments, and reflections. No sensationalism, no ads.
Tag Filter: BERT × cancel
▸Browse by Topics
Topics
Showing 7 of 7 articles
 Archive 2021
Archive 2021A New Champion on the Scene?
The Switch Transformer language model from Google is nearly six times larger than GPT-3! The Switch Transformer has 9 times more parameters, totalling 1.6 trillion. Google has optimised…
Read Archive 2021
Archive 2021A Reflection on the Past Decade
You won't find the year 2020 or GPT there, but overall it's quite well done :) https://towardsdatascience.com/the-decade-of-artificial…
Read Archive 2019
Archive 2019Outputs from AI Explored at the NeurIPS Conference. What Did It Conclude?
Recently, the Neural Information Processing Systems (NeurIPS) conference took place in Vancouver, Canada, gathering over 13,000 scientists from various fields….
Read Archive 2019
Archive 2019Another Course Completed
I have just completed the course ‘Learn BERT – the most powerful NLP algorithm by Google’. It is an advanced course that introduces…
Read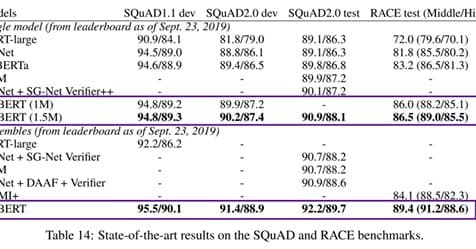 Archive 2019
Archive 2019The Latest Artificial Intelligence Model for Natural Language Processing – ALBERT!
Among the top artificial intelligence models for natural language processing (Bert, Robert, GPT-2, or Megatron), a new player ALBERT joined the ranks last week! ALBERT is brought to us by…
Read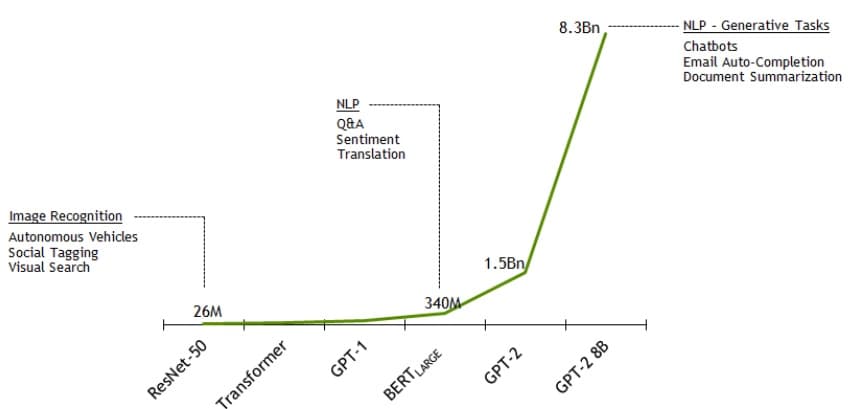 Archive 2019
Archive 2019Nvidia Announces It Has Trained the Largest Language Model in the World, GPT-2 8B!
The model uses 8.3 billion parameters and is 24 times larger than BERT and 5 times larger than the previously largest GPT-2 from OpenAI. Nvidia employed parallelism that…
Read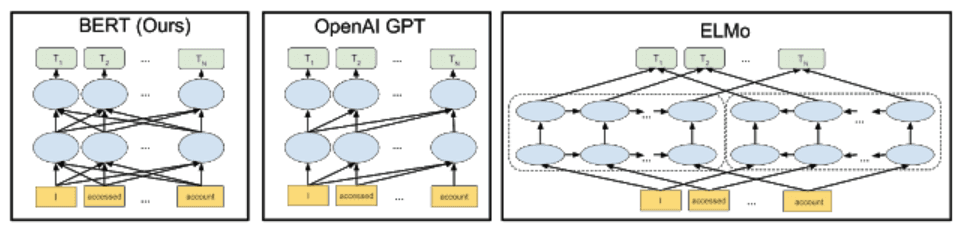 Archive 2018
Archive 2018This Week, Google Unveiled Its Latest Technological Toy – Bidirectional Encoder Representations Transformers, or BERT
How does BERT differ from traditional NLP models like word2vec and GloVe? Word2vec and other models generate context-free word embeddings. Each word...
Read