HyperFusion nach dem Patchen: DRACO-Benchmark und der Weg zur KI-Expertenjury
Wir haben HyperFusion durch den genaueren DRACO-Benchmark laufen lassen. Es stellte sich heraus, dass es nicht ausreicht, mehrere Modelle nebeneinander zu platzieren. Entscheidend ist, wie ihre Antworten zusammenpassen.

Vor ein paar Tagen habe ich einen Artikel geschrieben HyperFusion: Wenn ein Modell nicht genug ist. Es war ein Text darüber, warum es für mich sinnvoll ist, nicht mit einem Model, sondern mit einer ganzen kleinen Gruppe von Models zu sprechen. Der eine wird Genauigkeit bringen, der zweite einen anderen Standpunkt, der dritte wird einen blinden Fleck erkennen. Darüber sitzt ein Richter, der nach Gemeinsamkeiten, Widersprüchen und Lücken sucht. Und der Synthesizer wird daraus die endgültige Antwort komponieren.
Seitdem haben wir einige Funktionen deutlich weiterentwickelt. Und am wichtigsten: Wir haben HyperFusion einem strengeren Benchmark unterzogen, der nicht mehr nur netten Text testet, sondern eine spezifische Abdeckung von Anforderungen, Zitaten, Methoden und Entscheidungen.
Das Ergebnis ist ermutigend: HyperFusion erreichte 84,9 % in der neueren v3augment-Konfiguration, und in unserem DRACO-Durchlauf schlug Fusion sogar das beste Standalone-Modell. Aber vielleicht noch interessanter ist die Reise, die dorthin führte. Denn am Anfang sah HyperFusion überhaupt nicht nach einem Gewinner aus.

Souhrn výsledků: žebříček systémů, skóre po úlohách, algoritmy syntézy a vztah cena vs kvalita.
Fragen Sie nicht einen Experten, sondern die gesamte Jury
Wenn Sie heute einen gewöhnlichen Chatbot fragen, antwortet ein Modell. Er mag sehr schlau sein, aber er hat dennoch seinen eigenen Stil, seine eigenen blinden Flecken und seine eigenen Gewohnheiten. HyperFusion funktioniert anders: Es stellt mehreren Modellen parallel dieselbe Frage, lässt sie unabhängig voneinander antworten und fragt erst dann, was sich aus ihren Antworten schließen lässt.
Dies hat zwei Vorteile.
Das erste ist Vielfalt. Ein Modell ermittelt die Methodik, das zweite die rechtlichen Details, das dritte das praktische Risiko. Wenn alle das Gleiche sagen, wächst das Vertrauen. Wenn sie sich unterscheiden, ist das eine Information an sich.
Das zweite ist Transparenz. Ich möchte keine Blackbox, die nur eine maßgebliche Schlussfolgerung ausspuckt. Ich möchte sehen, was das Gremium gesagt hat, wo es einer Meinung war, wo es anderer Meinung war und warum der Synthesizer diese Antwort gewählt hat.
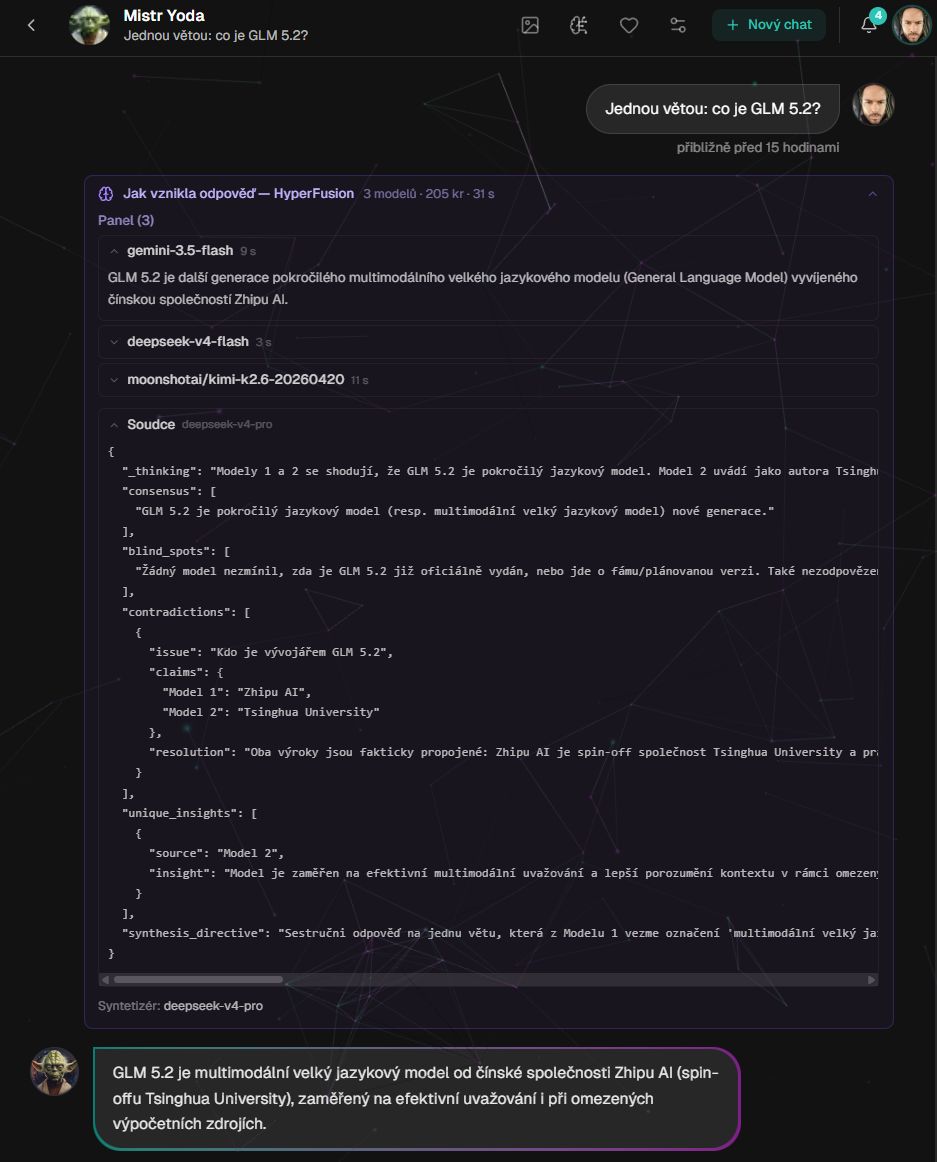
Glass-box přímo v chatu: odpovědi jednotlivých modelů, JSON analýza soudce a finální syntéza. Ne jen výsledek, ale i cesta k němu.
Wie wir getestet haben: DRACO
Für einen genaueren Test verwendeten wir DRACO (perplexity-ai/draco), eine Reihe anspruchsvoller, tiefgreifender Forschungsaufgaben. Dabei handelt es sich nicht um einfache „Wer war Präsident?“-Fragen. Es handelt sich um Aufgaben, bei denen Recherche, Zitationen, methodische Vorsicht und die Fähigkeit, mehrere Unterkriterien gleichzeitig abzudecken, kombiniert werden müssen.
In unserem Lauf gab es fünf Aufgaben: von der Deepfake-Erkennung über technische und medizinische Fragen bis hin zu komplexeren Forschungsproblemen. Jede Antwort wurde nicht nur nach dem Eindruck, sondern nach bestimmten Kriterien bewertet: Hat das System die richtige Methode erwähnt, eine relevante Quelle zitiert, die ethische Dimension abgedeckt, ein regulatorisches Detail bemerkt, ist nicht eine wichtige Ausnahme übersehen worden?
Als Bewertungsrichter haben wir Claude Opus 4.8 eingesetzt. Wir haben verglichen:
Samostatné modely
solo
Sonnet, Gemini a další modely běžící samy za sebe.
Fusion
80,9 %
Silný konkurenční přístup, ale méně průhledný pro ladění.
HyperFusion v3augment
84,9 %
Nejvyšší skóre v našem běhu a nejlepší syntéza bez ztráty klíčových bodů.
Es ist angebracht, einen wichtigen Hinweis hinzuzufügen: Ein einzelner Benchmark-Durchlauf ist kein endgültiges wissenschaftliches Urteil. Bei ähnlichen Aufgaben schwankt die Punktzahl naturgemäß. Ich halte es daher für ein starkes experimentelles Signal, nicht für das letzte Wort. Aber gerade deshalb ist es interessant.
Was ist zunächst schief gelaufen?
Die erste Version von HyperFusion war kein Gewinner. Es war teuer, manchmal langsam und bei manchen Aufgaben schlechter als Fusion.
Das größte Problem bestand nicht darin, dass die Modellgruppe keine guten Antworten finden konnte. Das Problem war, was als nächstes geschah. Der Synthesizer nahm manchmal eine sehr gute Reaktion eines Modells auf und zerstörte sie in dem Versuch, „eine eigene Zusammenfassung zu erstellen“. In einem der Tests hatte sie mit fast 89 % die beste Teilantwort, aber die endgültige Synthese verlor nur einen Bruchteil der Qualität, weil sie eine lange, spezifische Antwort in eine zu kurze Zusammenfassung transkribierte.
Dies ist genau die Art von Fehler, die im normalen Chat schwer zu erkennen ist. Der Benutzer sieht einen schönen letzten Absatz. Aber sie sehen nicht, dass es im System bereits eine bessere Lösung gab, die durch den letzten Schritt beschädigt wurde.
Hier zeigte sich der Wert des Glass-Box-Ansatzes. Wenn Sie die Antworten der Jury, die Analyse des Jurors und die endgültige Synthese sehen, können Sie das System wie ein echtes Produkt debuggen und nicht wie eine Zauberaufforderung.
Durchbruch: Es gibt keine einzelne beste Synthese
Die wichtigste Erkenntnis klingt abgedroschen, ist aber technisch entscheidend: Jede Aufgabe erfordert eine andere Art, Antworten zu verfassen.
Bei analytischen Aufgaben lohnt es sich, die Antworten zusammenzuführen. Modell A hat einen Rahmen, Modell B dagegen, Modell C eine bessere Struktur. Da macht es Sinn, von Grund auf zu synthetisieren.
Anders verhält es sich bei Suchaufgaben. Wenn ein Modell die vollständige Antwort findet und andere nur ein paar einzigartige Details hinzufügen, ist es gefährlich, von vorne zu beginnen. Zitate, Ausnahmen, Listen und spezifische Formulierungen gehen leicht verloren.
Aus diesem Grund haben wir die v3augment-Strategie eingesetzt: Nehmen Sie die beste Antwort, behalten Sie sie so vollständig wie möglich und fügen Sie nur einzigartige Punkte aus anderen Modellen hinzu. Überschreiben Sie den Gewinner nicht, damit die Ausgabe „neu“ aussieht. Verbessere ihn.
Das war ein Sprung.
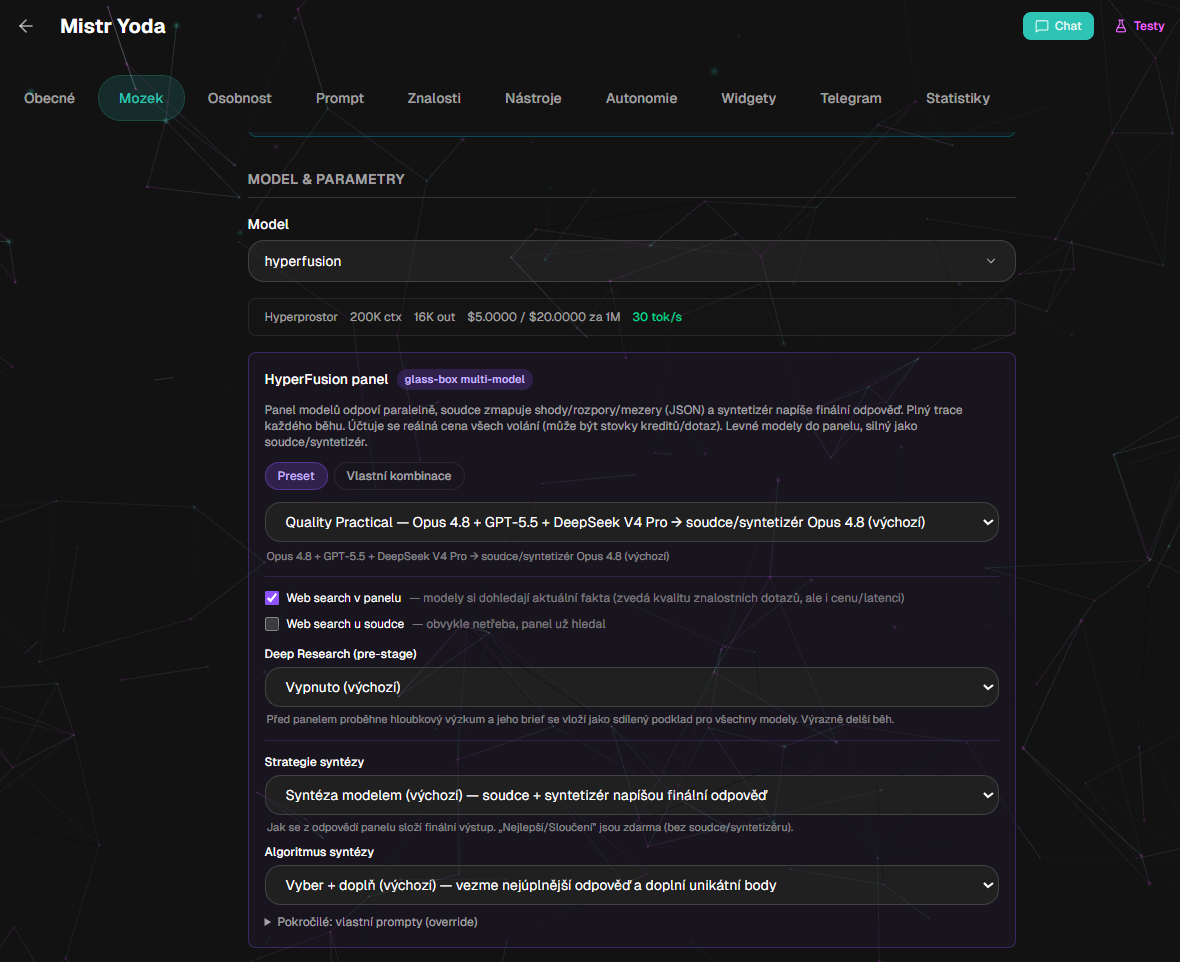
Nastavení přímo u bota: preset nebo vlastní kombinace modelů, strategie syntézy, web search, Deep Research a volba soudce či syntetizéru.
Leistung vs. Preis
Das für mich interessanteste Diagramm ist nicht nur das Qualitätsranking. Es ist ein Verhältnis zwischen Leistung und Preis.
Einerseits können Sie die Premium-Konfiguration aktivieren, die auf höchste Qualität abzielt. Andererseits stellte sich heraus, dass selbst das günstigere HyperFusion Budget das beste Stand-Alone-Modell in unserem Test schlagen kann: 70,0 % vs. 68,0 % für das Sonnet, also etwa eine Woche wert.
Dies ist vielleicht die praktischste Schlussfolgerung des gesamten Experiments. Ein Multimodellsystem muss nicht nur ein teures Spielzeug sein. Bei guter Zusammenstellung kann es ein besseres Preis-Leistungs-Verhältnis bieten als ein einzelnes leistungsstarkes Modell.
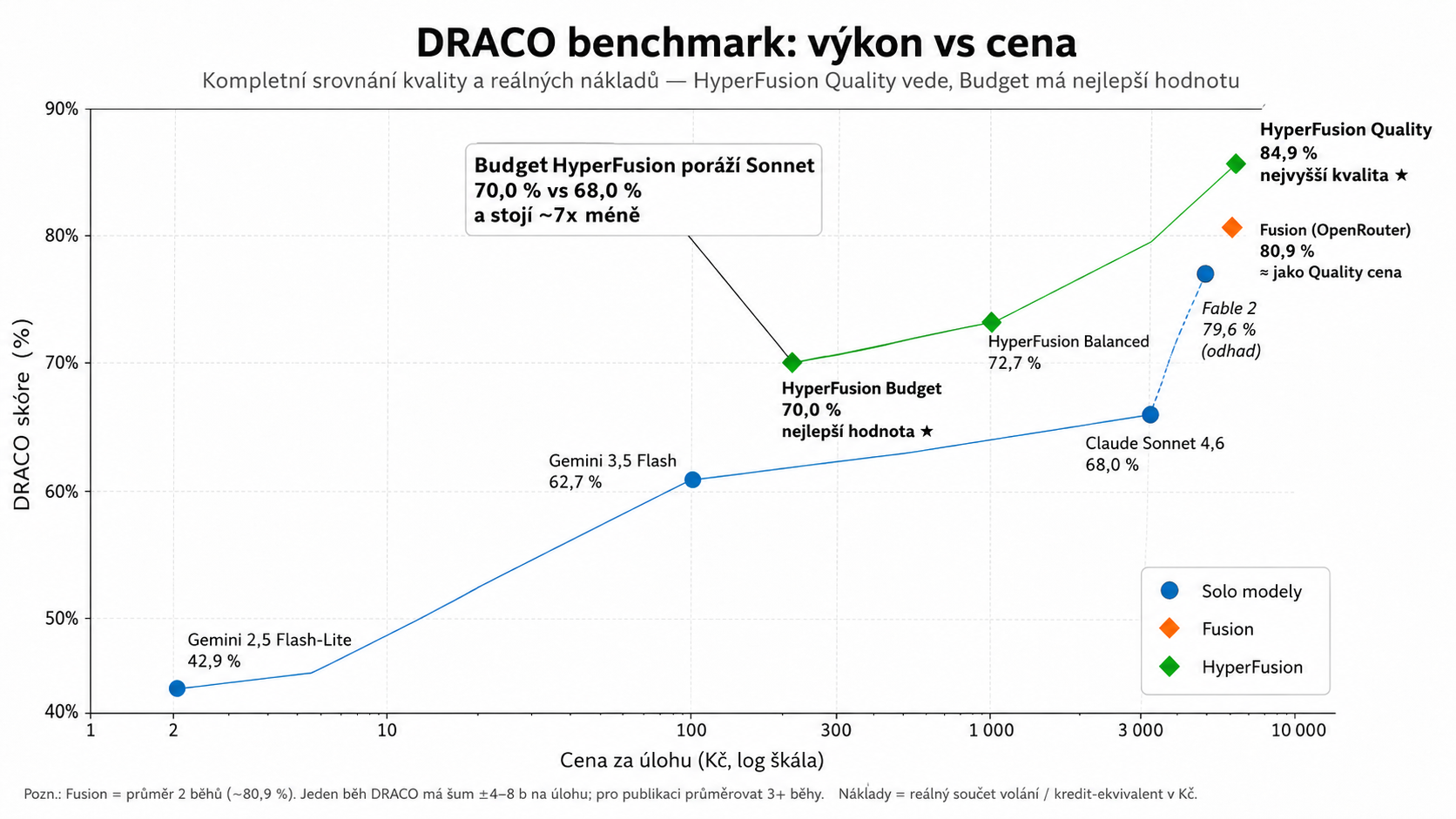
Modré body jsou samostatné modely, oranžová Fusion a zelená HyperFusion. Důležité je nejen nejvyšší skóre, ale i poloha vlevo nahoře: kvalita za rozumnou cenu.
Was wir erreicht haben
Im Vergleich zum ersten Versuch haben sich vor allem drei Dinge geändert.
Erstens zerstört die Synthese nicht mehr die beste Antwort. V3augment konkurriert nicht mit dem Panelsieger, sondern baut auf diesem auf.
Zweitens ist die Konfiguration offener. Es ist möglich, die Zusammensetzung des Gremiums, den Juror, den Synthesizer, die Synthesestrategie und die Aktivierung der Websuche oder der vorläufigen Tiefenrecherche zu ändern.
Drittens ist die Messung ehrlicher. Wir beziehen die gesamte Jury, die Jury und die Synthese in den Preis ein, nicht nur die endgültigen Token. Dies ist wichtig, da Mehrmodellsysteme sonst günstiger aussehen, als sie tatsächlich sind.
Diese Ehrlichkeit tut manchmal weh. Die Zahlen sind weniger erfreulich. Aber ohne sie verwandeln sich Benchmarks in Marketing.
Warum ich es gerne gemeinsam testen möchte
Hier möchte ich einen Schritt über unser eigenes Experiment hinausgehen.
Ich hätte überhaupt nichts dagegen, wenn wir in der Tschechischen Republik eine kleinere Expertenforschungsgruppe zusammenstellen oder mit einem Verein zusammenarbeiten und ähnliche Tests ordnungsgemäßer durchführen würden: an einer größeren Anzahl von Aufgaben, mit mehr Modellen, mit wiederholten Durchläufen, mit verschiedenen Bewertungsrichtern und mit einem offenen Erfahrungsaustausch.
Es steht niemandem zu, „das beste Modell der Welt“ zu erklären. Dabei handelt es sich fast immer um eine Vereinfachung.
Vielmehr lernen Sie, praktischere Fragen zu beantworten:
- Welches Modell eignet sich für den tschechischen Rechts- oder Schulkontext?
- Wann lohnt sich ein leistungsstarkes Modell und wann ein günstigeres Panel?
- Wie sehr hilft die Websuche und wann ist sie schädlich?
- Wie bewertet man Zitate, Unsicherheit und blinde Flecken?
- Wie erstellt man einen Benchmark, der nicht nur die Glätte des Textes, sondern auch den tatsächlichen Nutzen misst?
Das scheint mir eine Arbeit zu sein, die wir in der Tschechischen Republik problemlos gemeinsam machen könnten. Nicht als PR-Modellwettbewerb, sondern als gemeinsame Methodik für Menschen, Unternehmen, Schulen und Institutionen, die verantwortungsvoll mit KI umgehen wollen.
Fazit
Für mich ist HyperFusion nicht nur ein Trick, um „mehr Modelle zu befragen“. Es ist eine Richtung, KI zu einem besser kontrollierbaren Werkzeug zu machen. Modellgremium, Richter, Synthese, sichtbarer Entscheidungspfad und die Möglichkeit, die Strategie je nach Aufgabentyp zu ändern.
Meiner Meinung nach wird die Zukunft der KI kein allwissendes Modell sein. Es wird eine Zusammenarbeit von Modellen, Werkzeugen, Ressourcen und menschlichem Urteilsvermögen sein. Und je wichtiger die Antwort wird, desto mehr müssen wir nicht nur sehen, was die KI gesagt hat, sondern auch, wie sie dorthin gelangt ist.
Bisher hat HyperFusion im DRACO-Benchmark gezeigt, dass dieser Weg sinnvoll ist. Jetzt wäre es schön, es noch ehrlicher zu testen, mit einer größeren Gruppe, an mehr Fällen und mit einer offenen Debatte darüber, was wir eigentlich von einer guten KI-Antwort erwarten.
Ressourcen und weiterführende Literatur
- Alpha Industries: HyperFusion: Wenn ein Modell nicht ausreicht.
- DRACO-Benchmark:
perplexity-ai/draco. - Intern führt HyperFusion fünf tiefgreifende Forschungsaufgaben durch; Bewertungsrichter Claude Opus 4.8.
Hinweis zur Fairness: Die Ergebnisse basieren auf einer begrenzten Anzahl von Durchläufen und es gibt natürliche Abweichungen bei ähnlichen Benchmarks. Eine endgültige Rangliste würde mehrere Aufgaben, wiederholte Durchläufe und mehrere unabhängige Bewertungsmethoden erfordern.