Blog
Der älteste Blog über KI in Tschechien
Wir schreiben über künstliche Intelligenz seit 2017. 1000+ Artikel, Tausende von Seiten voller Gedanken, Experimente und Reflexionen. Ohne Sensationen, ohne Werbung.
Tag-Filter: BERT × abbrechen
▸Nach Themen durchsuchen
Themen
Angezeigt 7 von 7 Artikeln
 Archiv 2021
Archiv 2021Neuer Champion auf der Bühne?
Das Sprachmodell Switch Transformer von Google ist fast sechsmal größer als GPT-3! Der Switch Transformer hat 9x mehr Parameter, also 1,6 Billionen. Google hat die…
Lesen Archiv 2021
Archiv 2021Rückblick auf das letzte Jahrzehnt
Man findet dort zwar nicht das Jahr 2020 oder GPT, aber insgesamt ist es sehr gelungen :) https://towardsdatascience.com/the-decade-of-artificial…
Lesen Archiv 2019
Archiv 2019Ergebnisse der KI wurden auf der NeurIPS-Konferenz untersucht. Was wurde erreicht?
Vor kurzem fand in Vancouver, Kanada, die Konferenz Neural Information Processing Systems (NeurIPS) statt, auf der sich mehr als 13.000 Wissenschaftler aus verschiedenen Bereichen versammelten….
Lesen Archiv 2019
Archiv 2019Ein weiterer Kurs abgeschlossen
Ich habe gerade den Kurs „Learn BERT – most powerful NLP algorithm by Google“ abgeschlossen. Es ist ein fortgeschrittener Kurs, der sowohl theoretisch als auch praktisch mit dem…
Lesen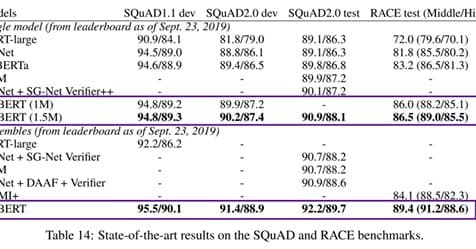 Archiv 2019
Archiv 2019Das neueste Modell der künstlichen Intelligenz zur Verarbeitung natürlicher Sprache – ALBERT!
Unter den besten Modellen der künstlichen Intelligenz zur Verarbeitung natürlicher Sprache (Bert, Robert, GPT-2 oder Megatron) ist letzte Woche ein weiterer Spieler aufgetaucht: ALBERT! ALBERT wird uns von den Unternehmen…
Lesen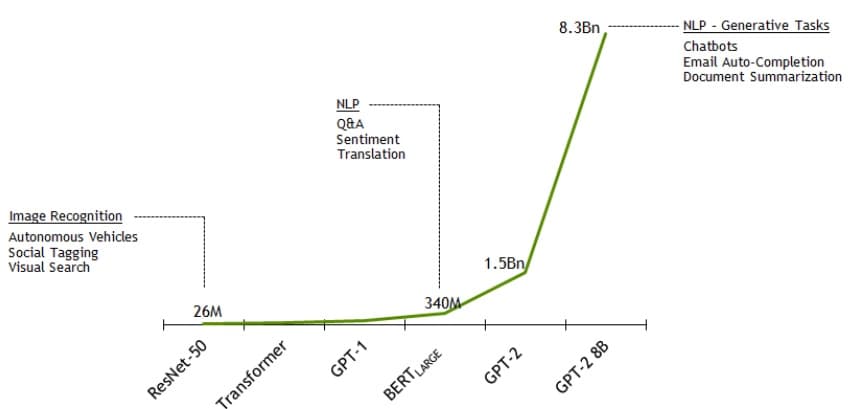 Archiv 2019
Archiv 2019Das Unternehmen Nvidia hat angekündigt, dass es das größte Sprachmodell der Welt, GPT-2 8B, trainiert hat!
Das Modell verwendet 8,3 Milliarden Parameter und ist 24-mal größer als BERT und 5-mal größer als das bisher größte GPT-2 von OpenAI. Nvidia hat Parallelität genutzt, die…
Lesen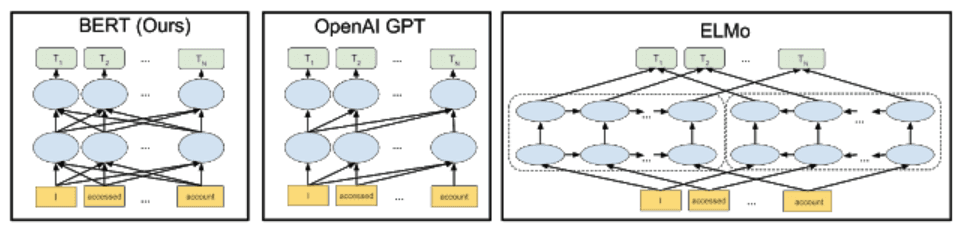 Archiv 2018
Archiv 2018Das Unternehmen Google hat diese Woche sein neuestes technologisches Spielzeug veröffentlicht – Bidirectional Encoder Representations Transformers, kurz BERT
Inwiefern unterscheidet sich BERT von klassischen NLP-Modellen wie word2vec und GloVe? Word2vec und andere Modelle erzeugen kontextfreie Wortdarstellungen. Jedes Wort…
Lesen