HyperAdvisor i HyperFusion Deep: turbo boost dla AI i nowa warstwa systemu rozumowania
Co by było, gdyby sztuczna inteligencja działała jak procesor w laptopie: przez większość czasu tania i szybka, ale w przypadku ciężkich zadań automatycznie przełączała biegi? A co jeśli do najtrudniejszych zagadnień poznawczych nie wystarczy lepszy model, ale cała orkiestra ekspertów?

Osiem lat temu wpadłem na prosty pomysł. Każdy komputer, którego używasz, robi to cały czas: procesor nie pracuje cały czas z pełną wydajnością. Kiedy piszesz e-mail, działa on z niską częstotliwością i prawie nie je. Kiedy rozpoczynasz renderowanie, grę lub kompilację, wszystko zaczyna działać na wysokich obrotach. Intel nazwał to Turbo Boost, jest to w zasadzie dynamiczne skalowanie wydajności.
Pełną wydajność uzyskujesz tylko wtedy, gdy naprawdę jej potrzebujesz.
A tego właśnie przez długi czas brakowało sztucznej inteligencji.
Problem: zazwyczaj nie potrzebujesz najmocniejszego modelu
Najlepsze modele są niesamowite, ale drogie. A oto przydatny haczyk: większość zapytań nie wymaga żadnej inteligencji granicznej. „Co to jest 6 + 3?” lub „podsumuj dla mnie ten akapit” można wykonać tanim i szybkim modelem za ułamek kosztów.
Jeśli jednak ustawisz bota na najpotężniejszy model, zapłacisz najwyższą stawkę za każdą wiadomość, nawet banalne pytanie. To tak, jakby procesor laptopa pracował z pełną wydajnością przez cały czas, nawet jeśli tylko czytasz pocztę.
Dlatego stworzyliśmy HyperAdvisor.
HyperAdvisor: turbodoładowanie dla AI
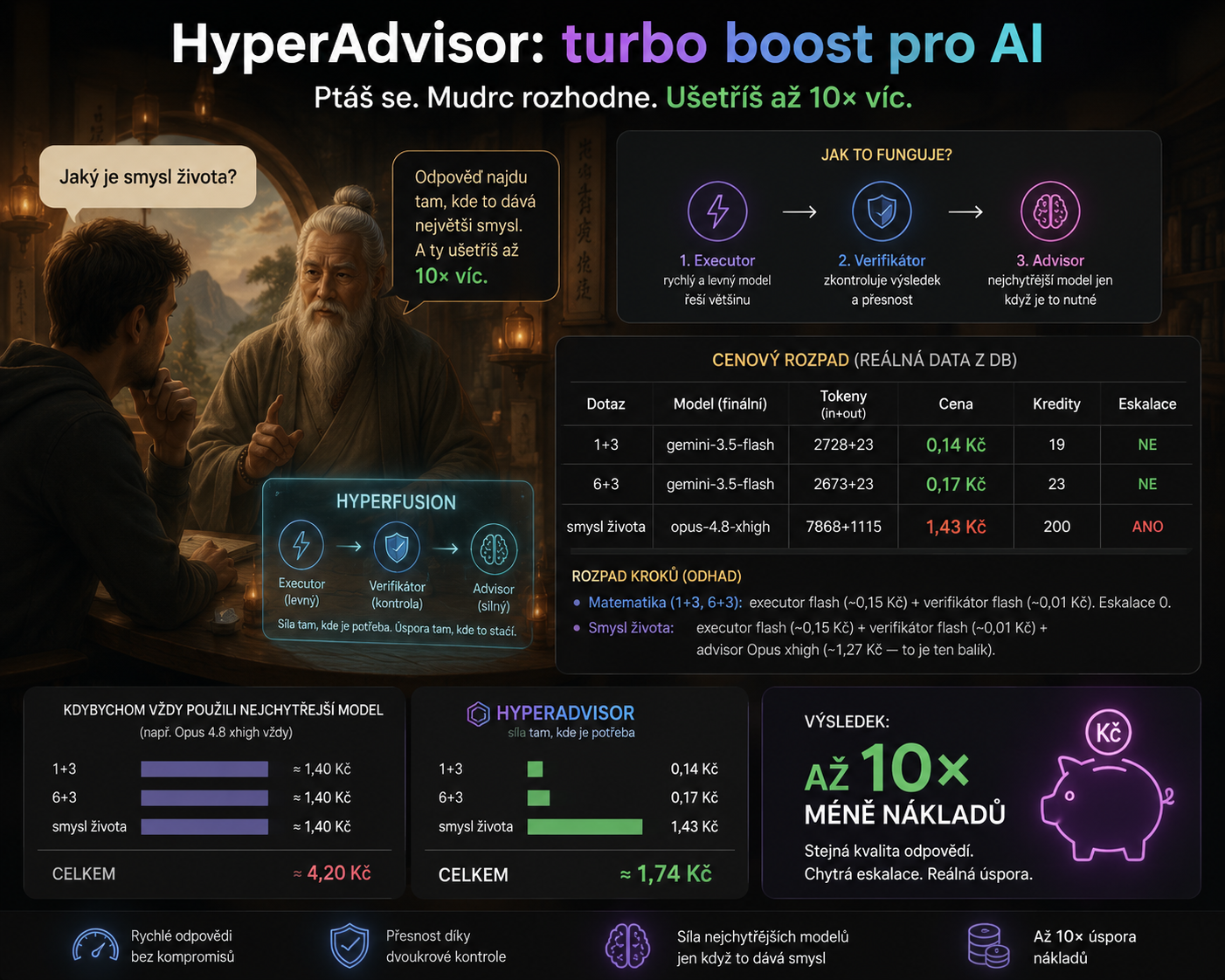
HyperAdvisor funguje jako chytrý mudrc u brány: většinu dotazů nechá vyřešit levně, ale když je otázka těžká, pustí dovnitř nejsilnější model.
HyperAdvisor działa w trzech krokach:
- Najpierw odpowie tani i szybki model.
- Drugi tani model samodzielnie sprawdza swoją odpowiedź.
- Dopiero gdy kontrola znajdzie wątpliwość, system eskaluje do najsilniejszego modelu.
Rzecz w drugim kroku. Są rozwiązania, w których słabszy model sam musi zdecydować, że do czegoś nie jest wystarczająco dobry. Ale słabszy model często nie wie, że nie wie. Dlatego HyperAdvisor korzysta z niezależnego weryfikatora. Ten ostatni może wychwycić, że tani model odpowiedział pewnie, ale błędnie, i dopiero wtedy wprowadza do gry wagę ciężką.
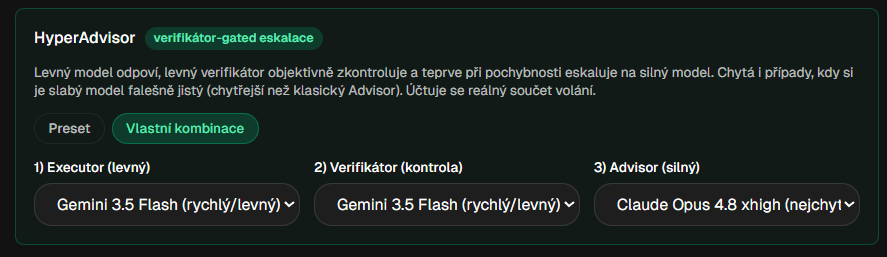
HyperAdvisor: levný model odpoví, levný verifikátor zkontroluje a jen při pochybnosti eskaluje na silný model.
Oznacza to ogromne oszczędności na prostych zapytaniach. Nasz test na Mistrza Yodę zawierał proste pytania, takie jak „Co to jest 1 + 3?” lub „co to jest 6 + 3?” około dziesiątych części korony. Trudniejsze pytanie: „Jaki jest sens życia?” przesunięto do najpotężniejszego modelu i kosztowano o rząd wielkości więcej, ale właśnie w tym przypadku miało to sens.
Nie oszczędzamy, wykonując mniej pracy. Oszczędzamy uruchamiając normalną pracę na niższej „częstotliwości”, a pełną moc włączamy tylko dla zadań, które tego naprawdę potrzebują.
Ile to kosztuje w praktyce?
Największą różnicę widać w prostej arytmetyce. Gdybyśmy zawsze korzystali z najsilniejszego modelu, każda wiadomość kosztowałaby mniej więcej tyle samo, niezależnie od stopnia trudności. Jednak HyperAdvisor wypuszcza kosztowny model tylko wtedy, gdy weryfikator znajdzie powód do eskalacji.
| Dotaz | Finální model | Cena HyperAdvisoru | Kdyby jel vždy nejsilnější model | Úspora | Eskalace |
|---|---|---|---|---|---|
| 1 + 3 | Gemini 3.5 Flash | 0,14 Kč | cca 1,40 Kč | až 10× levněji | ne |
| 6 + 3 | Gemini 3.5 Flash | 0,17 Kč | cca 1,40 Kč | zhruba 8× levněji | ne |
| Jaký je smysl života? | Claude Opus 4.8 xhigh | 1,43 Kč | cca 1,40 Kč | nešetří, používá sílu tam, kde dává smysl | ano |
O to właśnie chodzi: nie trzeba wybierać pomiędzy „tanim, ale głupszym” a „inteligentnym, ale drogim”. Może mieć jedno i drugie. HyperAdvisor wykorzystuje najmądrzejszy model jako rzadki zasób: nie w przypadku każdej banalności, ale dokładnie tam, gdzie potyka się tani model lub gdzie pytanie wymaga głębi.
W małym teście trzy zapytania będą kosztować około 4,20 CZK przy ciągłym korzystaniu z najsilniejszego modelu. HyperAdvisor zarządzał nimi za około 1,74 CZK. A w ruchu ulicznym, gdzie większość zapytań jest prosta, oszczędności mogą być bliskie dziesięciokrotności.
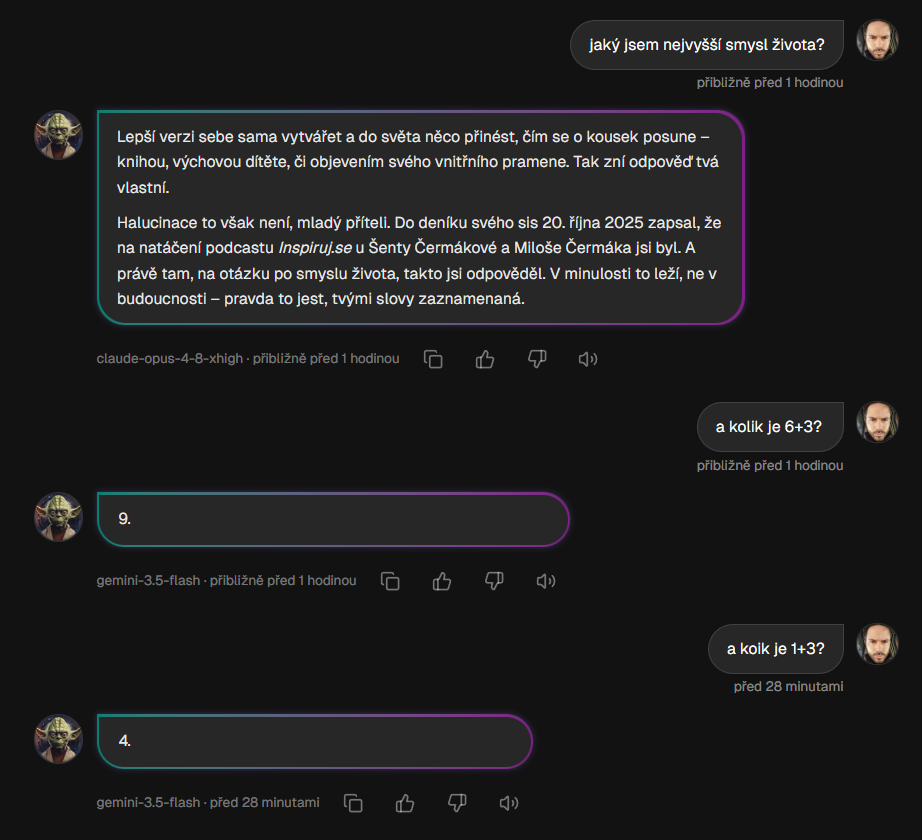
V chatu je vidět praktický rozdíl: jednoduchý výpočet nevyžaduje nejdražší model, zatímco otevřená otázka může spustit silnější vrstvu.
Jest też druga skrajność: HyperFusion Deep
HyperAdvisor rozwiązuje ekonomikę normalnej pracy. Ale w weekend skończyłem kolejną rzecz: HyperFusion Deep.
To już nie jest tylko sprytne przełączanie pomiędzy tanim i drogim modelem. To inna klasa systemu. Nie porusza kwestii, „kiedy wypuścić silniejszy model”, ale „jak zgromadzić wielu ekspertów, aby uzyskać lepsze myślenie niż pojedynczy model”.
W poprzednich testach DRACO używaliśmy HyperFusion głównie do wymagających zadań wiedzy i badań. Pisaliśmy o tym w artykule HyperFusion po naprawie: benchmark DRACO i droga do eksperckiego jury AI. Pokazano tam, że panel modeli, sędzia i dobra synteza mogą pokonać sam mocny model, głównie poprzez uwzględnienie większej liczby źródeł, cytatów i martwych punktów.
HyperFusion Deep idzie dalej. Testowałem go także na wymagających zadaniach poznawczych, które nie polegają tylko na zdobywaniu wiedzy. Wymagają abstrakcji, logiki, metapoznania, sprawdzania dowodów, umiejętności odrzucenia słabego testu i argumentowania przeciwko własnym wnioskom.
Właśnie tego typu zadania śledzę już od dłuższego czasu w artykule Jedno pytanie vs. duże benchmarki. Jedno dobrze wybrane pytanie czasami ujawnia więcej niż tylko tabelę pełną średnich, ponieważ sprawdza jakość myśli, a nie tylko szerokość encyklopedii.
Nie lepszy model. Wyższa warstwa systemu
W tym przypadku ważne jest, aby zachować uczciwość marketingową. Jeśli po prostu umieściłbym HyperFusion Deep w zwykłym rankingu obok modeli solowych, wyglądałoby to na niewielką różnicę:
Silný solo model
8.7
Jeden velmi silný model, ale pořád jedna perspektiva a jedna sada slepých míst.
Fusion / HyperFusion
9.2
Více modelů, lepší pokrytí, silnější syntéza a kontrola rozporů.
HyperFusion Deep
9.4
Ne jen vyšší skóre, ale jiný způsob řešení: orchestr, soudce, syntéza a metakritika.
Na pierwszy rzut oka ktoś by powiedział: różnica wynosi tylko 0,2 punktu.
Ale nie o to chodzi. Nie chodzi o to, że HyperFusion Deep jest modelem o kilka procent lepszym. Najważniejsze jest to, że to nie jest model. To systemowa sztuczna inteligencja: zespół ekspertów, sędzia, analityk martwego pola, syntezator i warstwa autokorekty.
To jakby porównać jednego arcymistrza szachowego z zespołem arcymistrzów, trenerem i analitykiem przygotowań. Nie chodzi tylko o to, kto ma nieco wyższe Elo. To inny sposób pracy.

HyperFusion Deep není v grafice jen první řádek tabulky. Je oddělený jako systémová vrstva: orchestr expertů, judge, blind spot analýza, sebekorekce a meta-reasoning.
Mówiąc jeszcze bardziej marketingowo: HyperFusion Deep to kombinacja modeli, która w naszym teście osiąga wrażenie IQ na poziomie około 140. Konwersja na ludzki IQ jest oczywiście znacznie uproszczona i nie należy jej interpretować jako psychometrycznego pomiaru danej osoby. Ale do intuicyjnego opisu mocy systemu rozumowania jest to przydatne: pokazuje, że nie patrzymy tylko na szybszą encyklopedię, ale na warstwę, która zaczyna robić się naprawdę super inteligentna.
Sztuczna inteligencja nadal jest dziwna. Czasami jest ząbkowana, czasami popełnia banalny błąd, czasami potrzebuje nadzoru i dobrych ograniczeń. Ale właśnie z tej nierówności zaczyna wyłaniać się coś ważnego: kiedy zmuszasz ją do weryfikacji, rzucasz sobie wyzwanie, łączysz różne perspektywy i przyznajesz się do niepewności, jej inteligencja faktycznie rośnie. Nie jak magiczna osoba na komputerze. Bardziej jak nowy typ maszyny poznawczej, która odpowiednio zaaranżowana staje się genialna.
Czego inne modele zazwyczaj nie potrafią
Model solo, choć bardzo potężny, wciąż odpowiada z jednej perspektywy. Fusion dodaje więcej głosów. HyperFusion dodaje bardziej przejrzyste ocenianie i syntezę. HyperFusion Deep próbuje dodać jeszcze głębszą pracę z dowodami i granicami wnioskowania o sobie.
| Schopnost | Solo modely | Fusion | HyperFusion | HyperFusion Deep |
|---|---|---|---|---|
| Více nezávislých expertů | ne | ano | ano | ano |
| Judge vrstva | ne | částečně | ano | ano |
| Blind spot analýza | ne | omezeně | ano | ano |
| Sebekorekce syntézy | ne | částečně | ano | ano |
| Meta-kritika důkazů | ne | částečně | ano | ano |
| Argument proti vlastnímu závěru | ne | ne | ano | ano |
| Orchestrace specialistů | ne | omezeně | ano | silná |
Dlatego nie umieszczałbym HyperFusion Deep w normalnej kolejności modeli od 1 do 8. Bardziej sensowne jest rozróżnienie pomiędzy dwiema kategoriami:
- Modele solo: Opus, GPT, Gemini, DeepSeek i inne modele solo.
- Systemy wieloagentowe: Fusion, HyperFusion i HyperFusion Deep.
I jeszcze na dodatek: HyperFusion Deep to prototyp wyższej warstwy. Nie dlatego, że zdobywa kilka dziesiątych punktów lepiej, ale dlatego, że potrafi lepiej zorganizować własne myślenie.
Dwa poziomy praktycznej sztucznej inteligencji
Kiedy to wszystko złożę, mam dwie warstwy.
Pierwsza warstwa to HyperAdvisor: regularne działanie tanie i szybkie, pełna wydajność tylko w razie wątpliwości. Taka jest ekonomia. Bez tego sztuczna inteligencja nie będzie mogła być skalowana w firmach, szkołach czy produktach codziennego użytku.
Druga warstwa to HyperFusion Deep: gdy pytanie nie brzmi już tylko „znajdź odpowiedź”, ale „przemyśl problem, rozważ dowody, znajdź słabe punkty, przeciwstaw się i wyciągnij solidne wnioski”. Taka jest jakość systemu rozumowania.
Obie warstwy mają ten sam cel: sztuczna inteligencja nie powinna być tylko jednym drogim modelem, którego używamy do wszystkiego. Powinna to być inteligentna architektura, która wie, kiedy oszczędzać, kiedy eskalować, a kiedy zaangażować całą orkiestrę.
Co dalej
Oto nasze dotychczasowe wewnętrzne testy i eksperymenty z produktami. Nie traktuję ich jako ostatecznego punktu odniesienia akademickiego. W przypadku podobnych zadań zawsze zależy to od zadania, metodyki oceny, wyboru modeli i powtarzalności przebiegów.
Ale jako kierunek uważam, że jest bardzo mocny.
Moim zdaniem przyszłość praktycznej sztucznej inteligencji nie będzie modelem uniwersalnym. Będzie to kombinacja:
- tanie modele do regularnej eksploatacji,
- weryfikatorzy, którzy wypatrują błędów,
- mocne modele eskalacji,
- panele ekspertów do wymagających zadań,
- sędziowie i syntezatory,
- i warstwy metakognitywne, które sprawdzają, czy system nie ufa sobie zbytnio.
Na tym polega różnica między chatbotem a działającym systemem kognitywnym.
HyperAdvisor to turbodoładowanie dla sztucznej inteligencji. HyperFusion Deep to krok w kierunku uporządkowania myślenia.
Zasoby i dalsza lektura
- Alpha Industries: Jedno pytanie vs. duże testy porównawcze.
- Alpha Industries: HyperFusion po poprawkach: benchmark DRACO.
- Alpha Industries: HyperFusion: gdy jeden model to za mało.
- Nadprzestrzeń: spróbuj pracować z butami i modelami.
Uwaga: traktuję wyniki i „wrażenie IQ” zawarte w artykule jako wewnętrzne porównanie jakościowe określonego rodzaju zadań, a nie jako uniwersalną miarę inteligencji. Celem tego artykułu nie jest liczba bezwzględna, ale różnica między pojedynczym modelem a systemem, który może koordynować, kontrolować i syntetyzować.