HyperFusion po opravách: DRACO benchmark a cesta k expertnej porote AI
HyperFusion sme prehnali presnejším benchmarkom DRACO. Ukázalo sa, že nestačí dať vedľa seba niekoľko modelov. Rozhoduje hlavne to, ako sa ich odpovede skladajú dohromady.

Pred pár dňami som písal článok HyperFusion: keď jeden model nestačí. Bol to text o tom, prečo mi dáva zmysel nehovoriť s jedným modelom, ale s celou malou porotou modelov. Jeden prinesie presnosť, druhý iný uhol pohľadu, tretí chytí slepé miesto. Nad tým sedí sudca, ktorý hľadá zhody, rozpory a medzery. A syntetizér z toho zloží finálnu odpoveď.
Odvtedy sme niektoré vlastnosti dotiahli oveľa ďalej. A hlavne sme HyperFusion prehnali tvrdším benchmarkom, ktorý už netestuje len pekný text, ale konkrétne pokrytie požiadaviek, citácií, metód a rozhodnutí.
Výsledok je povzbudivý: HyperFusion sa v novšej konfigurácii v3augment dostal na 84,9 % av našom behu DRACO porazil Fusion aj najlepší samostatný model. Ale možno ešte zaujímavejšia je cesta, ktorá k tomu viedla. Pretože na začiatku HyperFusion vôbec nevyzeral ako víťaz.

Souhrn výsledků: žebříček systémů, skóre po úlohách, algoritmy syntézy a vztah cena vs kvalita.
Nepýtať sa jedného experta, ale celej poroty
Keď sa dnes spýtate bežného chatbota, zodpovedá vám jeden model. Môže byť veľmi šikovný, ale stále má vlastný štýl, vlastné slepé miesta a vlastné návyky. HyperFusion pracuje inak: položí rovnakú otázku niekoľkým modelom paralelne, nechá ich odpovedať nezávisle a až potom sa pýta, čo sa z ich odpovedí dá zložiť.
To má dve výhody.
Prvá je diverzita. Jeden model nájde metodiku, druhý právny detail, tretí praktické riziko. Keď všetci hovoria to isté, rastie dôvera. Keď sa líšia, je to samo o sebe informácie.
Druhá je priehľadnosť. Nechcem čiernu skrinku, ktorá len vypľuje autoritatívny záver. Chcem vidieť, čo povedal panel, kde sa zhodol, kde si protirečil a prečo syntetizér zvolil práve túto odpoveď.
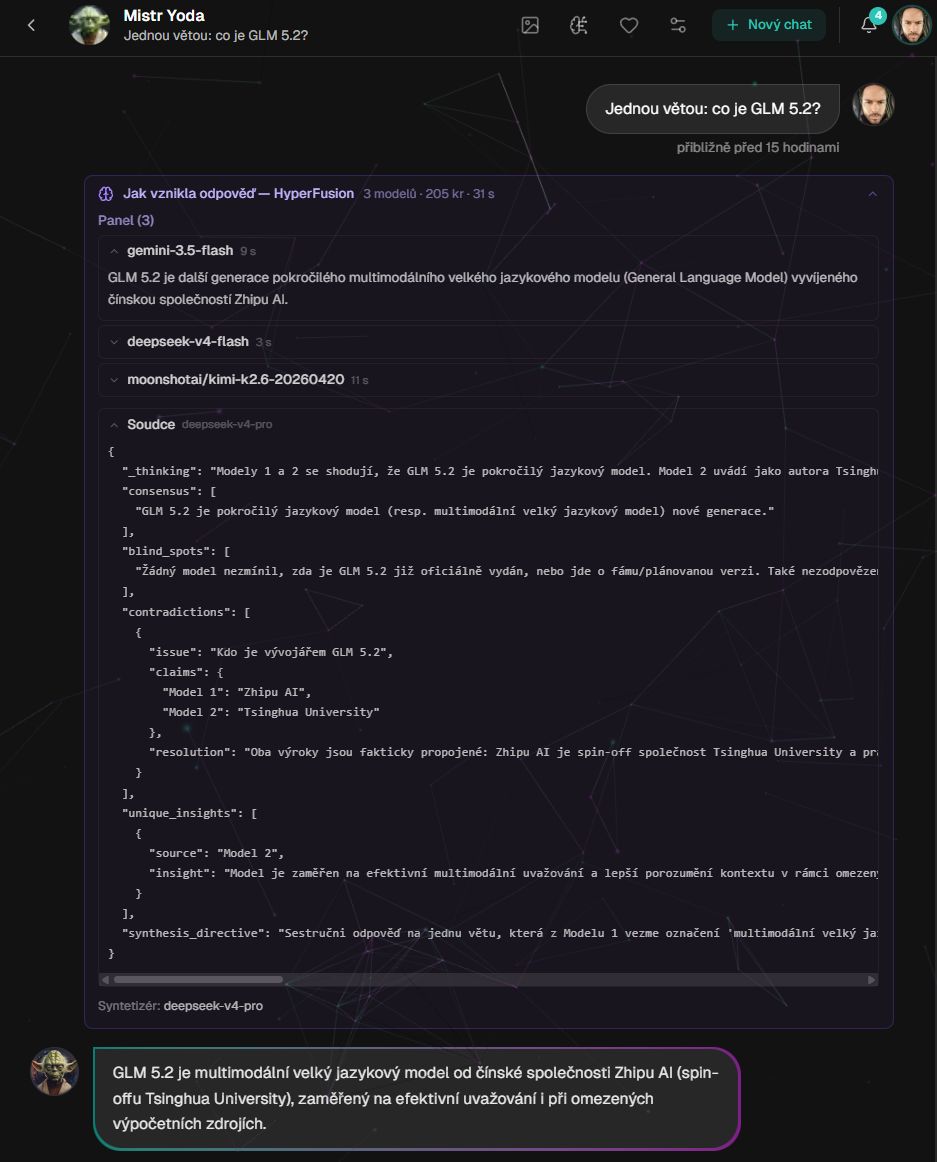
Glass-box přímo v chatu: odpovědi jednotlivých modelů, JSON analýza soudce a finální syntéza. Ne jen výsledek, ale i cesta k němu.
Ako sme testovali: DRACO
Pre presnejší test sme použili DRACO (perplexity-ai/draco), sadu náročných deep-research úloh. Nejde o jednoduché otázky typu „kto bol prezidentom“. Sú to zadania, kde sa musia kombinovať rešerše, citácie, metodická opatrnosť a schopnosť pokryť viac podkritérií naraz.
V našom behu išlo o päť úloh: od detekcie deepfakov cez technické a medicínske otázky až po komplexnejšie rešeršové problémy. Každá odpoveď sa nehodnotila len dojmom, ale podľa konkrétnych kritérií: spomenul systém správnu metódu, citoval relevantný zdroj, pokryl etický rozmer, všimol si regulačný detail, nestratil dôležitú výnimku?
Ako hodnotiaci sudca sme použili Claude Opus 4.8. Porovnávali sme:
Samostatné modely
solo
Sonnet, Gemini a další modely běžící samy za sebe.
Fusion
80,9 %
Silný konkurenční přístup, ale méně průhledný pro ladění.
HyperFusion v3augment
84,9 %
Nejvyšší skóre v našem běhu a nejlepší syntéza bez ztráty klíčových bodů.
Je fér dodať dôležitú poznámku: jeden beh benchmarku nie je definitívny vedecký verdikt. Pri podobných úlohách skóre prirodzene kolíše. Beriem to preto ako silný experimentálny signál, nie ako posledné slovo. Ale práve preto je to zaujímavé.
Čo sa najskôr nepodarilo
Prvá verzia HyperFusion nebola víťaz. Bola drahá, občas pomalá a na niektorých úlohách horšia ako Fusion.
Najväčší problém nebol v tom, že by panel modelov nevedel nájsť dobré odpovede. Problém bol v tom, čo sa stalo potom. Syntetizér niekedy vzal veľmi dobrú odpoveď jedného modelu a pri snahe „urobiť vlastné zhrnutie“ ju zničil. V jednom z testov mala najlepšia čiastková odpoveď skoro 89 %, ale finálna syntéza spadla na zlomok kvality, pretože prepísala dlhú, konkrétnu odpoveď do príliš krátkeho abstraktu.
To je presne ten typ chyby, ktorý je v bežnom chate zle vidieť. Užívateľ vidí pekný finálny odsek. Ale nevidí, že vo vnútri systému už ležala oveľa lepšia odpoveď, ktorú finálny krok poškodil.
Tu sa ukázala hodnota glass-box prístupu. Keď vidíte odpovede panelu, analýzu sudcu a finálnu syntézu, môžete ladiť systém ako skutočný produkt, nie ako magický prompt.
Prielom: neexistuje jedna najlepšia syntéza
Najdôležitejšie zistenie znie banálne, ale technicky je zásadné: každá úloha chce iný spôsob skladania odpovedí.
Pri analytických úlohách sa oplatí odpovede naozaj zliať dohromady. Model A má rámec, model B kontrast, model C lepšiu štruktúru. Tam dáva zmysel syntetizovať od začiatku.
Pri rešeršných úlohách je to iné. Keď jeden model nájde kompletnú odpoveď a ostatní pridajú len pár unikátnych detailov, je nebezpečné začať písať znova od nuly. Ľahko sa stratí citácie, výnimky, zoznamy a konkrétne formulácie.
Preto sme nasadili stratégiu v3augment: vezmi najlepšiu odpoveď, zachovaj ju čo najviac celú a len doplň unikátne body z ostatných modelov. Neprepisuj víťaza kvôli tomu, aby výstup vyzeral „novo“. Vylepši ho.
To bol skok.
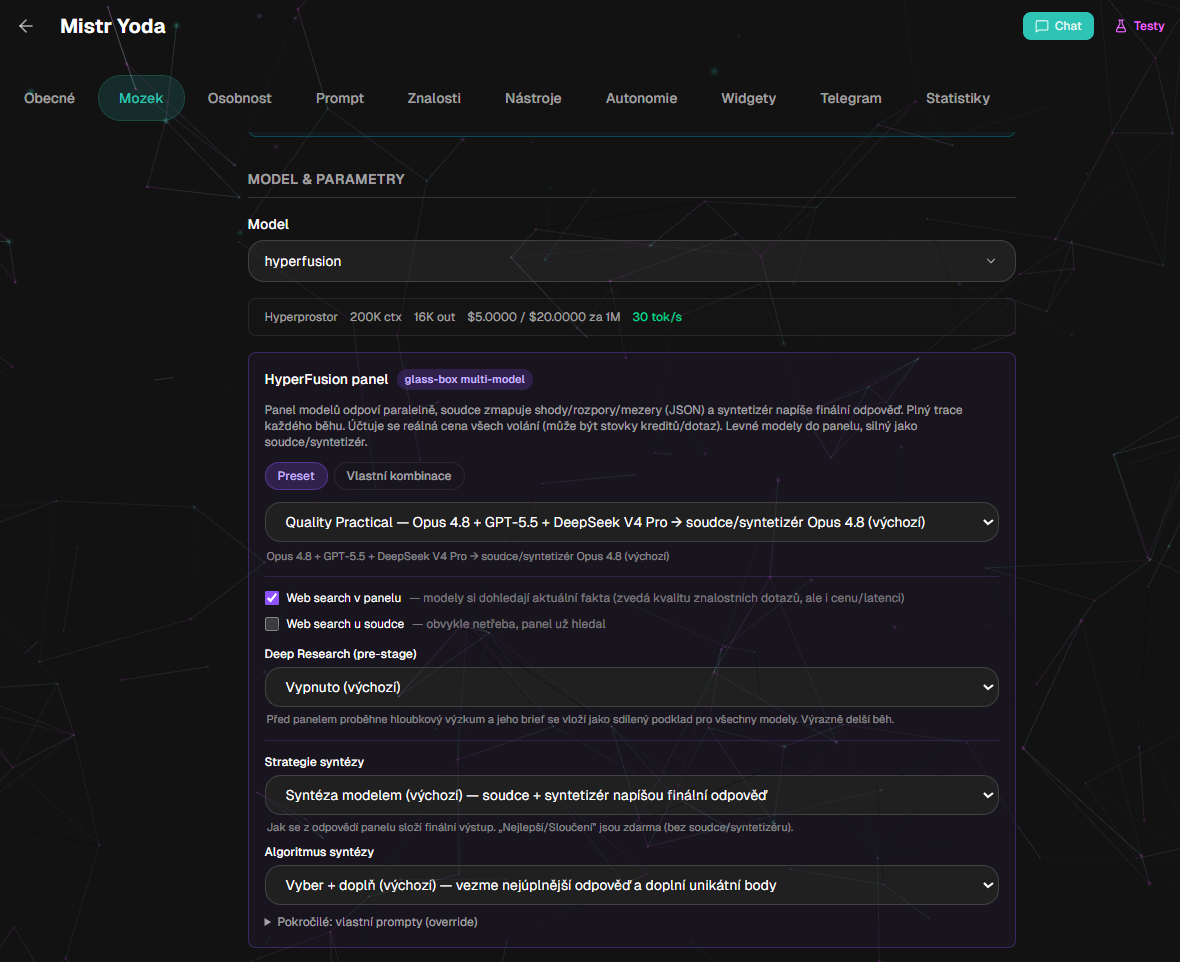
Nastavení přímo u bota: preset nebo vlastní kombinace modelů, strategie syntézy, web search, Deep Research a volba soudce či syntetizéru.
Výkon vs cena
Najzaujímavejšie graf pre mňa nie je len rebríček kvality. Je to vzťah výkon vs cena.
Na jednej strane môžete zapnúť prémiovú konfiguráciu, ktorá mieri na najvyššiu kvalitu. Na druhej strane sa ukázalo, že aj lacnejší HyperFusion Budget dokáže poraziť najlepší samostatný model v našom teste: 70,0 % vs 68,0 % pri Sonnete, pritom za približne seminovú cenu.
To je možno najpraktickejší záver celého experimentu. Multi-model systém nemusí byť len drahá hračka. Keď sa dobre poskladá, môže ponúknuť lepší pomer cena/výkon ako jeden silný model.
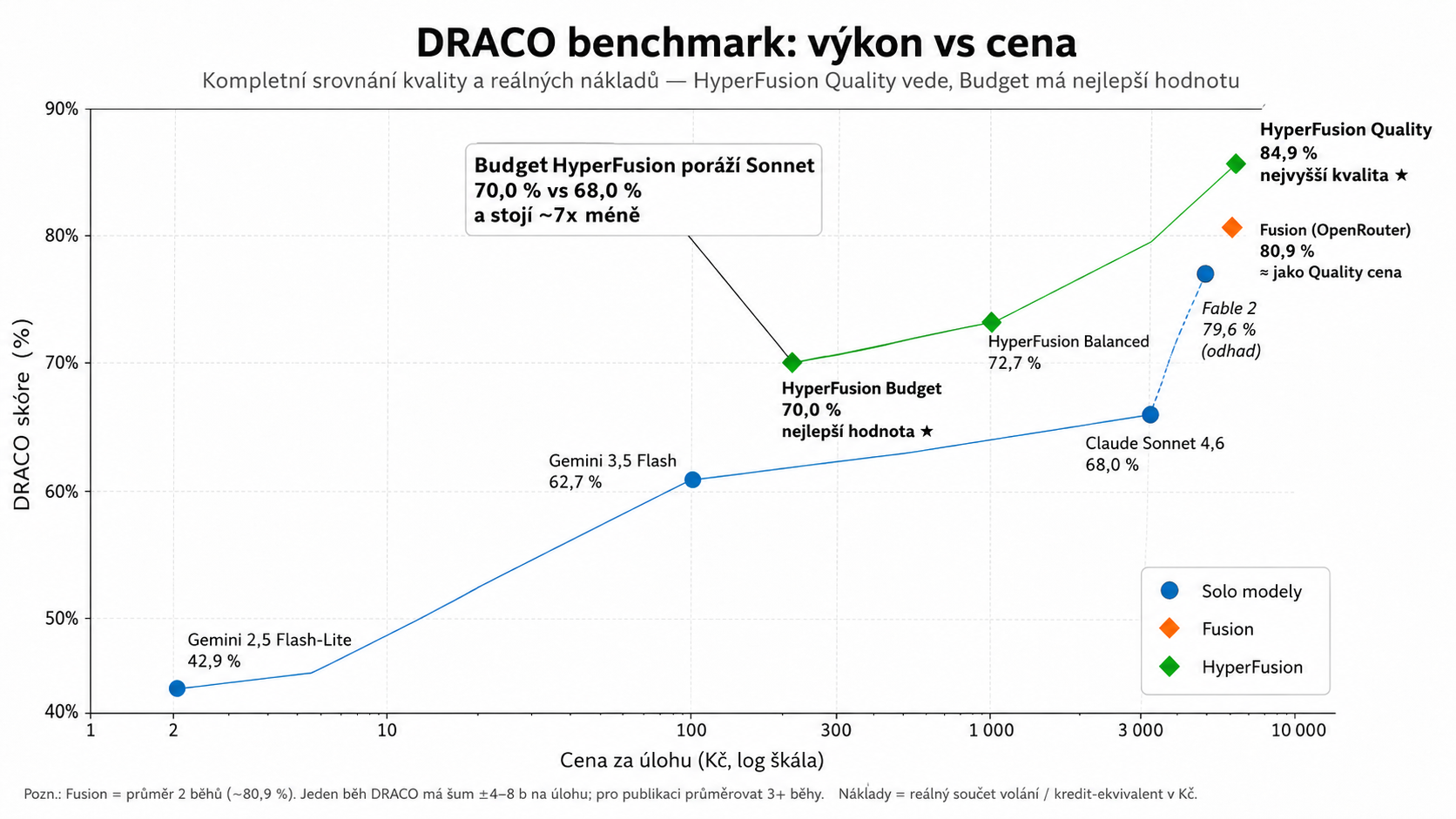
Modré body jsou samostatné modely, oranžová Fusion a zelená HyperFusion. Důležité je nejen nejvyšší skóre, ale i poloha vlevo nahoře: kvalita za rozumnou cenu.
Čo sme dotiahli
Oproti prvému pokusu sa posunuli hlavne tri veci.
Po prvé, syntéza už neničí najlepšiu odpoveď. V3augment nesúťaží s víťazom panelu, ale stavia na ňom.
Po druhé, konfigurácia je otvorenejšia. Dá sa meniť zloženie panelu, sudca, syntetizér, stratégia syntézy aj to, či sa zapne web search alebo predbežný deep research.
Po tretie, meranie je poctivejšie. Do ceny započítavame celý panel, sudca aj syntézu, nie len finálne tokeny. To je dôležité, pretože inak sa multi-model systémy tvária lacnejšie, než skutočne sú.
Táto úprimnosť niekedy bolí. Menej potešujúce sú čísla. Bez toho sa však benchmarky menia na marketing.
Prečo by som to chcel spolu otestovať
Tu by som rád urobil krok mimo nášho vlastného experimentu.
Vôbec by mi nevadilo, keby sme v Česku dali dokopy menšiu expertnú výskumnú skupinu alebo spolupracovali s nejakým združením a robili podobné testy poriadnejšie: na väčšom počte úloh, s viacerými modelmi, s opakovanými behmi, s rôznymi hodnotiacimi porotcami a s otvoreným zdieľaním skúseností.
Nie na to, aby niekto vyhlásil „najlepšiu modelku na svete“. Toto je takmer vždy zjednodušenie.
Skôr sa naučíte odpovedať na praktickejšie otázky:
- Ktorý model je dobrý pre český právny alebo školský kontext?
- Kedy sa oplatí výkonný model a kedy lacnejší panel?
- Ako veľmi pomáha vyhľadávanie na webe a kedy je škodlivé?
- Ako hodnotiť citácie, neistotu a slepé miesta?
- Ako vytvoriť benchmark, ktorý nemeria len plynulosť textu, ale aj skutočnú užitočnosť?
To mi pripadá ako práca, ktorú by sme mohli pokojne robiť spolu aj v Česku. Nie ako súťaž PR modelu, ale ako zdieľaná metodika pre ľudí, firmy, školy a inštitúcie, ktoré chcú AI využívať zodpovedne.
Záver
HyperFusion pre mňa nie je len trik, ako si „vypýtať viac modelov“. Je to smer, ako urobiť z AI lepšie ovládateľný nástroj. Modelový panel, rozhodca, syntéza, viditeľná rozhodovacia stopa a schopnosť meniť stratégiu podľa typu úlohy.
Podľa môjho názoru budúcnosť AI nebude jeden vševediaci model. Bude to spolupráca modelov, nástrojov, zdrojov a ľudského úsudku. A čím dôležitejšia bude odpoveď, tým viac budeme musieť vidieť nielen to, čo AI povedala, ale aj ako sa tam dostala.
HyperFusion zatiaľ v benchmarku DRACO ukazuje, že táto cesta má zmysel. Teraz by bolo fajn otestovať to ešte poctivejšie, s väčšou skupinou, na viacerých prípadoch a s otvorenou debatou o tom, čo vlastne od dobrej AI odpovede očakávame.
Zdroje a ďalšie čítanie
- Alpha Industries: HyperFusion: keď jeden model nestačí.
- Benchmark DRACO:
perplexity-ai/draco. - Interná HyperFusion prevádzkuje päť úloh hlbokého výskumu; hodnotiaci rozhodca Claude Opus 4.8.
Poznámka pre spravodlivosť: výsledky sú založené na obmedzenom počte cyklov a v podobných benchmarkoch existuje prirodzený rozptyl. Definitívne hodnotenie by si vyžadovalo viacero úloh, opakované spustenie a viacero nezávislých metód hodnotenia.