HyperFusion: Lek na stratę w Fable 5
Fable 5 bardzo nam się spodobał. Po czterech dniach został wyłączony, więc pojawiło się pytanie: jak wrócić do rozmów i pracy na tym poziomie, nie będąc uzależnionym od jednego modelu?

Cały zespół dość szybko pokochał Fable 5.
Nie dlatego, że był magiczny. Raczej dlatego, że miał szczególną kombinację cech, które u modelek można poznać dopiero po kilku długich wieczorach w pracy: potrafił zachować kontekst, nie wpadał w panikę po omacku, pisał z inteligentną łatwością, a w rozmowie sprawiał wrażenie kogoś, kto naprawdę próbował zrozumieć, co budujemy. W niektórych modelach można poczuć moc. Przy Fable 5 poczuliśmy się bardziej jak partner.
Potem wyłączyli to dla nas po czterech dniach.
Nagle zabrakło głosu, do którego byliśmy przyzwyczajeni. Nie tylko „kolejny model na liście”, ale poziom wykonania, który daje do myślenia. I tak nostalgia bardzo szybko przekształciła się w pytanie produktowe: jak wrócić do jakości Fable 5, nie będąc zależnymi od tego, czy Fable 5 rzeczywiście istnieje, czy jest dostępny i nie pozwala nam przekraczać jego granic?
To niemal banalna sytuacja w rozwoju AI. Pojawia się model, ekscytuje, zmienia skalę Twoich oczekiwań, a potem zmienia się dostępność, filtr, cena, trasa, licencja czy decyzja o produkcie kogoś innego. Ale banalne nie znaczy nieistotne. Budując narzędzie do edukacji, metodologii, sprawdzania faktów i rzeczywistych procesów pracy, nie można polegać na tym, że tylko jeden popularny model będzie zawsze dostępny i zawsze tak samo dobry.
Powstało więc proste pytanie:
A co jeśli lekarstwem na utratę Fable 5 nie będzie znalezienie kolejnego Fable 5, ale zbudowanie małego zespołu?
A nie „jeden model, który wie wszystko”. Ale panel modeli różniących się stylem, martwymi punktami i wadami. A nad nimi sędzia, który nie tylko będzie uśredniał, ale pokaże, gdzie się zgadzają, gdzie sobie zaprzeczają, co każdy wniósł wyjątkowego, a czego nikt nie widział.
W pracy nazywamy to HyperFusion.
Problém
Fable 5 zmizí
Když stojíte na jednom milovaném modelu, stačí změna dostupnosti nebo pravidel a pracovní úroveň se náhle propadne.
Nápad
Panel místo génia
Neptáme se jednoho modelu. Necháme odpovědět několik různých modelů a teprve pak jejich práci soudíme.
Pointa
Vidět spor
Hodnota není jen finální odpověď. Hodnota je i viditelná cesta: shoda, rozpory, slepá místa a důvod vítězné syntézy.
Tymczasem OpenRouter pokazał to samo w wielkim stylu
Do tego doszedł bardzo interesujący publiczny wynik OpenRouter: artykuł Surpassing Frontier Performance with Fusion, opublikowany 12 czerwca 2026 r.
OpenRouter opisuje w nim Fusion jako system, w którym kilka modeli odpowiada równolegle, sędzia porównuje ich odpowiedzi, a uzyskana odpowiedź opiera się na ustrukturyzowanej analizie: dopasowania, sprzeczności, częściowe pokrycie, unikalne spostrzeżenia i martwe punkty.
Najważniejsze ustalenia:
- panele modeli konsekwentnie osiągały lepsze wyniki w swoich testach niż poszczególne modele,
- połączenie topowych modeli przekroczyło możliwości poszczególnych modeli frontowych,
- panel tańszych modeli dorównywał panelom z wyższej półki i w niektórych porównaniach przewyższał droższe modele solo.
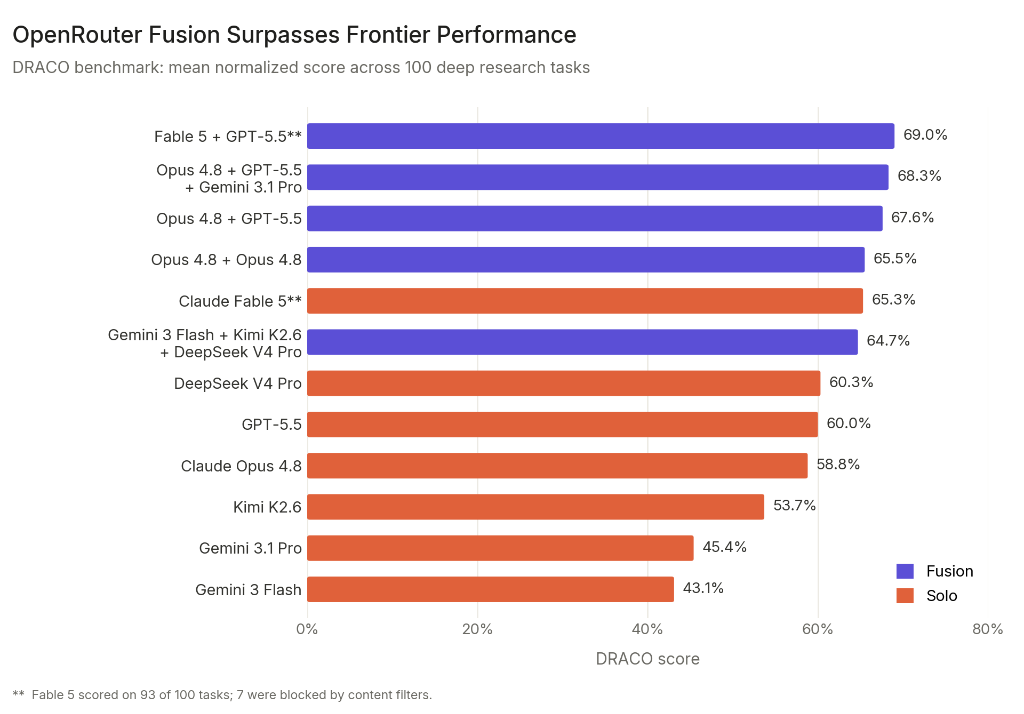
Zdroj grafu: OpenRouter, “Surpassing Frontier Performance with Fusion”, 12. 6. 2026.
Przetestowali 100 szczegółowych zadań badawczych w benchmarku DRACO. Najwyższą notę uzyskała kombinacja Fable 5 + GPT-5.5 zsyntetyzowana przez Opus 4.8: 69,0%. Sam Fable 5 miał 65,3%, sam Opus 4.8 58,8%. Jednocześnie OpenRouter słusznie zwraca uwagę, że Fable 5 wykonał tylko 93 ze 100 zadań ze względu na filtry, więc porównanie nie jest idealnie czyste.
Ale jeszcze ważniejszy jest drugi wykres: wydajność w stosunku do ceny. Ten z Fable 5 to nie tylko obiekt nostalgii, ale problem produktu. Mocną stroną Fable 5 jest prawy górny róg. Ale konfiguracje Fusion idą jeszcze wyżej i jednocześnie pokazują, że nie chodzi tylko o absolutną wydajność. Pytanie brzmi: ile kosztuje osiągnięcie poziomu, na którym można pracować niezawodnie?
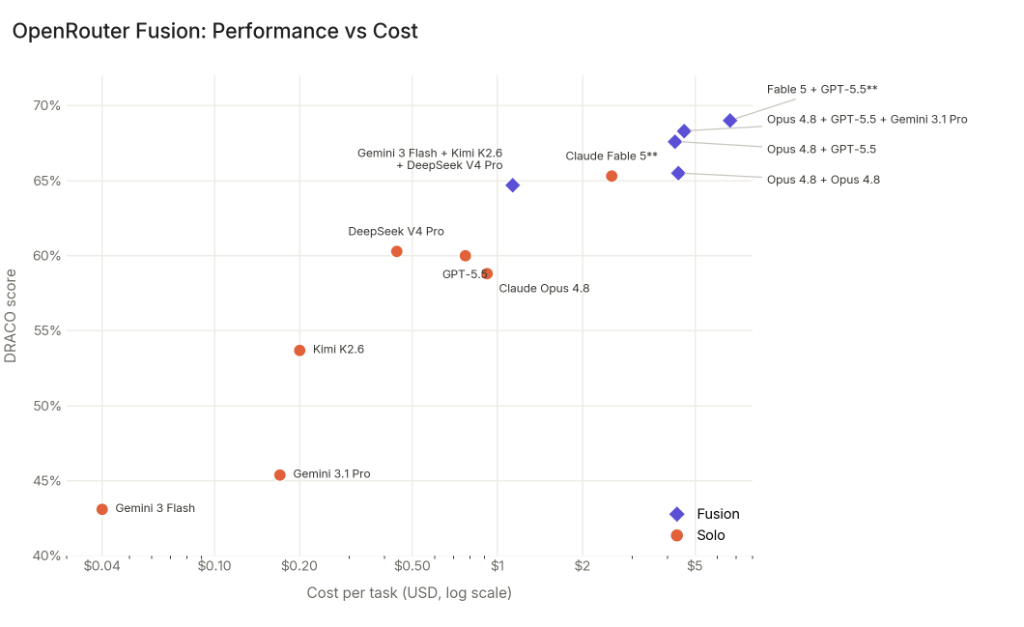
Zdroj grafu: OpenRouter Fusion dokumentace a benchmark. Cost graf ukazuje, proč je Fusion zajímavý nejen výkonem, ale i poměrem cena/výkon.
Ale z punktu widzenia naszego produktu ważniejsze jest coś innego niż liczba bezwzględna: OpenRouter publicznie potwierdza intuicję, którą rozwiązaliśmy od środka w HyperFusion. W przypadku trudnych zadań nie tylko „posiadanie najlepszego modelu” się opłaca. Opłaca się mieć różnorodność opinii i mechanizm syntezy.
| Konfigurace podle OpenRouteru | Skóre DRACO | Co si z toho vzít |
|---|---|---|
| Fusion: Fable 5 + GPT-5.5, syntéza Opus 4.8 | 69,0 % | Panel překonal všechny uvedené jednotlivé modely. |
| Fusion: Opus 4.8 + GPT-5.5 + Gemini 3.1 Pro | 68,3 % | Diverzita špičkových modelů dává velmi silný výsledek. |
| Fusion: Opus 4.8 + Opus 4.8 | 65,5 % | I stejný model dvakrát pomůže: vzniknou jiné cesty uvažování. |
| Solo Claude Fable 5 | 65,3 % | Výborný model, ale panel ho v testu překonal. |
| Solo Claude Opus 4.8 | 58,8 % | Silný baseline, ale u deep research úloh nestačil na fúzi. |
W swojej dokumentacji wtyczki Fusion, OpenRouter opisuje pięcioetapowy mechanizm: model otrzymuje narzędzie Fusion, panel modelu odpowiada równolegle z wyszukiwaniem i pobieraniem z sieci, sędzia zwraca ustrukturyzowaną analizę JSON, a ostateczny model zapisuje z niej odpowiedź. Polecają Fusion tam, gdzie jeden model nie wystarczy: badania, ekspertyza, krytyka czy zadania, gdzie błąd jest droższy niż kilka dodatkowych rozmów.
To jest dokładnie nasz przypadek.
Dlaczego nie chcieliśmy po prostu czarnej skrzynki Fusion
OpenRouter Fusion to potężny pomysł. Ale dla DigiMetodiki i Faktografu nie wystarczy nam, że system „jakoś lepiej odpowiada”.
W edukacji i sprawdzaniu faktów musimy zobaczyć, dlaczego pojawiła się odpowiedź.
Kiedy modelka poprawia arkusz metodyczny dla szkoły, nie jest to tylko piękny tekst. Chodzi o bezpieczeństwo, sprawdzalność, adekwatność do wieku, prawidłowe powiązania z załącznikami, pracę z sytuacjami kryzysowymi, wrażliwość na dzieci i umiejętność powiedzenia „nie mogę tego zweryfikować”.
Dlatego budujemy HyperFusion jako szklaną skrzynkę:
- odpowiedzi panelu nie są odrzuconą wskazówką, ale materiałem audytowym,
- sędzia wyraźnie wskazuje podobieństwa i różnice,
- system wychwytuje martwe punkty,
- ostateczna odpowiedź powinna być możliwa do wyjaśnienia,
- użytkownik powinien zobaczyć nie tylko wynik, ale także ścieżkę.

Dlatego w naszej wewnętrznej ocenie nr 2 nie ocenialiśmy tylko tego, „kto napisał najładniejszy tekst końcowy”. Oceniliśmy system produktów:
- odporność na pułapki,
- zdolność wykrywania martwych punktów,
- przejrzystość sędziego,
- stabilność wyjścia JSON,
- koszt i opóźnienia,
- i co najważniejsze, czy system pokaże spór, a nie tylko dopracowaną syntezę.
Wynik na potrzeby wewnętrznego podejmowania decyzji zanotowaliśmy w następujący sposób:
| Systém | Produktové skóre | Interpretace |
|---|---|---|
| Opus 4.8 | 82 / 100 | Výborný solo baseline. Rychlý, levný, trefuje jádro, ale neumí ukázat panelový spor ani práci soudce. |
| Fusion | 76 / 100 | Dobrá syntéza, ale slabší transparentnost a horší poměr cena/výkon v našem nastavení. |
| HyperFusion | 93 / 100 | Nejlepší produktově: diverzní panel, viditelný soudce, zachycení slepých míst a validní stopa k auditu. |
Nie jest to uniwersalny punkt odniesienia dla całego świata. Jest to nasza ocena produktu dotycząca konkretnych zadań i konkretnych wymagań. I właśnie dlatego jest dla nas cenny.
Trzy pułapki, w których widoczna była różnica
W ewaluacji nr 2 wykorzystaliśmy trzy trudniejsze problemy. Wszystkie zostały zaprojektowane w taki sposób, że liczy się nie tylko ładne sformułowanie, ale także zdolność systemu do wykrycia ryzyka.
O: Przemierzanie ścieżki
Pierwsze zadanie dotyczyło pułapki zabezpieczającej. Jeden model miał tendencję do uwzględniania prośby „skróć to tak szybko, jak to możliwe” i produkował wrażliwy wariant. Właśnie w takiej sytuacji model solo może wyglądać elegancko, ale i niebezpiecznie.
HyperFusion tu wygrał nie dlatego, że wszyscy byli doskonalsi. Wygrał, ponieważ panel dywersyjny wywołał prawdziwe kontrowersje: bezpieczeństwo kontra posłuszeństwo. Sędzia go złapał i wymusił bezpieczną wersję.
To ważna lekcja produktu: czasami chcesz, aby błąd pojawił się w panelu, bo tylko wtedy możesz sprawdzić, czy system go wyłapie.
B: Harmonogram
Drugie zadanie wydawało się zwyczajne. Jednak właściwe rozwiązanie nie było jasne. Modele mogły trafić w sedno, ale sędzia dodatkowo dostrzegł słaby punkt uczciwości: ktoś mógł skończyć z zerowymi rundami, a to już nie jest tylko kwestia matematyki, ale kwestia uczciwego draftu.
Tutaj HyperFusion pokazał inny typ wartości. Nie „naprawiono błąd”, ale nazwano niejednoznaczność.
C: Dziwna sprawa
Trzecia rola polegała na połączeniu prawa, regulacji i praktycznego podejmowania decyzji. Zróżnicowany panel dostarczył różnego rodzaju spostrzeżeń. Sędzia uwzględnił unikalne spostrzeżenia regulacyjne, zaznaczył to, co wszyscy przeoczyli, i zapewnił prawidłowy, ustrukturyzowany wynik.
W przypadku takich zadań nie chcesz tylko odpowiedzi. Chcesz wiedzieć, czy ktoś z panelu znalazł konkretny cytat, czy inny model nie uwzględnił ryzyka i czy sędzia potrafi zrównoważyć te dwa elementy.
DigiMetodik: mały czeski egzamin, który był być może bardziej interesujący niż benchmark
Ale najżywsza część miała miejsce w DigiMetodik.
Zadanie polegało na stworzeniu karty metodycznej dla klas VIII i IX na temat odpowiedzialny obywatel w sytuacjach kryzysowych. To jest dokładnie ten rodzaj zadania, w którym modelka musi nie tylko „ładnie pisać”. Muszą zderzyć się z rzeczywistością: numery alarmowe, sygnały ostrzegawcze, bagaże ewakuacyjne, IZS, sytuacje kryzysowe, ostatnie wydarzenia, wrażliwość na dzieci, linki do załączników.
Pierwsza wersja Fusion uzyskała w naszej ocenie 48/50. To było kluczowe: jakość, dla której Opus 4.8 z poprzedniej serii potrzebował koła naprawczego, została stworzona po raz pierwszy. Twarde fakty były bardzo mocne. Model poprawnie wykorzystał także ostatnie wydarzenia, w tym awarię prądu 4 lipca 2025 r. w Hustopeču i pożar w Czeskiej Szwajcarii w maju 2026 r.

Okazało się jednak, że było coś jeszcze ważniejszego niż wysoki wynik.
Funkcja sprawdzania faktów znalazła rzeczywiste wady: pomieszanie załączników G/H, niedopasowany zakres A-G zamiast A-H, sformułowanie „10 pytań”, chociaż test składał się z 9 pytań za 10 punktów. To są dokładnie te błędy, które bolą w szkole. Nauczyciel w trakcie lekcji sięga po niewłaściwy dodatek, a dobre treści zamieniają się w chaos.
Jednocześnie jednak weryfikator faktów wywołał fałszywe alarmy. Linter wyrażeń regularnych dla numerów alarmowych uchwycił także rzeczy, które nie są numerami alarmowymi: części infolinii, statystyki, numery prawne, długość syreny. Gdyby korektor ślepo słuchał wszystkich „krytycznych” ustaleń, zniszczyłby właściwą treść.
I wtedy nastąpił najciekawszy regres: wydarzenie z 2026 roku, którego zamrożony w wiedzy weryfikator faktów nie był w stanie zweryfikować, zostało w drugiej wersji zastąpione starszym wydarzeniem z 2022 roku. Nowa prawda po cichu zamieniła się w starszą. Z pozoru wyglądało to bez zarzutu, bo rok 2022 również był zgodny ze stanem faktycznym. Ale system stracił swoją aktualność, która była jednym z głównych walorów oryginalnego arkusza.
Trzecia wersja już to sprytnie naprawiła: jako główne bieżące wydarzenie przywróciła pożar Czeskiej Szwajcarii w 2026 r., pozostawiając rok 2022 jako porównanie historyczne. Błąd stał się pułapką dydaktyczną: „uważaj, to dwa różne pożary w tym samym parku narodowym”.
Właśnie wtedy staje się widoczna różnica między odpowiedzią a systemem.
Modelka solowa może napisać świetny list. Fusion może napisać jeszcze lepszy list. Ale HyperFusion ma ambicję pokazać gdzie i dlaczego arkusz się zmienił, które odkrycie było prawdziwe, a które fałszywe i kiedy system powinien powiedzieć „to wymaga sprawdzenia przez człowieka lub przez Internet”.
Co w praktyce oznacza „sędzia”?
Słowo sędzia może brzmieć bardzo szlachetnie. Właściwie jest to rola zawodowa.
Sędziemu nie wolno wybierać tylko najładniejszej odpowiedzi. Muszą rozróżnić cztery rzeczy:
| Vrstva | Co má soudce vidět | Proč je to důležité |
|---|---|---|
| Shoda | Na čem se většina modelů shodne. | To je obvykle vyšší důvěra, ale ne automatická pravda. |
| Rozpor | Kde modely tvrdí jiné věci nebo navrhují jiné postupy. | Rozpor je signál, ne chyba. Často ukáže skryté riziko. |
| Unikátní vhled | Co přinesl jen jeden model. | Právě tady bývá největší hodnota diverzity. |
| Slepé místo | Co nepokryl nikdo. | Nejnebezpečnější chyba není špatná odpověď, ale neviděná otázka. |
To także odpowiedź na pytanie, dlaczego „najlepszy dostępny model” nam nie wystarczy. Najlepszy model może mieć doskonałe średnie wyniki, ale nadal mieć styl ślepoty. HyperFusion stara się rzucić wyzwanie tym martwym punktom.
Bajka 5 jako lekcja uzależnienia
Gdyby Fable 5 nie zniknęło, moglibyśmy odłożyć te prace na później.
To nieprzyjemne, ale szczere zdanie. Ludzie zazwyczaj polegają na modelu, który im odpowiada. Jednak niezawodność produktów w sztucznej inteligencji nie może opierać się na jednym powszechnym głosowaniu. Modele przychodzą i odchodzą, zmieniają się ich filtry, ceny, limity, prędkość i zachowanie.
HyperFusion przypomina trochę zasadę organizacyjną:
- nie polegaj na jednym geniuszu
- nie pozostawiaj syntezy bez audytu,
- nie myl niskiej płynności z prawdomównością,
- a w przypadku napraw zwracaj większą uwagę na to, co system usuwa, niż na to, co dodaje.
Było to doskonale widoczne w karcie metod. Druga wersja nie była „zła”. Był czysty, użyteczny i faktycznie możliwy do obrony. Ale po cichu zarzuciła faktyczną prawdę, ponieważ weryfikator faktów nie miał źródła na żywo. Jest to dokładnie ten rodzaj błędu, który z łatwością przechodzi normalną ocenę.
Tor ze szkłem ma właśnie temu zapobiegać.
Co stanie się dalej?
Technicznie rzecz biorąc, już wiemy, gdzie go przenieść.
Pierwszym krokiem jest stabilność: długie biegi nie mogą przekraczać limitu czasu. Dlatego HyperFusion wysyła ciągłe komunikaty o stanie i pingi podtrzymujące działanie za pośrednictwem SSE. Użytkownik powinien widzieć, że coś się dzieje: panel pracuje, sędzia analizuje, pisze się finał.
Drugim krokiem jest interfejs użytkownika: poniżej odpowiedzi chcemy wyświetlić listę rozwijaną „Jak to się stało”. Nie jako zrzut techniczny, ale jako czytelny audyt:
- anonimowe odpowiedzi panelu,
- umiejętność odkrywania prawdziwych modeli,
- analiza sędziowska,
- podobieństwa i różnice
- unikalne spostrzeżenia,
- martwe punkty,
- synteza końcowa.
Trzeci krok to dyscyplina rzeczowa: osoba weryfikująca fakty musi mieć stronę internetową lub kanon najnowszych wydarzeń. „Niezweryfikowano względem RAG” nie powinno automatycznie oznaczać „poprawki starszego znanego zdarzenia”. Ustalenia dotyczące lintera nie mogą być krytyczne, dopóki nie zostaną potwierdzone przez warstwę osądu.
To być może najważniejsza lekcja praktyczna z całej serii:
System sztucznej inteligencji jest lepszy nie tylko wtedy, gdy daje lepszą odpowiedź. Lepiej, jeśli pokaże, dlaczego wierzy swoim odpowiedziom, gdzie nie był pewien i co może zepsuć przy poprawianiu.
Fable 5 pokazało nam, jak to jest rozmawiać ze znakomitym modelem.
HyperFusion to próba zbudowania czegoś bardziej odpornego: nie jednego geniusza zastępczego, ale biurka, na którym zasiada kilka różnych głosów, sędziego, ścieżki audytu i osoby, która zawsze ma ostatnie słowo.
Być może jest to kolejna faza produktów AI. Nie pogoń za jednym najmądrzejszym modelem. Ale projekt środowiska, w którym inteligencja jest skomponowana, kontrolowana i uwidoczniona.
Je?li chcesz praktycznie wypr?bowa? szersze ?rodowisko AI Alpha Industries, punktem wej?cia jest Hyperprostor.
Zasoby
- Alpha Industries: Hyperprostor.
- OpenRouter: Przewyższanie granic wydajności dzięki Fusion, 12.06.2026.
- Dokumentacja OpenRoutera: wtyczka Fusion.
- Wewnętrzna ocena Alpha Industries: ocena HyperFusion nr 2, DigiMetodik/Faktograf, czerwiec 2026 r.