Das Unternehmen Nvidia hat angekündigt, dass es das größte Sprachmodell der Welt, GPT-2 8B, trainiert hat!
Das Modell verwendet 8,3 Milliarden Parameter und ist 24-mal größer als BERT und 5-mal größer als das bisher größte GPT-2 von OpenAI. Nvidia hat Parallelität genutzt, die…
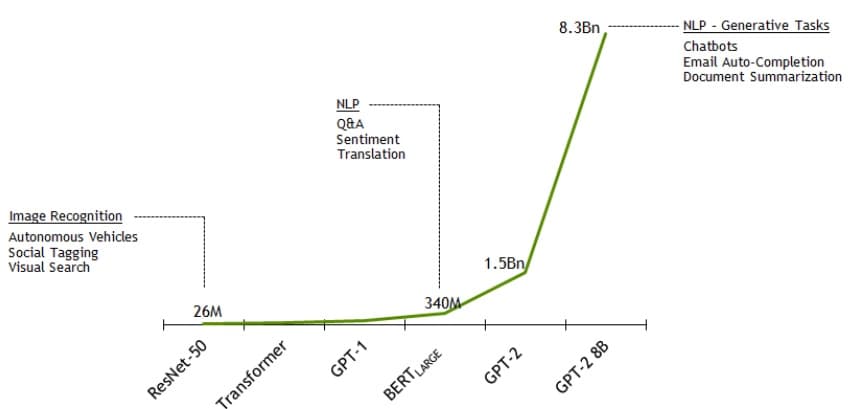
Das Modell verwendet 8,3 Milliarden Parameter und ist 24-mal größer als BERT und 5-mal größer als das bisher größte GPT-2 von OpenAI. Nvidia hat Parallelität genutzt, die das neuronale Netzwerk in Stücke aufgeteilt hat, die immer in den Speicher einer GPU passen.
Das Unternehmen Nvidia hat auch die schnellsten Trainingszeiten für das BERT-Modell bekannt gegeben. Das BERT-Large-Modell konnte mithilfe der optimierten Software PyTorch und des DGX-SuperPOD mit 1472 GPUs (V100) in rekordverdächtigen 53 Minuten trainiert werden! Diese Leistung haben wir zu Beginn dieses Jahres noch in Wochen gerechnet!
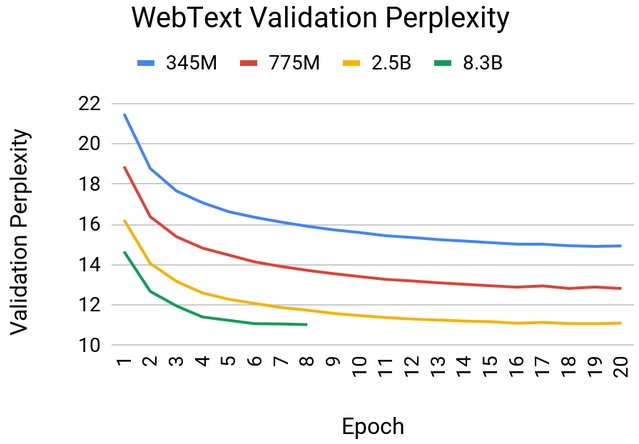
Quelle: https://devblogs.nvidia.com/training-bert-with-gpus/
Github: https://github.com/nvidia/megatron-lm
Původní zdroj: wordpress