HyperFusion po patchu: benchmark DRACO i droga do jury ekspertów AI
Przeprowadziliśmy HyperFusion przez dokładniejszy test porównawczy DRACO. Okazało się, że nie wystarczy postawić kilka modeli obok siebie. Liczy się to, jak ich odpowiedzi pasują do siebie.

Kilka dni temu napisałem artykuł HyperFusion: kiedy jeden model to za mało. To był tekst o tym, dlaczego dla mnie ma sens rozmowa nie z jedną modelką, ale z całą małą grupą modelek. Jeden przyniesie dokładność, drugi inny punkt widzenia, trzeci wyłapie martwy punkt. Nad tym siedzi sędzia szukający podobieństw, sprzeczności i luk. A syntezator ułoży z niego ostateczną odpowiedź.
Od tego czasu poszliśmy o wiele dalej w niektórych funkcjach. A co najważniejsze, przetestowaliśmy HyperFusion w bardziej rygorystycznym teście porównawczym, który nie testuje już tylko ładnego tekstu, ale konkretnego uwzględnienia wymagań, cytatów, metod i decyzji.
Wynik jest zachęcający: HyperFusion osiągnął 84,9% w nowszej konfiguracji v3augment, a w naszej wersji DRACO Fusion pobił nawet najlepszy samodzielny model. Ale być może jeszcze ciekawsza jest podróż, która do tego doprowadziła. Ponieważ na początku HyperFusion w ogóle nie wyglądał na zwycięzcę.

Souhrn výsledků: žebříček systémů, skóre po úlohách, algoritmy syntézy a vztah cena vs kvalita.
Nie pytaj jednego eksperta, ale całe jury
Kiedy dzisiaj zapytasz zwykłego chatbota, jeden model odpowiada. Może i jest bardzo mądry, ale wciąż ma swój własny styl, swoje własne słabe punkty i własne nawyki. HyperFusion działa inaczej: zadaje to samo pytanie kilku modelom równolegle, pozwala im samodzielnie odpowiedzieć, a dopiero potem pyta, co można wywnioskować z ich odpowiedzi.
Ma to dwie zalety.
Pierwszą z nich jest różnorodność. Jeden model znajduje metodologię, drugi szczegóły prawne, trzeci ryzyko praktyczne. Kiedy wszyscy mówią to samo, zaufanie rośnie. Kiedy się różnią, jest to informacja sama w sobie.
Drugim jest przejrzystość. Nie chcę czarnej skrzynki, która po prostu wypluwa autorytatywne wnioski. Chcę zobaczyć, co powiedział panel, gdzie się zgodzili, gdzie się nie zgodzili i dlaczego syntezator wybrał taką odpowiedź.
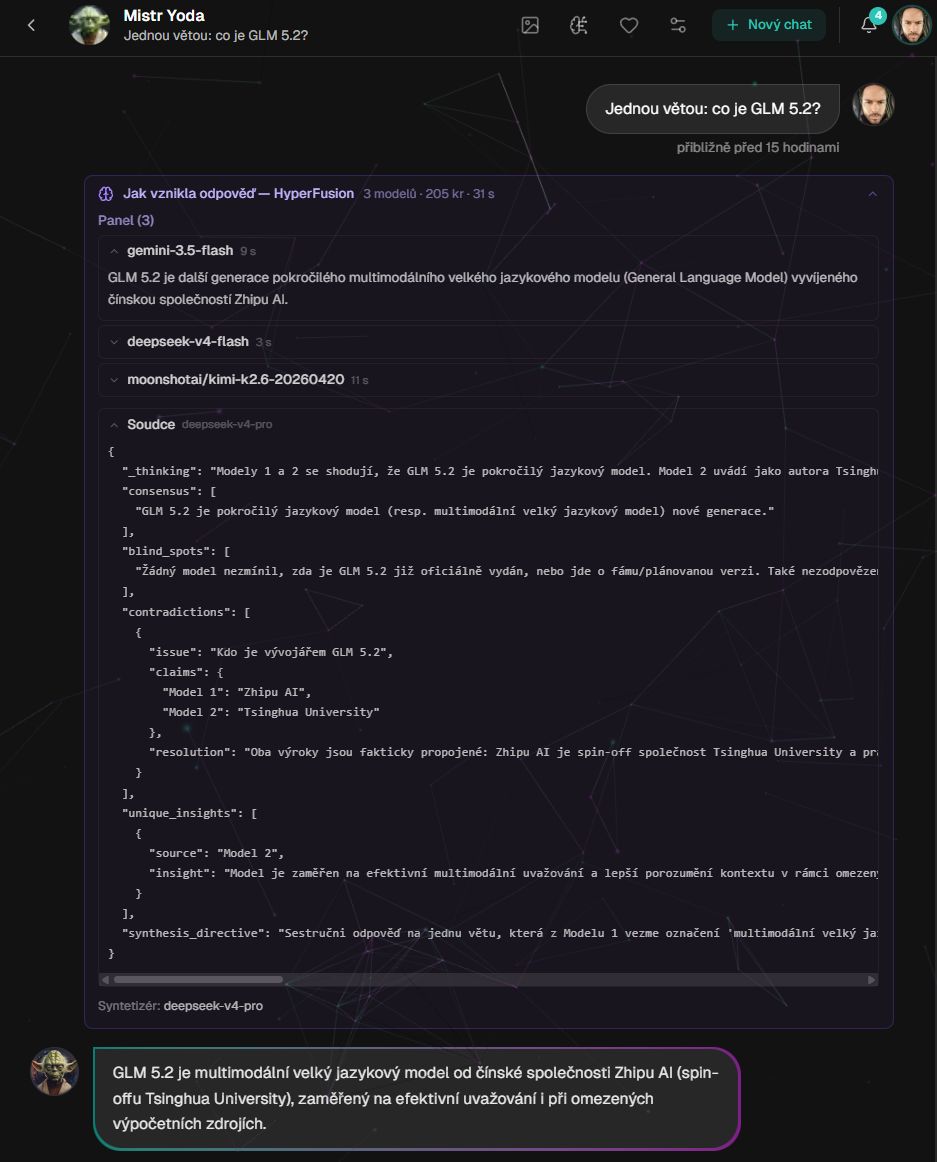
Glass-box přímo v chatu: odpovědi jednotlivých modelů, JSON analýza soudce a finální syntéza. Ne jen výsledek, ale i cesta k němu.
Jak testowaliśmy: DRACO
Aby uzyskać dokładniejszy test, użyliśmy DRACO (perplexity-ai/draco), zestawu wymagających i dogłębnych zadań badawczych. To nie są proste pytania „kto był prezydentem”. Są to zadania wymagające połączenia badań, cytowań, ostrożności metodologicznej i umiejętności uwzględnienia kilku podkryteriów jednocześnie.
Naszym zadaniem było pięć zadań: od wykrywania deepfake’ów, przez kwestie techniczne i medyczne, po bardziej złożone problemy badawcze. Każdą odpowiedź oceniano nie tylko na podstawie wrażenia, ale według określonych kryteriów: czy system wspomniał o właściwej metodzie, powołał się na odpowiednie źródło, uwzględnił wymiar etyczny, zauważył szczegół regulacyjny, czy nie pominął ważnego wyjątku?
Jako sędziego oceniającego wykorzystaliśmy Claude Opus 4.8. Porównaliśmy:
Samostatné modely
solo
Sonnet, Gemini a další modely běžící samy za sebe.
Fusion
80,9 %
Silný konkurenční přístup, ale méně průhledný pro ladění.
HyperFusion v3augment
84,9 %
Nejvyšší skóre v našem běhu a nejlepší syntéza bez ztráty klíčových bodů.
Warto dodać ważną uwagę: pojedynczy test porównawczy nie stanowi ostatecznego werdyktu naukowego. W przypadku podobnych zadań wynik naturalnie się zmienia. Dlatego traktuję to jako silny sygnał eksperymentalny, a nie ostatnie słowo. Ale właśnie dlatego jest to interesujące.
Co poszło nie tak na początku?
Pierwsza wersja HyperFusion nie była zwycięzcą. Było drogie, czasem powolne i w niektórych zadaniach gorsze od Fusion.
Największym problemem nie było to, że panel modelek nie mógł znaleźć dobrych odpowiedzi. Problemem było to, co stało się później. Syntezator czasami wziął bardzo dobrą odpowiedź z jednego modelu i zniszczył go, próbując „zrobić własne podsumowanie”. W jednym z testów uzyskała najlepszą odpowiedź częściową na poziomie prawie 89%, ale ostateczna synteza spadła do ułamka jakości, ponieważ przepisała długą, konkretną odpowiedź na zbyt krótkie streszczenie.
Jest to dokładnie ten rodzaj błędu, który trudno zauważyć na zwykłym czacie. Użytkownik widzi ładny końcowy akapit. Nie widzą jednak, że w systemie istniała już znacznie lepsza odpowiedź, którą uszkodził ostatni krok.
W tym miejscu ujawniła się wartość podejścia szklanego pudełka. Kiedy zobaczysz odpowiedzi panelu, analizę sędziego i ostateczną syntezę, możesz debugować system jak prawdziwy produkt, a nie magiczną podpowiedź.
Przełom: nie ma jednej najlepszej syntezy
Najważniejsze odkrycie brzmi banalnie, ale jest kluczowe z technicznego punktu widzenia: każde zadanie wymaga innego sposobu tworzenia odpowiedzi.
W przypadku zadań analitycznych naprawdę opłaca się łączyć odpowiedzi. Model A ma ramę, model B kontrast, model C lepszą konstrukcję. Tam sensowna jest synteza od zera.
Inaczej jest w przypadku zadań wyszukiwania. Kiedy jeden model znajdzie pełną odpowiedź, a inny doda tylko kilka unikalnych szczegółów, rozpoczynanie pisania od zera jest niebezpieczne. Cytaty, wyjątki, listy i określone sformułowania łatwo się gubią.
Dlatego wdrożyliśmy strategię v3augment: wybierz najlepszą odpowiedź, zachowaj ją w jak największej całości i dodaj tylko unikalne punkty z innych modeli. Nie nadpisuj zwycięzcy, aby wynik wyglądał na „nowy”. Popraw go.
To był skok.
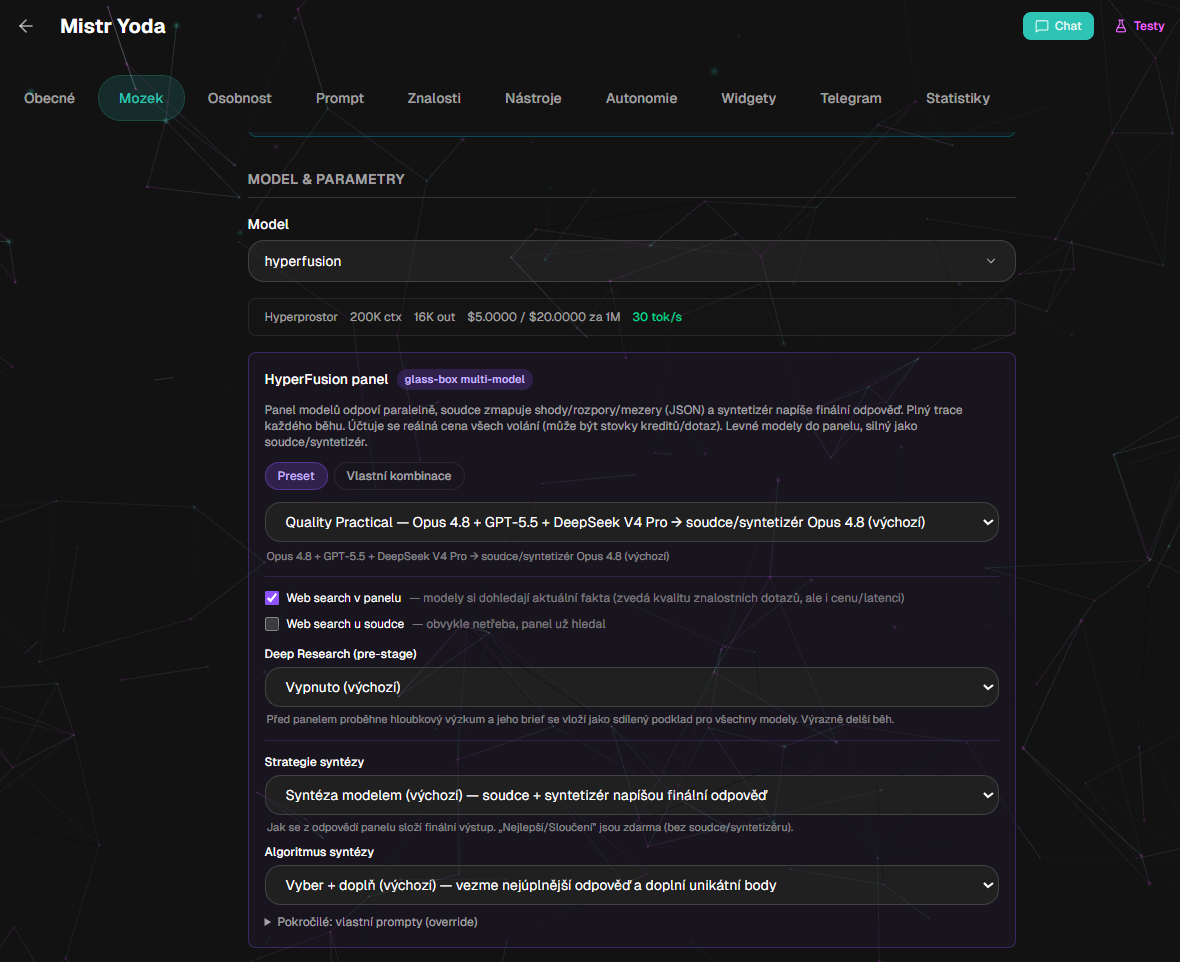
Nastavení přímo u bota: preset nebo vlastní kombinace modelů, strategie syntézy, web search, Deep Research a volba soudce či syntetizéru.
Wydajność vs cena
Najciekawszym dla mnie wykresem jest nie tylko ranking jakości. Jest to relacja wydajności do ceny.
Z jednej strony można włączyć konfigurację premium, która stawia na najwyższą jakość. Z drugiej strony okazało się, że nawet tańszy HyperFusion Budget jest w stanie pokonać najlepszy samodzielny model w naszym teście: 70,0% vs 68,0% w przypadku Sonneta, przy około czasie pracy.
To chyba najbardziej praktyczny wniosek z całego eksperymentu. System wielomodelowy nie musi być tylko kosztowną zabawką. Dobrze zmontowany może zaoferować lepszy stosunek ceny do wydajności/vniż pojedynczy, wydajny model.
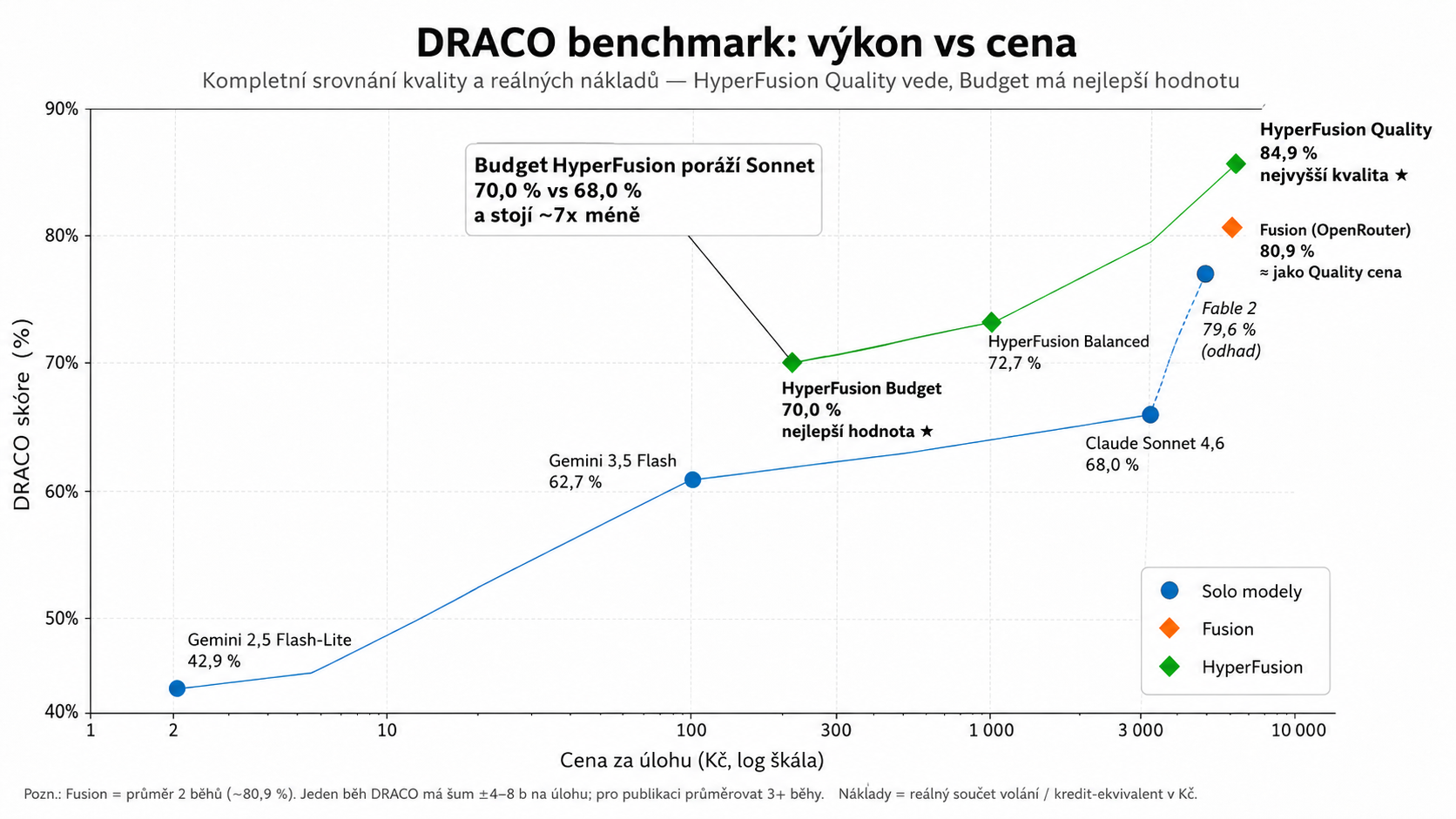
Modré body jsou samostatné modely, oranžová Fusion a zelená HyperFusion. Důležité je nejen nejvyšší skóre, ale i poloha vlevo nahoře: kvalita za rozumnou cenu.
Co osiągnęliśmy
W porównaniu z pierwszą próbą zmieniły się głównie trzy rzeczy.
Po pierwsze, synteza nie niszczy już najlepszej odpowiedzi. V3augment nie konkuruje ze zwycięzcą panelu, ale na nim bazuje.
Po drugie, konfiguracja jest bardziej otwarta. Istnieje możliwość zmiany składu panelu, sędziego, syntezatora, strategii syntezy oraz włączenia wyszukiwania internetowego lub wstępnych głębokich badań.
Po trzecie, pomiar jest bardziej uczciwy. W cenę wliczamy cały panel, sędziów i syntezę, a nie tylko końcowe tokeny. Jest to ważne, ponieważ w przeciwnym razie systemy wielomodelowe wyglądają na tańsze niż są w rzeczywistości.
Ta szczerość czasem boli. Liczby są mniej przyjemne. Ale bez tego benchmarki zamieniają się w marketing.
Dlaczego chciałbym to przetestować razem
W tym miejscu chciałbym wyjść poza nasz własny eksperyment.
Nie miałbym nic przeciwko, gdybyśmy utworzyli w Czechach mniejszą ekspercką grupę badawczą lub nawiązali współpracę z jakimś stowarzyszeniem i wykonali podobne testy w sposób bardziej poprawny: na większej liczbie zadań, z większą liczbą modeli, z powtarzalnymi przebiegami, z różnymi sędziami oceniającymi i przy otwartej wymianie doświadczeń.
Nie dla kogoś, kto deklaruje „najlepszy model na świecie”. Prawie zawsze jest to uproszczenie.
Zamiast tego naucz się odpowiadać na bardziej praktyczne pytania:
- Który model jest dobry w czeskim kontekście prawnym lub szkolnym?
- Kiedy warto zainwestować w mocny model, a kiedy w tańszy panel?
- Jak bardzo pomaga wyszukiwarka internetowa, a kiedy szkodzi?
- Jak ocenić cytowania, niepewność i słabe punkty?
- Jak zbudować benchmark, który mierzy nie tylko gładkość tekstu, ale rzeczywistą użyteczność?
Wydaje mi się, że jest to praca, którą z łatwością moglibyśmy wspólnie wykonać w Czechach. Nie jako konkurs na model PR, ale jako wspólna metodologia dla osób, firm, szkół i instytucji, które chcą odpowiedzialnie korzystać ze sztucznej inteligencji.
Wniosek
Dla mnie HyperFusion to nie tylko sztuczka polegająca na „zapytaniu większej liczby modeli”. To kierunek, w którym AI stanie się narzędziem bardziej kontrolowalnym. Panel modelowy, sędzia, synteza, widoczna ścieżka decyzyjna i możliwość zmiany strategii w zależności od rodzaju zadania.
Moim zdaniem przyszłość AI nie będzie jednym, wszechwiedzącym modelem. Będzie to współpraca modeli, narzędzi, zasobów i ludzkiego osądu. Im ważniejsza staje się odpowiedź, tym bardziej będziemy musieli zobaczyć nie tylko to, co powiedziała sztuczna inteligencja, ale także jak to się tam dostało.
Jak na razie HyperFusion w benchmarku DRACO pokazał, że ta droga ma sens. Teraz miło byłoby przetestować to jeszcze uczciwiej, w większej grupie, na większej liczbie przypadków i w ramach otwartej debaty na temat tego, czego tak naprawdę oczekujemy od dobrej odpowiedzi AI.
Zasoby i dalsza lektura
- Alpha Industries: HyperFusion: gdy jeden model to za mało.
- Test porównawczy DRACO:
perplexity-ai/draco. - Wewnętrzna funkcja HyperFusion obejmuje pięć zadań wymagających dogłębnych badań; sędzia oceniający Claude Opus 4.8.
Uwaga dotycząca uczciwości: wyniki opierają się na ograniczonej liczbie przebiegów i występują naturalne różnice w podobnych testach porównawczych. Ostateczny ranking wymagałby wielu zadań, powtarzanych przebiegów i wielu niezależnych metod punktacji.