HyperFusion after patching: DRACO benchmark and the road to the AI expert jury
We ran HyperFusion through the more accurate DRACO benchmark. It turned out that it is not enough to put several models next to each other. What matters is how their answers fit together.

A few days ago I wrote an article HyperFusion: when one model is not enough. It was a text about why it makes sense to me not to talk to one model, but to a whole small panel of models. One will bring accuracy, the second a different point of view, the third will catch a blind spot. Above that sits a judge looking for similarities, contradictions and gaps. And the synthesizer will compose the final answer from it.
Since then, we have taken some features much further. And most importantly, we ran HyperFusion through a tougher benchmark that no longer tests just nice text, but specific coverage of requirements, citations, methods, and decisions.
The result is encouraging: HyperFusion hit 84.9% in the newer v3augment configuration, and in our DRACO run, Fusion beat even the best stand-alone model. But perhaps even more interesting is the journey that got there. Because in the beginning, HyperFusion didn't look like a winner at all.

Souhrn výsledků: žebříček systémů, skóre po úlohách, algoritmy syntézy a vztah cena vs kvalita.
Don't ask one expert, but the whole jury
When you ask a common chatbot today, one model answers. He may be very smart, but he still has his own style, his own blind spots and his own habits. HyperFusion works differently: it asks the same question to several models in parallel, lets them answer independently, and only then asks what can be inferred from their answers.
This has two advantages.
The first is diversity. One model finds the methodology, the second the legal detail, the third the practical risk. When everyone says the same thing, trust grows. When they differ, that is information in itself.
The second is transparency. I don't want a black box that just spits out an authoritative conclusion. I want to see what the panel said, where they agreed, where they disagreed, and why the synthesizer chose that answer.
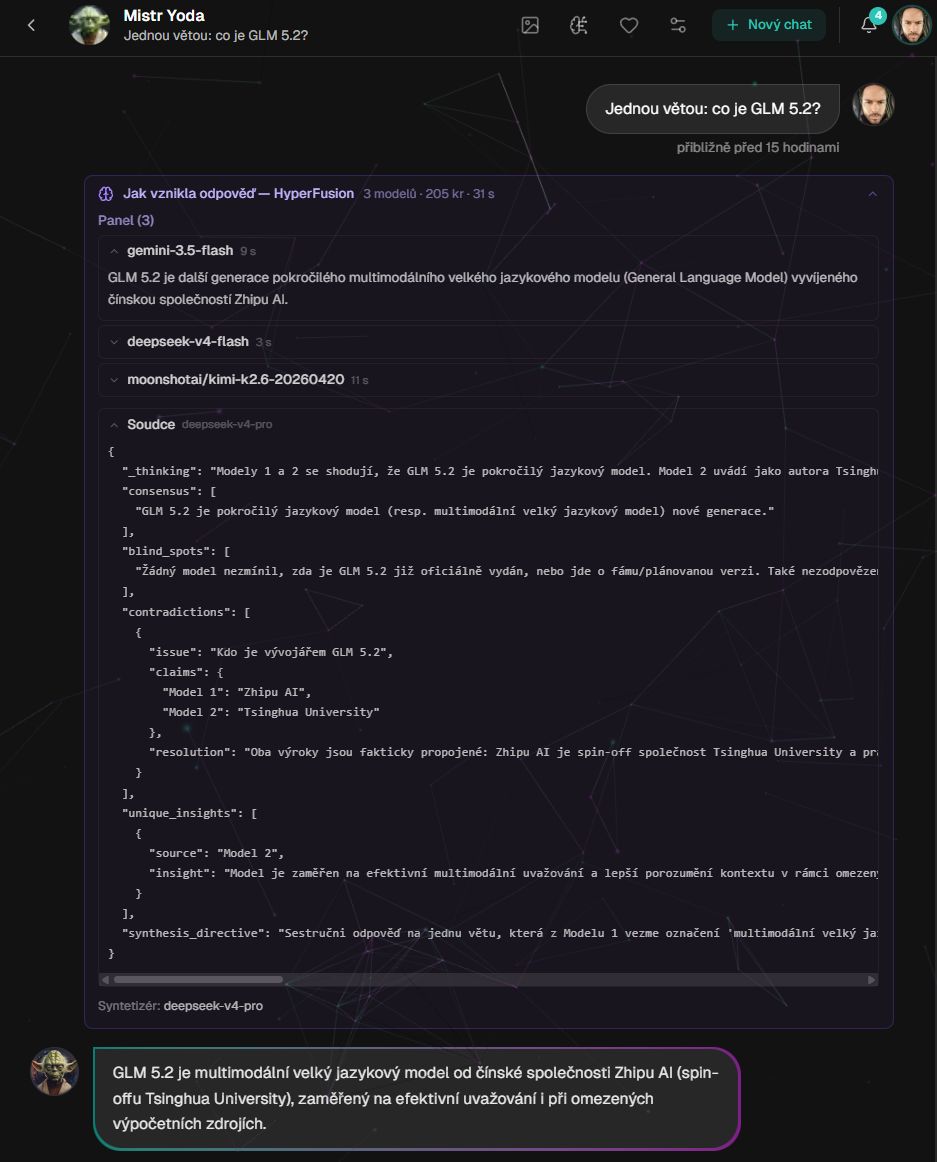
Glass-box přímo v chatu: odpovědi jednotlivých modelů, JSON analýza soudce a finální syntéza. Ne jen výsledek, ale i cesta k němu.
How we tested: DRACO
For a more accurate test, we used DRACO (perplexity-ai/draco), a set of demanding deep-research tasks. These are not simple "who was president" questions. They are assignments where research, citations, methodological caution and the ability to cover several sub-criteria at once must be combined.
In our run, there were five tasks: from deepfake detection to technical and medical questions to more complex research problems. Each answer was evaluated not only by impression, but by specific criteria: did the system mention the correct method, cite a relevant source, cover the ethical dimension, notice a regulatory detail, did it not miss an important exception?
We used Claude Opus 4.8 as an evaluation judge. We compared:
Samostatné modely
solo
Sonnet, Gemini a další modely běžící samy za sebe.
Fusion
80,9 %
Silný konkurenční přístup, ale méně průhledný pro ladění.
HyperFusion v3augment
84,9 %
Nejvyšší skóre v našem běhu a nejlepší syntéza bez ztráty klíčových bodů.
It is fair to add an important note: a single benchmark run is not a definitive scientific verdict. For similar tasks, the score naturally fluctuates. I therefore take it as a strong experimental signal, not the final word. But that's why it's interesting.
What went wrong at first?
The first version of HyperFusion was not a winner. It was expensive, sometimes slow, and worse than Fusion at some tasks.
The biggest problem wasn't that the panel of models couldn't find good answers. The problem was what happened next. The synthesizer sometimes took a very good response from one model and destroyed it in an attempt to "do its own summary". In one of the tests, she had the best partial answer of almost 89%, but the final synthesis dropped to a fraction of the quality because she transcribed a long, specific answer into a too-short abstract.
This is exactly the type of error that is hard to see in regular chat. The user sees a nice final paragraph. But they don't see that there was already a much better answer inside the system that the final step damaged.
This is where the value of the glass-box approach became apparent. When you see the panel responses, the judge's analysis, and the final synthesis, you can debug the system like a real product, not a magic prompt.
Breakthrough: there is no single best synthesis
The most important finding sounds trite, but is technically crucial: each task requires a different way of composing answers.
For analytical tasks, it really pays to merge the answers together. Model A has a frame, model B contrast, model C better structure. There it makes sense to synthesize from scratch.
It's different for search tasks. When one model finds the complete answer and others add only a few unique details, it is dangerous to start writing from scratch. Citations, exceptions, lists, and specific wording are easily lost.
That's why we deployed the v3augment strategy: take the best answer, keep it as whole as possible and only add unique points from other models. Don't overwrite the winner to make the output look "new". Improve him.
That was a leap.
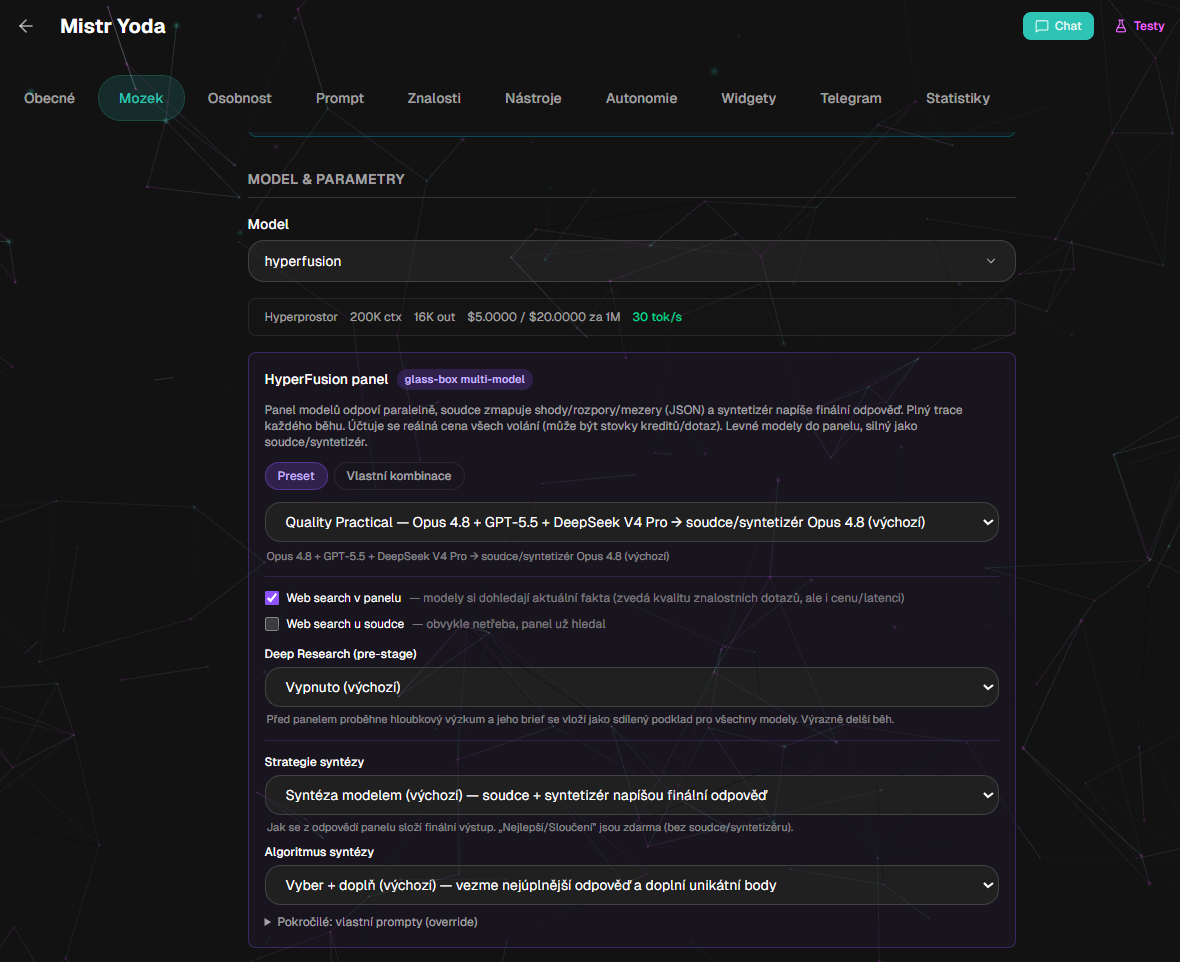
Nastavení přímo u bota: preset nebo vlastní kombinace modelů, strategie syntézy, web search, Deep Research a volba soudce či syntetizéru.
Performance vs price
The most interesting chart for me is not just the quality ranking. It's a performance vs price relationship.
On the one hand, you can turn on the premium configuration, which aims for the highest quality. On the other hand, it turned out that even the cheaper HyperFusion Budget can beat the best stand-alone model in our test: 70.0% vs 68.0% for the Sonnet, at about a week's worth.
This is perhaps the most practical conclusion of the whole experiment. A multi-model system doesn't have to be just an expensive toy. When put together well, it can offer a better price/vperformance ratio than a single powerful model.
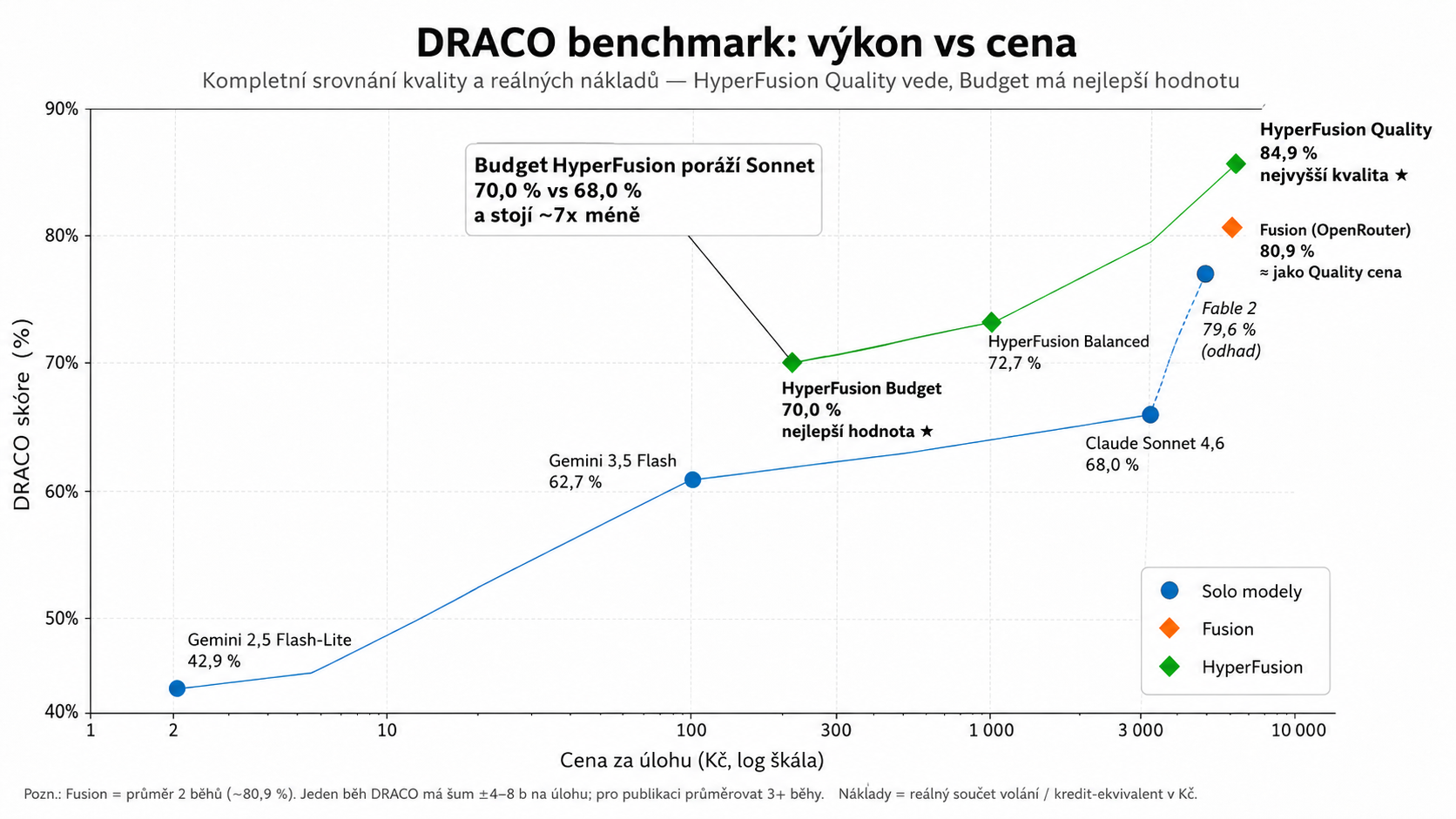
Modré body jsou samostatné modely, oranžová Fusion a zelená HyperFusion. Důležité je nejen nejvyšší skóre, ale i poloha vlevo nahoře: kvalita za rozumnou cenu.
What we accomplished
Compared to the first attempt, mainly three things have changed.
First, synthesis no longer destroys the best answer. V3augment does not compete with the panel winner, but builds on it.
Second, configuration is more open. It is possible to change the composition of the panel, the judge, the synthesizer, the synthesis strategy and whether to turn on web search or preliminary deep research.
Third, the measurement is more honest. We include the entire panel, judges and synthesis in the price, not just the final tokens. This is important because otherwise multi-model systems look cheaper than they really are.
This honesty sometimes hurts. The numbers are less pleasing. But without it, benchmarks turn into marketing.
Why I would like to test it together
Here I would like to take a step outside of our own experiment.
I wouldn't mind at all if we put together a smaller expert research group in the Czech Republic or cooperate with some association and do similar tests more properly: on a larger number of tasks, with more models, with repeated runs, with different evaluation judges and with an open sharing of experiences.
Not for someone to declare "the best model in the world". This is almost always a simplification.
Rather, to learn to answer more practical questions:
- Which model is good for the Czech legal or school context?
- When is a powerful model worth it and when is a cheaper panel?
- How much does web search help and when is it harmful?
- How to evaluate citations, uncertainty and blind spots?
- How to build a benchmark that doesn't just measure the smoothness of the text, but the actual usefulness?
This seems to me like work that we could easily do together in the Czech Republic. Not as a PR model competition, but as a shared methodology for people, companies, schools and institutions who want to use AI responsibly.
Conclusion
To me, HyperFusion is not just a trick to "ask more models". It's a direction to make AI a more controllable tool. Model panel, judge, synthesis, visible decision trail and ability to change strategy according to task type.
In my opinion, the future of AI will not be one all-knowing model. It will be a collaboration of models, tools, resources and human judgement. And the more important the answer becomes, the more we'll need to see not only what the AI said, but how it got there.
So far, HyperFusion in the DRACO benchmark has shown that this path makes sense. Now it would be nice to test it even more honestly, with a larger group, on more cases and with an open debate about what we actually expect from a good AI answer.
Resources and further reading
- Alpha Industries: HyperFusion: when one model isn't enough.
- DRACO benchmark:
perplexity-ai/draco. - Internal HyperFusion runs over five deep-research jobs; evaluation judge Claude Opus 4.8.
Note for fairness: results are based on a limited number of runs and there is natural variance in similar benchmarks. A definitive ranking would require multiple tasks, repeated runs, and multiple independent scoring methods.