Jedno pytanie kontra dziesięć dużych testów porównawczych: jak dobrze wypadł mini test IQ?
Kilka dni temu zadałem najnowszym modelom sztucznej inteligencji tylko jedno pytanie – nie był to punkt odniesienia, ani tablica wyników, tylko pojedyncza pułapka intelektualna. Po kilku dniach przychodzi czas na porównanie wyniku z dużymi publicznymi benchmarkami, które pojawiły się w międzyczasie. Prowadzi GPT-5.5, tuż za nim Claude Opus 4.7, największym odchyleniem jest Gemini 3.1 Pro, najniższym DeepSeek V4 Pro. Pytanie, które warto zadać każdemu modelowi – zanim zaczniesz mu ufać.

Kilka dni temu podjąłem mały eksperyment: zadałem najnowszym modelom AI tylko jedno pytanie.
Nie jest to punkt odniesienia dla setek miejsc pracy. Nie w protokole. Tylko jedna intelektualna pułapka.
Model miał wyprowadzić reguły sztucznej funkcjimepidap, obliczyć nowy przypadek, przyznać niejednoznaczność, zaprojektować najlepszy test, który mógłby obalić jego hipotezę i powiedzieć co do czego jest najmniej pewny.
Nie chodziło o to, żeby „mierzyć IQ” w sensie psychologicznym, czy też pokazać, że klasyczne benchmarki są bezużyteczne.
Gdybym miał zadać modelowi tylko jedno pytanie, które najlepiej ujawnia jego analityczne myślenie, metapoznanie i pracę w niepewności – jakie by ono było?
Ponad 50 tys. osób obejrzało ten film, ale z komentarzy wynika, że wiele osób nie dostrzegło sedna. Po kilku dniach interesujące jest porównanie wyniku z dużymi publicznymi benchmarkami, które pojawiły się pomiędzy nimi.
📎 Jeśli nie czytałeś oryginalnego artykułu, znajdziesz go tutaj: Jedno pytanie zamiast dziesięciu benchmarków: mini test IQ dla najnowszych modeli AI
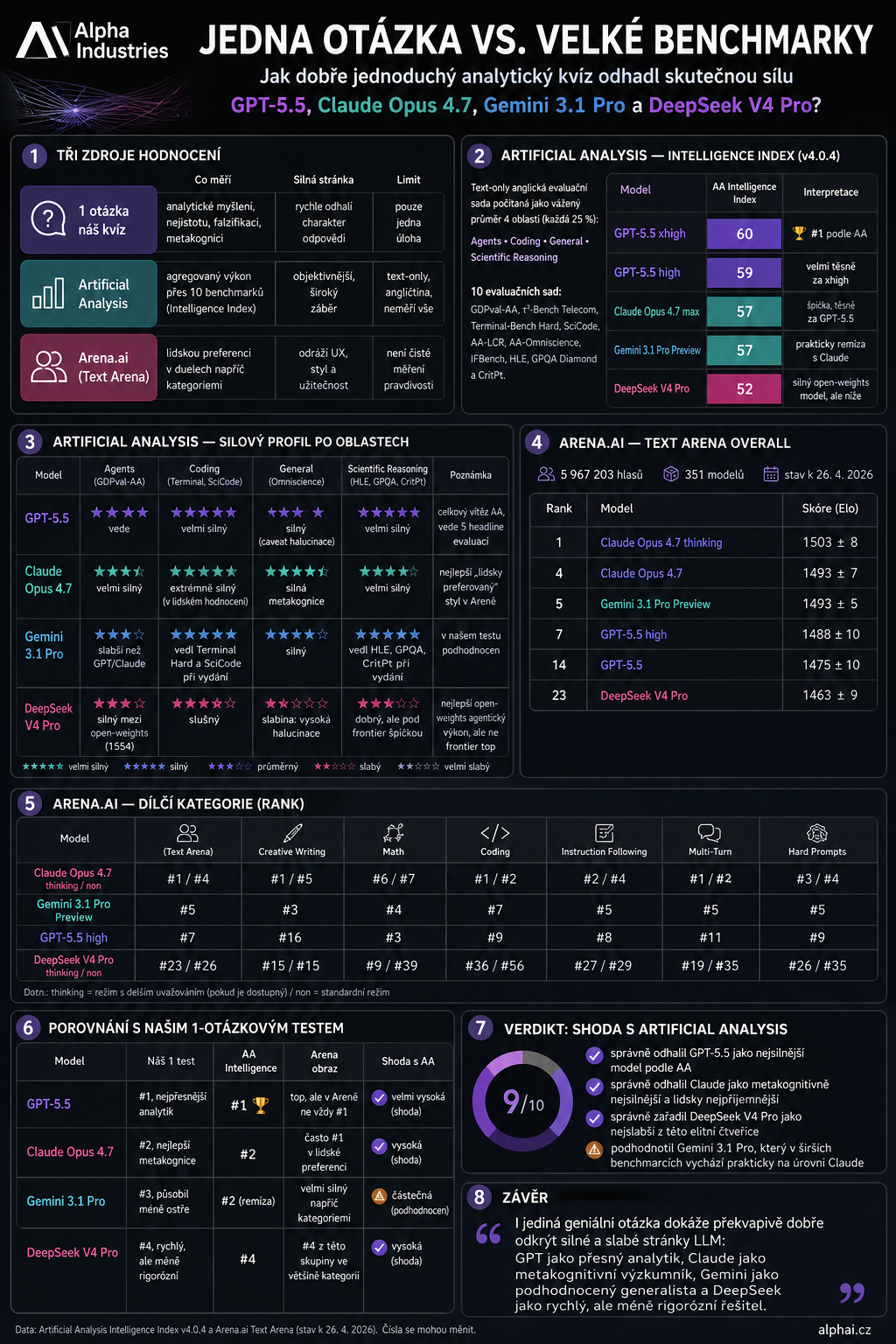
Jak sztuczna analiza mierzy „inteligencję”
Indeks inteligencji sztucznej analizy obecnie oblicza inteligencję modeli jako średnią ważoną czterech obszarów:
- Agenci — 25%
- Kodowanie — 25%
- Ogólne — 25%
- Rozumowanie naukowe — 25%
W sumie istnieje 10 pakietów ewaluacyjnych: PKBval-AA, τ²-Bench Telecom, Terminal-Bench Hard, SciCode, AA-LCR, AA-Omniscience, IFBench, Humanity's Last Exam, GPQA Diamond i CritPt.
Warto dodać, że jest to zestaw ewaluacyjny tylko tekstowy w języku angielskim, więc nie mierzy wszystkiego — nie mierzy np. języka czeskiego, multimodalności, głosu czy rzeczywistej użyteczności UX.
I jak to się skończyło?
🥇 GPT-5.5 — najbardziej wiarygodny analityk
Według sztucznej analizy GPT-5.5 jest obecnie na szczycie. GPT-5.5 xhigh ma indeks inteligencji 60, GPT-5.5 high 59.
To całkiem dobrze pasuje do mojego testu z jednym pytaniem, w którym okazał się najbardziej pewnym analitykiem: dokładnym, zwartym, matematycznie bystrym.
🥈 Claude Opus 4.7 — badacz z metapoznaniem
Claude Opus 4.7 ma 57 według sztucznej analizy, tuż za GPT-5.5. Ale w ocenie człowieka często jest ona nawet wyższa — w Text Arena Ogólnie Claude Opus 4.7 myślenie jest nawet pierwsze.
To właśnie jest ta interesująca różnica: GPT wydaje się być bardzo dokładnym „strzelcem matematycznym”, Claude jak badacz z lepszą metapoznaniem, ostrożnością i formułowaniem niepewności.
🥉 Gemini 3.1 Pro — niespodzianka w szerszych benchmarkach
Gemini 3.1 Pro był największym odchyleniem w moim teście składającym się z jednego pytania. W tej konkretnej roli wydawał się mniej bystry, w mniejszym stopniu traktował najważniejsze kwestie i gorzej radził sobie z niejednoznacznością.
Ale szersze benchmarki stawiają go znacznie wyżej: Sztuczna Analiza daje 57, czyli praktycznie na poziomie Claude Opus 4.7. Jest także bardzo dobry na Arenie — na przykład jest blisko szczytu w kreatywnym pisaniu, matematyce, kodowaniu i trudnych podpowiedziach.
4. DeepSeek V4 Pro — potężny, ale nie nowatorski
DeepSeek V4 Pro uzyskał w moim teście najniższy wynik z czterech — szybki, ostry, zdolny do rozpoznawania wzorców, ale mniej rygorystyczny pod względem dokładności, testowania i pracy z niepewnością.
Według benchmarków zostało to najbardziej potwierdzone. Sztuczna Analiza daje mu 52, czyli poniżej GPT-5.5, Claude i Gemini. Jednocześnie trzeba zaznaczyć, że to nie jest to „model głupi” — wręcz przeciwnie, to bardzo mocny model otwartej wagi, tyle że nie plasujący się w czołówce tej elitarnej grupy.
Jak dobrze trafiło to jedno pytanie?
zaskakująco dobrze moim zdaniem.
Tęskniła głównie za tym, jak bardzo nie doceniła Bliźniąt**. Ale uderzyła w główną konstrukcję:
- GPT-5.5 i Claude są na najwyższym poziomie.
- DeepSeek V4 Pro jest najgorszy z całej czwórki.
- Różnica między modelami polega nie tylko na tym, czy obliczą wynik, ale czy potrafią dopuścić do niepewności, poszukać kontrprzykładu i nie pomylić eleganckiego przypuszczenia z dowodem.
I taki był właśnie cel.
Nie mówiłem o „nowym benchmarku”. Dla mnie był to papierek lakmusowy inteligencji: jedno pytanie, które zmusi model do pokazania nie tylko obliczeń, ale także sposobu myślenia.
A oto coś całkiem zachęcającego:
Jedno dobrze zaprojektowane pytanie nie zastąpi testów porównawczych. Ale potrafi zaskakująco dobrze ujawnić charakter modelki.
Widok szczegółowy — Indeks inteligencji na dzień 29.04.2026
Tutaj możesz zobaczyć modele bardziej szczegółowo — pełny podział Indeksu Inteligencji wśród głównych dostawców (stan na 29.04.2026):
Który model zapewnia obecnie najlepsze rezultaty? Wolisz Team GPT czy Team Claude? Daj mi znać w komentarzach!
#UmeleIntelligence #LLM #ChatGPT #Claude #TechTrendy #Alphai