Jedna otázka vs. desať veľkých benchmarkov: ako veľmi sa mini IQ test trafil?
Pred pár dňami som najnovším AI modelom položil len jednu jedinú otázku — ani benchmark, ani tabuľku skóre, len jedinú intelektuálnu pascu. Po pár dňoch je čas porovnať výsledok s veľkými verejnými benchmarkmi, ktoré sa medzitým objavili. GPT-5.5 vedie, Claude Opus 4.7 mu šliape na päty, Gemini 3.1 Pro bol najväčšia odchýlka, DeepSeek V4 Pro najnižšie. Otázka, ktorú by stálo za to položiť každému modelu — skôr než mu začnete veriť.

Pred pár dňami som skúsil malý experiment: dať najnovším AI modelom len jednu jedinú otázku.
Žiadny benchmark na stovkách úloh. Žiadnu tabuľku skóre. Len jednu intelektuálnu pascu.
Model mal odvodiť pravidlá umelých funkcií mep a dap, spočítať nový prípad, priznať nejednoznačnosť, navrhnúť najlepší test, ktorý by jeho hypotézu mohol vyvrátiť, a povedať, čím si je najmenej istý.
Pointou nebolo „zmerať IQ" v psychologickom zmysle ani ukázať, že klasické benchmarky sú zbytočné.
Keby som mal modelu položiť len jednu otázku, ktorá čo najlepšie odhalí jeho analytické myslenie, metakogníciu a prácu s neistotou — aká by to bola?
Pozrelo si to vyše 50 tisíc ľudí, ale podľa komentárov mnohým pointa unikla. A po pár dňoch je zaujímavé porovnať výsledok s veľkými verejnými benchmarkmi, ktoré sa medzitým objavili.
📎 Ak ste pôvodný článok nečítali, nájdete ho tu: Jedna otázka miesto desiatich benchmarkov: mini IQ test pre najnovšie AI modely
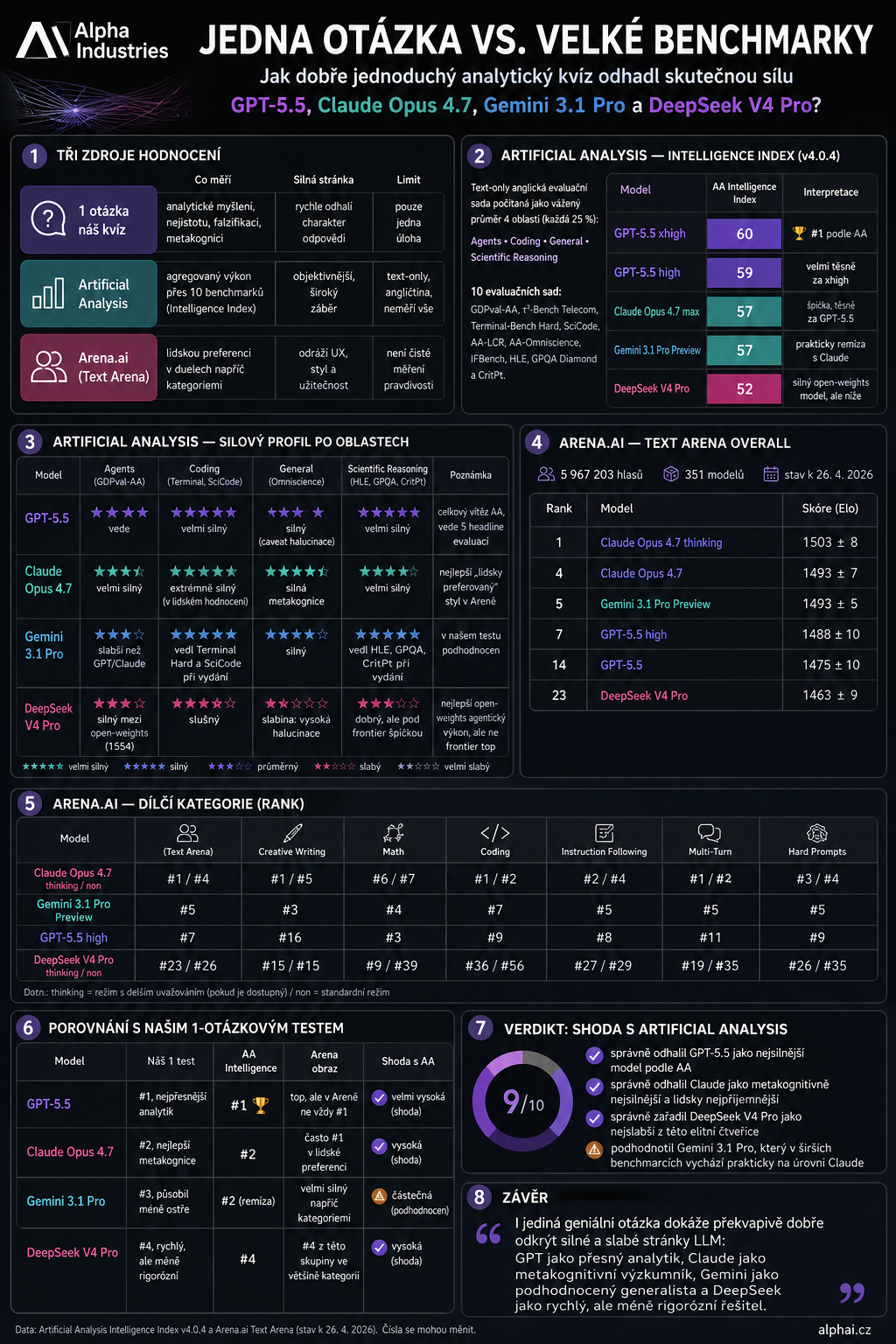
Ako meria „inteligenciu" Artificial Analysis
Artificial Analysis Intelligence Index dnes počíta inteligenciu modelov ako vážený priemer štyroch oblastí:
- Agents — 25 %
- Coding — 25 %
- General — 25 %
- Scientific Reasoning — 25 %
Dohromady ide o 10 evaluačných sád: GDPval-AA, τ²-Bench Telecom, Terminal-Bench Hard, SciCode, AA-LCR, AA-Omniscience, IFBench, Humanity's Last Exam, GPQA Diamond a CritPt.
Je férové dodať, že ide o text-only anglickú evaluačnú sadu, takže nemeria všetko — nemeria napríklad slovenčinu, multimodalitu, hlas ani reálnu UX použiteľnosť.
A ako to dopadlo?
🥇 GPT-5.5 — najistejší analytik
GPT-5.5 je podľa Artificial Analysis aktuálne na vrchu. GPT-5.5 xhigh má Intelligence Index 60, GPT-5.5 high 59.
To celkom dobre zodpovedá môjmu jednootázkovému testu, kde pôsobil ako najistejší analytik: presný, kompaktný, matematicky ostrý.
🥈 Claude Opus 4.7 — výskumník s metakogníciou
Claude Opus 4.7 má podľa Artificial Analysis 57, teda tesne za GPT-5.5. V ľudskom hodnotení je však často ešte vyššie — v Text Arena Overall je Claude Opus 4.7 thinking dokonca prvý.
To je presne zaujímavý rozdiel: GPT pôsobí ako veľmi presný „matematický strelec", Claude ako výskumník s lepšou metakogníciou, opatrnosťou a formuláciou neistoty.
🥉 Gemini 3.1 Pro — prekvapenie v širších benchmarkoch
Gemini 3.1 Pro bol v mojom jednootázkovom teste najväčšia odchýlka. V tej konkrétnej úlohe pôsobil menej ostro, o niečo menej prioritizoval podstatné a horšie pracoval s nejednoznačnosťou.
Lenže širšie benchmarky ho stavajú výrazne vyššie: Artificial Analysis mu dáva 57, teda prakticky na úroveň Claude Opus 4.7. V Aréne je tiež veľmi silný — napríklad v kreatívnom písaní, matematike, kódovaní aj hard prompts sa drží blízko špičky.
4. DeepSeek V4 Pro — silný, ale nie na špičke
DeepSeek V4 Pro vyšiel v mojom teste ako najnižší zo štvorice — rýchly, bystrý, schopný pattern recognition, ale menej rigorózny v presnosti, testovaní a práci s neistotou.
To sa podľa benchmarkov potvrdilo najviac. Artificial Analysis mu dáva 52, teda pod GPT-5.5, Claude i Gemini. Zároveň je dôležité povedať, že to nie je „hlúpy model" — naopak je to veľmi silný open-weights model, len v tejto elitnej skupine nie je na špičke.
Takže ako veľmi sa tá jedna otázka trafila?
Podľa mňa prekvapivo dobre.
Netrafila hlavne to, ako podhodnotila Gemini. Ale trafila hlavnú štruktúru:
- GPT-5.5 a Claude sú špička.
- DeepSeek V4 Pro je zo štvorice najslabší.
- Rozdiel medzi modelmi nie je len v tom, či spočítajú výsledok, ale či vedia priznať neistotu, hľadať protipríklad a nezameniť elegantnú domnienku za dôkaz.
A to bol presne cieľ.
Nešlo mi o „nový benchmark". Šlo mi o lakmusový papierik inteligencie: jednu otázku, ktorá model donúti ukázať nielen výpočet, ale aj spôsob myslenia.
A tu sa ukázalo niečo celkom povzbudivé:
Jedna dobre navrhnutá otázka benchmarky nenahradí. Ale môže prekvapivo dobre odhaliť charakter modelu.
Detailný pohľad — Intelligence Index k 29. 4. 2026
Tu vidíte modely v širšom detaile — kompletný rozpis Intelligence Indexu naprieč hlavnými poskytovateľmi (k 29. 4. 2026):
Ktorý model vám teraz dáva najlepšie výsledky? Ste skôr tím GPT, alebo tím Claude? Napíšte mi do komentárov!
#UmelaInteligencia #LLM #ChatGPT #Claude #TechTrendy #Alphai