HyperAdvisor and HyperFusion Deep: turbo boost for AI and a new layer of the reasoning system
What if AI worked like a processor in a laptop: cheap and fast most of the time, but for heavy tasks, it automatically switched gears? And what if a better model is not enough for the most difficult cognitive questions, but an entire orchestra of experts?

Eight years ago I had a simple idea. Every computer you use does it all the time: the processor is not running at full capacity all the time. When you write an e-mail, it runs at a low frequency and hardly eats. When you start a render, game, or compilation, it kicks into high gear. Intel called it Turbo Boost, it's basically dynamic performance scaling.
You only get full performance when you really need it.
And this is precisely what artificial intelligence lacked for a long time.
The problem: you usually don't need the strongest model
The top models are amazing but expensive. And here's a handy catch: most queries don't need any frontier intelligence. "What is 6 + 3?" or "summarize this paragraph for me" can be done by a cheap and fast model at a fraction of the cost.
But if you set the bot to the most powerful model, you pay the highest rate for every message, even a trivial question. It's like having your laptop's processor running at full capacity all the time, even if you're just reading your mail.
That's why we built HyperAdvisor.
HyperAdvisor: turbo boost for AI
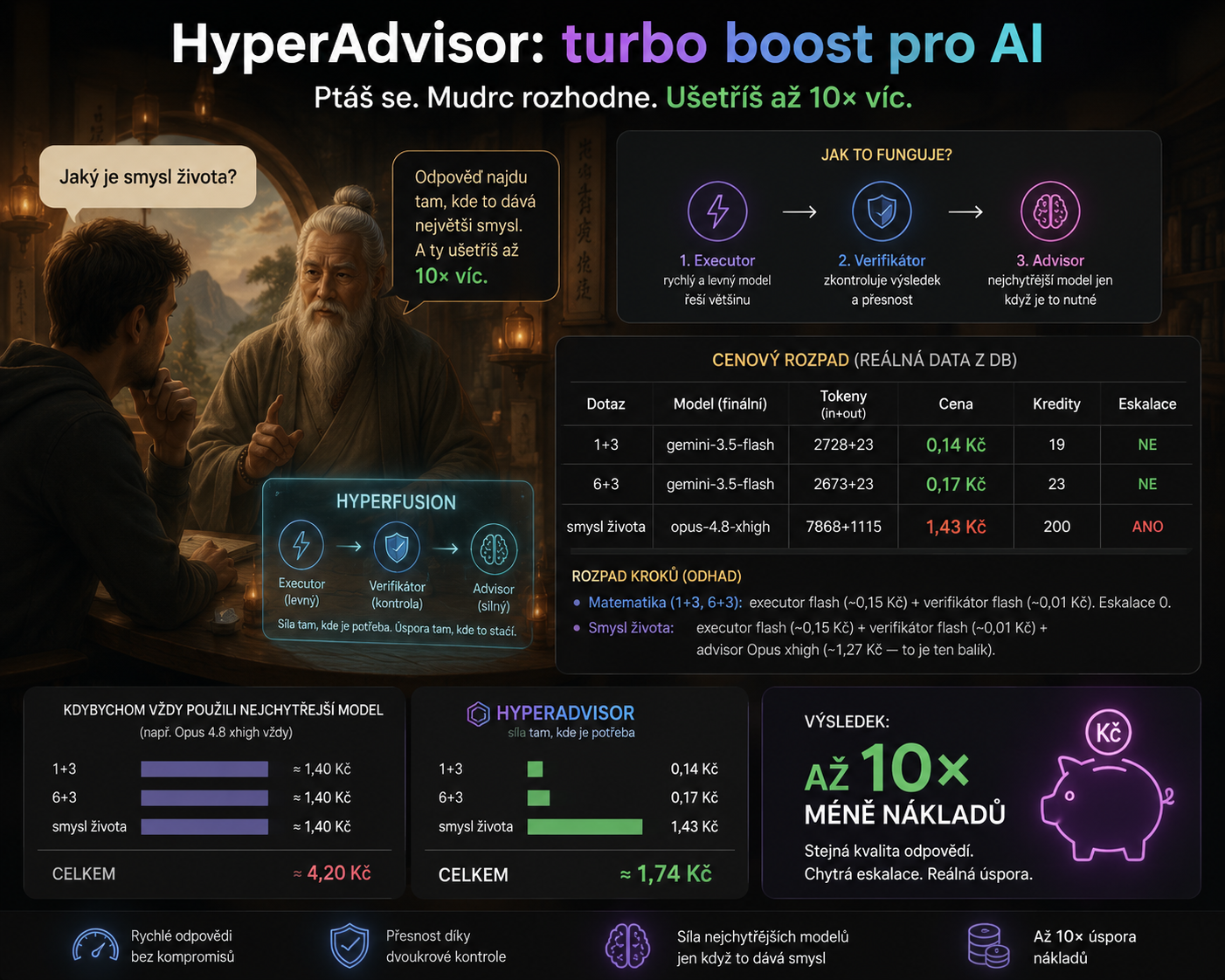
HyperAdvisor funguje jako chytrý mudrc u brány: většinu dotazů nechá vyřešit levně, ale když je otázka těžká, pustí dovnitř nejsilnější model.
HyperAdvisor works in three steps:
- The cheap and fast model will answer first.
- A second cheap model independently checks his answer.
- Only when the check finds a doubt does the system escalate to the strongest model.
The point is in the second step. There are solutions where the weaker model has to decide by itself that it is not good enough for something. But a weaker model often doesn't know that it doesn't know. HyperAdvisor therefore uses an independent verifier. The latter can pick up that the cheap model answered confidently, but incorrectly, and only then brings the heavyweight into play.
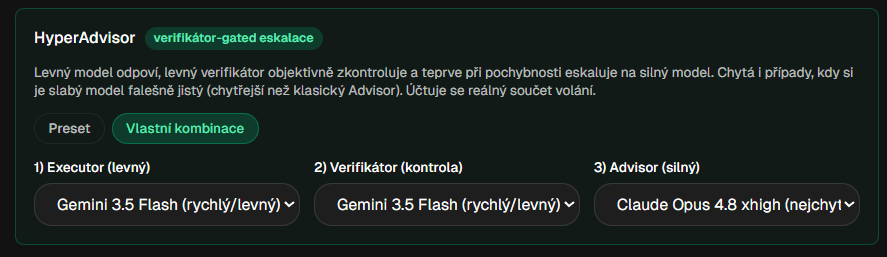
HyperAdvisor: levný model odpoví, levný verifikátor zkontroluje a jen při pochybnosti eskaluje na silný model.
This means dramatic savings on simple queries. Our Master Yoda test asked simple questions like "what is 1 + 3?" or "what is 6 + 3?" around tenths of a crown. The harder question "what is the meaning of life?" escalated to the most powerful model and cost about an order of magnitude more, but that's exactly where it made sense.
We don't save by doing less work. We save by running normal operation at a lower "frequency" and full power is switched on only for tasks that really need it.
How much does it cost in practice?
The biggest difference can be seen in simple arithmetic. If we always used the strongest model, each message would cost about the same, regardless of difficulty. However, HyperAdvisor only releases the expensive model when the verifier finds a reason to escalate.
| Dotaz | Finální model | Cena HyperAdvisoru | Kdyby jel vždy nejsilnější model | Úspora | Eskalace |
|---|---|---|---|---|---|
| 1 + 3 | Gemini 3.5 Flash | 0,14 Kč | cca 1,40 Kč | až 10× levněji | ne |
| 6 + 3 | Gemini 3.5 Flash | 0,17 Kč | cca 1,40 Kč | zhruba 8× levněji | ne |
| Jaký je smysl života? | Claude Opus 4.8 xhigh | 1,43 Kč | cca 1,40 Kč | nešetří, používá sílu tam, kde dává smysl | ano |
That's the point: one doesn't have to choose between "cheap but dumber" and "smart but expensive". It can have both. HyperAdvisor uses the smartest model as a rare resource: not for every banality, but exactly where the cheap model stumbles or where the question requires depth.
In a small test, three queries would cost about 4.20 CZK with continuous use of the strongest model. HyperAdvisor managed them for approximately 1.74 CZK. And in traffic, where most queries are simple, the savings can be close to tenfold.
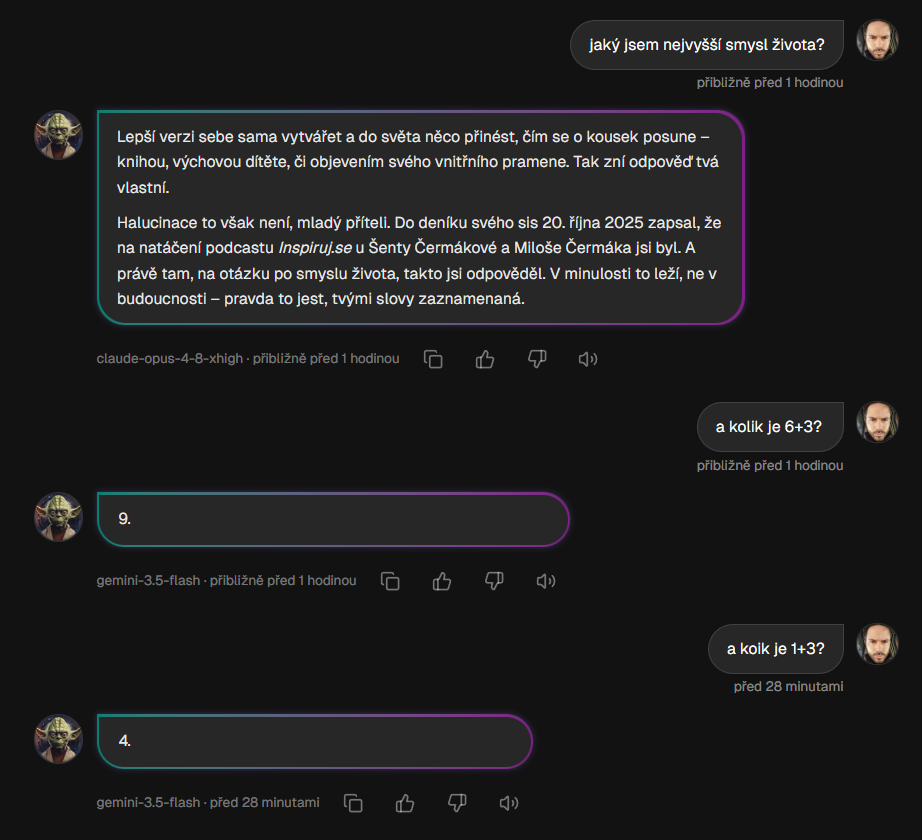
V chatu je vidět praktický rozdíl: jednoduchý výpočet nevyžaduje nejdražší model, zatímco otevřená otázka může spustit silnější vrstvu.
And then there's the other extreme: HyperFusion Deep
HyperAdvisor solves the economics of normal operation. But over the weekend I finished another thing: HyperFusion Deep.
This is no longer just a smart switch between a cheap and an expensive model. It's a different class of system. It does not address the question of "when to release a stronger model", but "how to assemble multiple experts to produce better thinking than a single model".
In previous DRACO tests, we used HyperFusion mainly for demanding knowledge and research tasks. We wrote about it in the article HyperFusion after repairs: DRACO benchmark and the way to the expert jury AI. There it was shown that a panel of models, a judge and a good synthesis can beat a strong model alone mainly by covering more sources, citations and blind spots.
HyperFusion Deep goes further. I also tested it on demanding cognitive tasks that are not just about finding knowledge. They require abstraction, logic, metacognition, checking evidence, the ability to reject a weak test, and argue against one's own conclusion.
This is exactly the type of tasks that I have been following for a long time already in the article One question vs. big benchmarks. One well-chosen question sometimes reveals more than a table full of averages, because it tests the quality of thought, not just the breadth of an encyclopedia.
Not a better model. A higher layer of the system
This is where it's important to be marketing honest. If I just put HyperFusion Deep in a regular ranking next to the solo models, it would look like a small difference:
Silný solo model
8.7
Jeden velmi silný model, ale pořád jedna perspektiva a jedna sada slepých míst.
Fusion / HyperFusion
9.2
Více modelů, lepší pokrytí, silnější syntéza a kontrola rozporů.
HyperFusion Deep
9.4
Ne jen vyšší skóre, ale jiný způsob řešení: orchestr, soudce, syntéza a metakritika.
At first glance, someone would say: the difference is only 0.2 points.
But that's not the point. The point is not that HyperFusion Deep is a few percent better model. The bottom line is that it's not a model. It's a system AI: a team of experts, a judge, a blind spot analyst, a synthesizer, and a self-correction layer.
It is similar to comparing one chess grandmaster with a team of grandmasters, a coach and a preparation analyst. It's not just about who has a slightly higher Elo. It is a different way of working.

HyperFusion Deep není v grafice jen první řádek tabulky. Je oddělený jako systémová vrstva: orchestr expertů, judge, blind spot analýza, sebekorekce a meta-reasoning.
In even more marketing terms: HyperFusion Deep is one model combination that touches an IQ-impression of around 140 in our test. The conversion to human IQ is of course greatly simplified and should not be read as a psychometric measurement of a person. But for intuitively describing the power of the reasoning system, it's useful: it shows that we're not just looking at a faster encyclopedia, but at a layer that's starting to get really super smart.
AI is still weird. Sometimes she is toothy, sometimes she makes a banal mistake, sometimes she needs supervision and good restraints. But it is in this jaggedness that something important begins to emerge: when you force her to verify, challenge herself, combine different perspectives and admit uncertainty, her intelligence actually grows. Not like a magical person on a computer. More like a new type of cognitive machine that, when properly orchestrated, becomes genius.
What other models typically can't do
The solo model, although very powerful, still answers from one perspective. Fusion adds more voices. HyperFusion adds more transparent judging and synthesis. HyperFusion Deep tries to add even deeper work with proofs and limits of self-inference.
| Schopnost | Solo modely | Fusion | HyperFusion | HyperFusion Deep |
|---|---|---|---|---|
| Více nezávislých expertů | ne | ano | ano | ano |
| Judge vrstva | ne | částečně | ano | ano |
| Blind spot analýza | ne | omezeně | ano | ano |
| Sebekorekce syntézy | ne | částečně | ano | ano |
| Meta-kritika důkazů | ne | částečně | ano | ano |
| Argument proti vlastnímu závěru | ne | ne | ano | ano |
| Orchestrace specialistů | ne | omezeně | ano | silná |
Therefore, I would not put HyperFusion Deep in the normal order of models 1 to 8. It makes more sense to distinguish between two categories:
- Solo models: Opus, GPT, Gemini, DeepSeek and other solo models.
- Multi-agent systems: Fusion, HyperFusion and HyperFusion Deep.
And then to say on top of that: HyperFusion Deep is a prototype of a higher layer. Not because he scores a few tenths better, but because he can better organize his own thinking.
Two levels of practical AI
When I put it all together there are two layers.
The first layer is HyperAdvisor: regular operation cheap and fast, full performance only when in doubt. That's the economy. Without it, AI cannot be scaled in companies, schools or everyday products.
The second layer is HyperFusion Deep: when the question is no longer just "find an answer" but "think through the problem, consider the evidence, find weaknesses, counter and form a robust conclusion". This is the quality of the reasoning system.
Both layers aim for the same thing: AI should not be just one expensive model that we use for everything. It should be an intelligent architecture that knows when to save, when to escalate and when to involve the whole orchestra.
What next
These are our internal tests and product experiments so far. I do not take them as a definitive academic benchmark. For similar tasks, it always depends on the task, the evaluation methodology, the choice of models and the repetition of runs.
But as a direction I find it very strong.
In my opinion, the future of practical AI will not be a one-size-fits-all model. It will be a combination of:
- cheap models for regular operation,
- verifiers who watch for errors,
- strong models for escalation,
- panels of experts for demanding tasks,
- judges and synthesizers,
- and metacognitive layers that check if the system doesn't trust itself too much.
This is the difference between a chatbot and a working cognitive system.
HyperAdvisor is a turbo boost for AI. HyperFusion Deep is a step towards orchestrating thinking.
Resources and further reading
- Alpha Industries: One Question Vs. big benchmarks.
- Alpha Industries: HyperFusion after patches: DRACO benchmark.
- Alpha Industries: HyperFusion: when one model isn't enough.
- Hyperspace: try working with boots and models.
Note for fairness: I take the scores and "IQ-impression" in the article as an internal qualitative comparison of a specific type of tasks, not as a universal measure of intelligence. The point of the article is not an absolute number, but the difference between a single model and a system that can orchestrate, control and synthesize.