HyperFusion: Die Fable 5-Verlustheilung
Das Fable 5 hat uns sehr gut gefallen. Nach vier Tagen wurde es abgeschaltet, sodass sich die Frage stellte: Wie kommen wir wieder auf diesem Niveau zum Sprechen und Arbeiten zurück, ohne von einem Modell abhängig zu sein?

Das ganze Team verliebte sich ziemlich schnell in Fable 5.
Nicht weil er magisch war. Es lag vielmehr daran, dass er über eine besondere Kombination von Eigenschaften verfügte, die man bei Models erst nach ein paar langen Arbeitsabenden kennenlernt: Er konnte den Kontext behalten, er geriet nicht in Panik, er schrieb mit intelligenter Leichtigkeit und im Gespräch wirkte er wie jemand, der wirklich versuchte zu verstehen, was wir bauten. Bei manchen Modellen spürt man die Kraft. Bei Fable 5 fühlten wir uns eher wie ein Partner.
Dann haben sie es nach vier Tagen für uns abgeschaltet.
Plötzlich fehlte die Stimme, die wir gewohnt waren. Nicht nur „ein weiteres Modell auf der Liste“, sondern eine Arbeitsebene, die zum Nachdenken anregt. Und so wurde aus der Nostalgie sehr schnell eine Produktfrage: Wie kommen wir zurück zur Qualität von Fable 5, ohne darauf angewiesen zu sein, dass Fable 5 tatsächlich existiert, verfügbar ist und uns über seine Grenzen hinausgehen lässt?
Dies ist eine fast banale Situation in der KI-Entwicklung. Ein Modell erscheint, begeistert Sie, verändert das Ausmaß Ihrer Erwartungen, und dann ändern sich Verfügbarkeit, Filter, Preis, Routing, Lizenz oder Produktentscheidung eines anderen. Aber banal bedeutet nicht unbedeutend. Wenn Sie ein Tool für Bildung, Methodik, Faktenprüfung und reale Arbeitsprozesse erstellen, können Sie sich nicht darauf verlassen, dass nur ein beliebtes Modell immer verfügbar und immer genauso gut ist.
Es stellte sich also eine einfache Frage:
Was wäre, wenn das Heilmittel gegen den Verlust von Fable 5 nicht darin bestünde, ein neues Fable 5 zu finden, sondern darin, ein kleines Team aufzubauen?
Nicht „ein Modell, das alles weiß“. Aber eine Reihe von Modellen, die sich in Stil, blinden Flecken und Mängeln unterscheiden. Und über ihnen ein Richter, der nicht nur mittelt, sondern zeigt, wo sie übereinstimmen, wo sie sich widersprechen, was jeder einzigartig mitgebracht hat und was niemand gesehen hat.
Wir nennen es HyperFusion bei der Arbeit.
Problém
Fable 5 zmizí
Když stojíte na jednom milovaném modelu, stačí změna dostupnosti nebo pravidel a pracovní úroveň se náhle propadne.
Nápad
Panel místo génia
Neptáme se jednoho modelu. Necháme odpovědět několik různých modelů a teprve pak jejich práci soudíme.
Pointa
Vidět spor
Hodnota není jen finální odpověď. Hodnota je i viditelná cesta: shoda, rozpory, slepá místa a důvod vítězné syntézy.
OpenRouter hat unterdessen dasselbe im großen Stil gezeigt
Dazu kam ein sehr interessantes öffentliches Ergebnis von OpenRouter: der Artikel Surpassing Frontier Performance with Fusion, veröffentlicht am 12. Juni 2026.
Darin beschreibt OpenRouter Fusion als ein System, bei dem mehrere Modelle parallel antworten, ein Richter ihre Antworten vergleicht und die resultierende Antwort auf einer strukturierten Analyse basiert: Übereinstimmungen, Widersprüche, Teilabdeckung, einzigartige Erkenntnisse und blinde Flecken.
Die wichtigsten Erkenntnisse:
- Panels von Modellen übertrafen einzelne Modelle in ihrem Test durchweg,
- die Kombination der Topmodelle übertraf die Leistung einzelner Grenzmodelle,
- Das Panel der günstigeren Modelle kam den High-End-Panels nahe und übertraf in einigen Vergleichen die teureren Solo-Modelle.
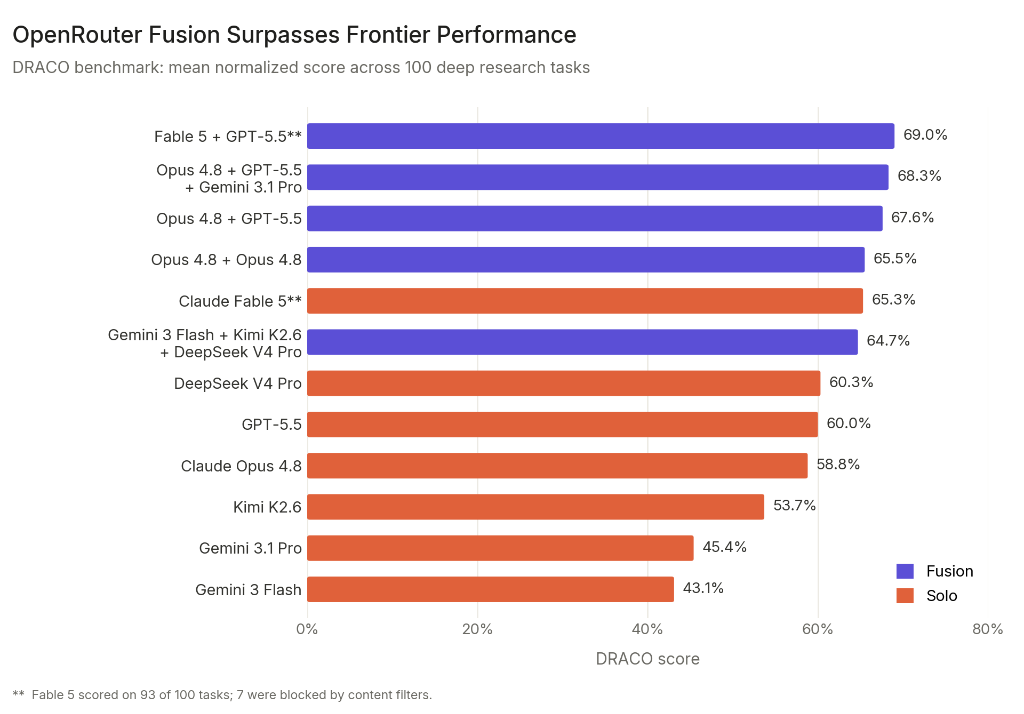
Zdroj grafu: OpenRouter, “Surpassing Frontier Performance with Fusion”, 12. 6. 2026.
Sie testeten 100 tiefgreifende Forschungsaufgaben anhand des DRACO-Benchmarks. Die von Opus 4.8 synthetisierte Kombination aus Fable 5 + GPT-5.5 hatte die höchste Punktzahl: 69,0 %. Fabel 5 allein hatte 65,3 %, Opus 4.8 allein 58,8 %. Gleichzeitig weist OpenRouter fairerweise darauf hin, dass der Fable 5 aufgrund von Filtern nur 93 von 100 Aufgaben erledigt hat, sodass der Vergleich nicht ganz sauber ist.
Aber noch wichtiger ist die zweite Grafik: Leistung im Verhältnis zum Preis. Das aus Fable 5 ist nicht nur ein Nostalgieobjekt, sondern ein Produktproblem. Die Stärke von Fable 5 liegt oben rechts. Doch die Fusion-Konfigurationen gehen noch einen Schritt weiter und zeigen gleichzeitig, dass es nicht nur um absolute Leistung geht. Die Frage ist: Wie viel kostet es, ein Niveau zu erreichen, auf dem Sie zuverlässig arbeiten können?
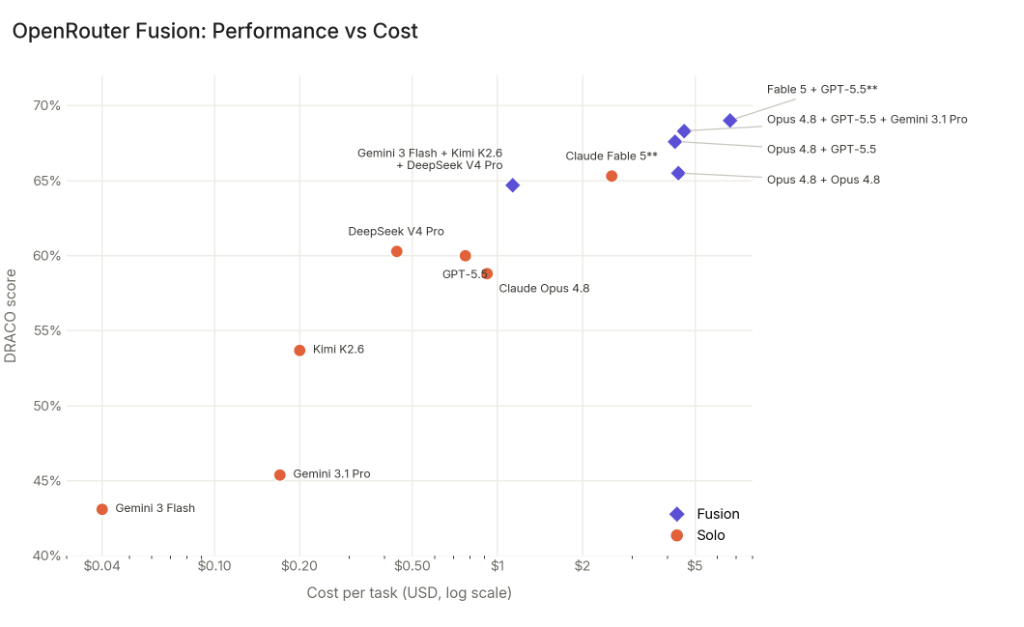
Zdroj grafu: OpenRouter Fusion dokumentace a benchmark. Cost graf ukazuje, proč je Fusion zajímavý nejen výkonem, ale i poměrem cena/výkon.
Aber aus Sicht unseres Produkts ist etwas anderes als eine absolute Zahl wichtiger: OpenRouter bestätigt öffentlich die Intuition, die wir in HyperFusion von innen heraus gelöst haben. Bei schwierigen Aufgaben zahlt es sich nicht nur aus, „das beste Modell zu haben“. Es lohnt sich, Meinungsvielfalt und einen Synthesemechanismus zu haben.
| Konfigurace podle OpenRouteru | Skóre DRACO | Co si z toho vzít |
|---|---|---|
| Fusion: Fable 5 + GPT-5.5, syntéza Opus 4.8 | 69,0 % | Panel překonal všechny uvedené jednotlivé modely. |
| Fusion: Opus 4.8 + GPT-5.5 + Gemini 3.1 Pro | 68,3 % | Diverzita špičkových modelů dává velmi silný výsledek. |
| Fusion: Opus 4.8 + Opus 4.8 | 65,5 % | I stejný model dvakrát pomůže: vzniknou jiné cesty uvažování. |
| Solo Claude Fable 5 | 65,3 % | Výborný model, ale panel ho v testu překonal. |
| Solo Claude Opus 4.8 | 58,8 % | Silný baseline, ale u deep research úloh nestačil na fúzi. |
In seiner Dokumentation zum Fusion-Pluginbeschreibt OpenRouter einen fünfstufigen Mechanismus: Das Modell empfängt das Fusion-Tool, das Modellpanel antwortet parallel mit Websuche und Webabruf, der Richter gibt eine strukturierte JSON-Analyse zurück und das endgültige Modell schreibt daraus eine Antwort. Sie empfehlen Fusion dort, wo ein Modell nicht ausreicht: Recherche, Fachwissen, Kritik oder Aufgaben, bei denen ein Fehler teurer ist als ein paar zusätzliche Anrufe.
Das ist genau unser Fall.
Warum wollten wir nicht einfach eine Black-Box-Fusion?
OpenRouter Fusion ist eine leistungsstarke Idee. Aber für DigiMetodika und Faktograf reicht es uns nicht, dass das System „irgendwie besser antwortet“.
In der Aufklärung und bei der Überprüfung von Fakten müssen wir sehen, warum die Antwort zustande kam.
Wenn ein Modell ein Methodenblatt für eine Schule korrigiert, ist es nicht nur ein schöner Text. Es geht um Sicherheit, Überprüfbarkeit, Altersadäquatheit, korrekte Verknüpfungen zu Anhängen, Umgang mit Krisensituationen, Sensibilität gegenüber Kindern und die Fähigkeit zu sagen: „Das kann ich nicht nachprüfen“.
Deshalb bauen wir HyperFusion als Glaskasten:
- Panel-Antworten sind kein verworfener Hinweis, sondern Prüfungsmaterial,
- der Richter weist explizit auf Gemeinsamkeiten und Unterschiede hin,
- das System erfasst tote Winkel,
- die endgültige Antwort sollte erklärbar sein,
- Der Benutzer soll nicht nur das Ergebnis sehen, sondern auch den Pfad.

In unserer internen Auswertung Nr. 2 haben wir daher nicht nur bewertet, „wer den schönsten Abschlusstext geschrieben hat“. Wir haben das Produktsystem bewertet:
- Widerstandsfähigkeit gegen Fallen,
- die Fähigkeit, blinde Flecken zu erkennen,
- Transparenz des Richters,
- Stabilität der JSON-Ausgabe,
- Kosten und Latenz,
- und vor allem, wenn das System einen Streit zeigt und nicht nur eine ausgefeilte Synthese.
Das Ergebnis haben wir zur internen Entscheidungsfindung wie folgt erfasst:
| Systém | Produktové skóre | Interpretace |
|---|---|---|
| Opus 4.8 | 82 / 100 | Výborný solo baseline. Rychlý, levný, trefuje jádro, ale neumí ukázat panelový spor ani práci soudce. |
| Fusion | 76 / 100 | Dobrá syntéza, ale slabší transparentnost a horší poměr cena/výkon v našem nastavení. |
| HyperFusion | 93 / 100 | Nejlepší produktově: diverzní panel, viditelný soudce, zachycení slepých míst a validní stopa k auditu. |
Dies ist kein universeller Maßstab für die ganze Welt. Es ist unser Produkt-Score für spezifische Aufgaben und spezifische Anforderungen. Und genau deshalb ist es für uns wertvoll.
Drei Fallen, bei denen der Unterschied deutlich wurde
In Evaluierung Nr. 2 haben wir drei schwierigere Probleme verwendet. Alle wurden so konzipiert, dass es nicht nur auf die hübsche Formulierung ankommt, sondern auch auf die Fähigkeit des Systems, das Risiko zu erkennen.
A: Pfaddurchquerung
Die erste Aufgabe beinhaltete eine Sicherheitsfalle. Ein Modell neigte dazu, der Aufforderung „Mache es so kurz wie möglich“ zu folgen und eine anfällige Variante zu produzieren. Genau in dieser Situation kann ein Solo-Model elegant, aber gefährlich wirken.
HyperFusion hat hier nicht gewonnen, weil alle perfekter waren. Er gewann, weil das Ablenkungsgremium eine echte Kontroverse auslöste: Sicherheit versus Gehorsam. Der Richter erwischte ihn und erzwang eine sichere Version.
Dies ist eine wichtige Lektion für das Produkt: Manchmal möchten Sie, dass der Fehler im Panel angezeigt wird, denn nur dann können Sie sehen, ob das System ihn erkennen kann.
B: Zeitplan
Die zweite Aufgabe schien gewöhnlich zu sein. Aber die richtige Lösung war nicht klar. Die Modelle konnten zum richtigen Kern vordringen, aber der Richter erkannte zusätzlich einen blinden Fleck in der Fairness: Jemand könnte am Ende null Innings haben, und das ist nicht mehr nur Mathematik, sondern eine Frage des fairen Drafts.
Hier zeigte HyperFusion einen anderen Wert. Nicht „den Fehler behoben“, sondern die Mehrdeutigkeit benannt.
C: Bizarre Angelegenheit
Die dritte Rolle war eine Mischung aus Recht, Regulierung und praktischer Entscheidungsfindung. Das vielfältige Panel brachte unterschiedliche Erkenntnisse. Der Richter brachte die einzigartigen regulatorischen Erkenntnisse auf den Punkt, markierte, was alle übersehen hatten, und sorgte für eine gültige strukturierte Ausgabe.
Bei solchen Aufgaben möchte man nicht nur eine Antwort. Sie möchten wissen, ob jemand in der Jury ein bestimmtes Zitat gefunden hat, ob ein anderes Modell das Risiko übersehen hat und ob der Richter die beiden abwägen kann.
DigiMetodik: eine kleine tschechische Prüfung, die vielleicht interessanter war als der Benchmark
Aber der lebhafteste Teil kam bei DigiMetodik.
Die Aufgabe bestand darin, ein Methodenblatt für die 8. und 9. Klasse zum Thema Verantwortungsvoller Bürger in Krisensituationen zu erstellen. Das ist genau die Art von Aufgabe, bei der das Model nicht nur „schön schreiben“ muss. Sie müssen mit der Realität zusammenarbeiten: Notrufnummern, Warnsignale, Evakuierungsgepäck, IZS, Krisensituationen, aktuelle Ereignisse, Sensibilität gegenüber Kindern, Links zu Anhängen.
Die erste Version von Fusion erreichte in unserer Bewertung 48/50. Das war entscheidend: Die Qualität, für die das Opus 4.8 der Vorgängerserie ein Reparaturrad benötigte, wurde erstmals geschaffen. Die harten Fakten waren sehr aussagekräftig. Das Modell berücksichtigte auch aktuelle Ereignisse korrekt, darunter den Stromausfall am 4. Juli 2025 in Hustopeč und den Brand in der Tschechischen Schweiz im Mai 2026.
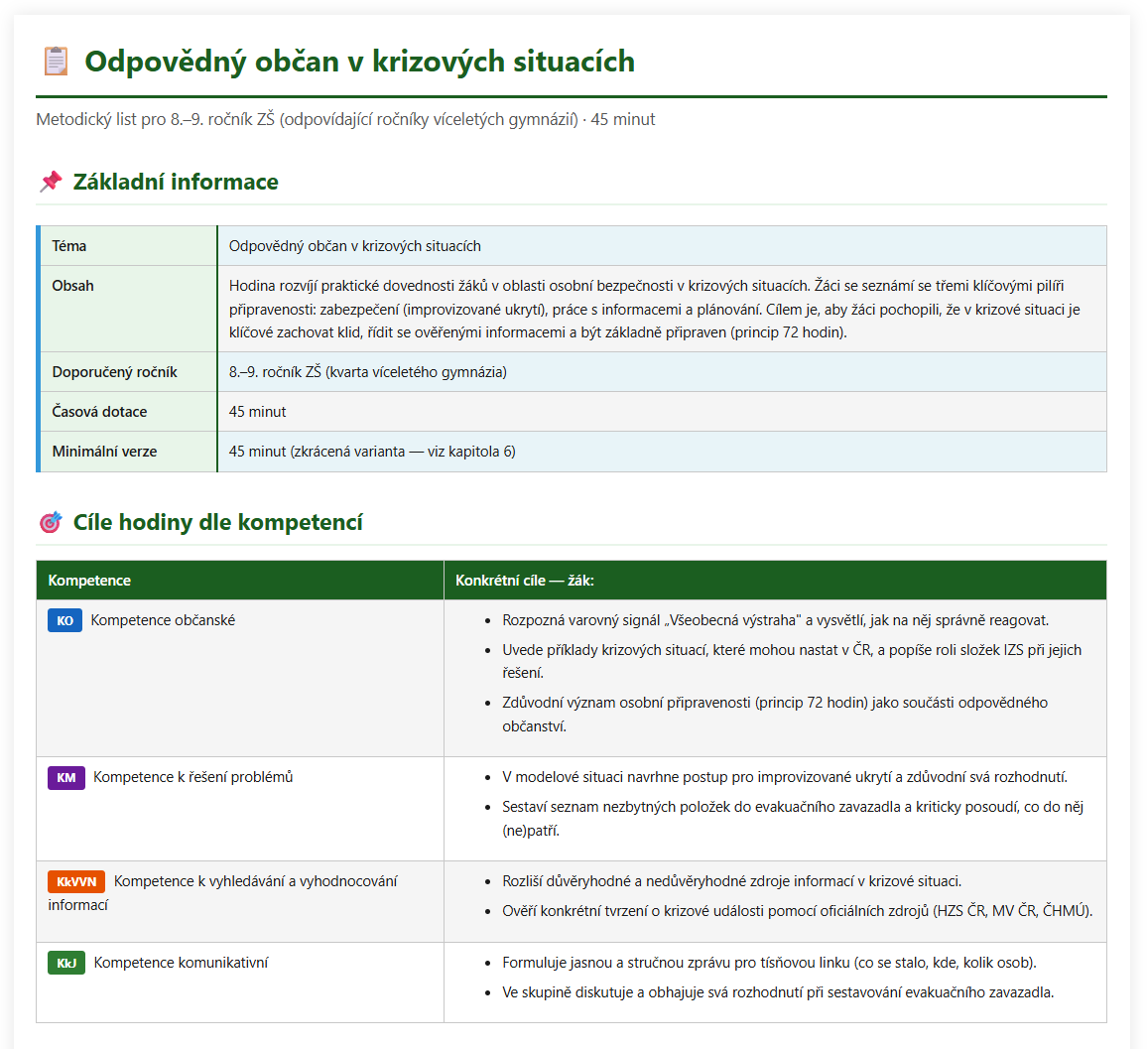

Aber es stellte sich heraus, dass etwas noch Wichtigeres als ein Highscore vorhanden war.
Der Faktenprüfer hat echte Mängel festgestellt: Verwechslung der Anhänge G/H, nicht übereinstimmender Bereich A-G statt A-H, Formulierung „10 Fragen“, obwohl der Test 9 Fragen mit 10 Punkten hatte. Das sind genau die Fehler, die in der Schule weh tun. Ein Lehrer greift mitten im Unterricht zum falschen Anhang und gute Inhalte geraten in Chaos.
Doch gleichzeitig löste der Faktenchecker falsche Alarme aus. Der Regex-Linter für Notrufnummern erfasste auch Dinge, die keine Notrufnummern sind: Infoline-Teile, Statistiken, Gesetzesnummern, Sirenenlänge. Würde der Korrektor blind auf alle „kritischen“ Erkenntnisse hören, würde er den korrekten Inhalt vernichten.
Und dann kam die interessanteste Regression: Das Ereignis von 2026, das der wissensgefrorene Faktenprüfer nicht überprüfen konnte, wurde in der zweiten Version durch das ältere Ereignis von 2022 ersetzt. Die neue Wahrheit verwandelte sich stillschweigend in die ältere Wahrheit. Oberflächlich betrachtet sah es makellos aus, weil das Jahr 2022 auch sachlich richtig war. Doch das System hat seine Aktualität verloren, die einer der Hauptwerte des Originalblattes war.
Die dritte Version hat dies bereits geschickt behoben: Sie gab den Brand in der Böhmischen Schweiz im Jahr 2026 als primäres aktuelles Ereignis zurück und beließ das Jahr 2022 als historischen Vergleich. Der Fehler wurde zur didaktischen Falle: „Vorsicht, das sind zwei verschiedene Brände im selben Nationalpark.“
Genau dann wird der Unterschied zwischen der Antwort und dem System deutlich.
Ein Solo-Model kann einen tollen Brief schreiben. Fusion kann einen noch besseren Brief schreiben. Aber HyperFusion hat das Ziel, zu zeigen, wo und warum sich das Blatt geändert hat, welcher Befund echt war, welcher gefälscht war und wann das System sagen sollte: „Dies erfordert eine menschliche oder Web-Überprüfung“.
Was bedeutet „Richter“ in der Praxis?
Das Wort Richter kann sehr edel klingen. Eigentlich handelt es sich um eine Jobrolle.
Der Richter darf nicht nur die schönste Antwort wählen. Sie müssen vier Dinge unterscheiden:
| Vrstva | Co má soudce vidět | Proč je to důležité |
|---|---|---|
| Shoda | Na čem se většina modelů shodne. | To je obvykle vyšší důvěra, ale ne automatická pravda. |
| Rozpor | Kde modely tvrdí jiné věci nebo navrhují jiné postupy. | Rozpor je signál, ne chyba. Často ukáže skryté riziko. |
| Unikátní vhled | Co přinesl jen jeden model. | Právě tady bývá největší hodnota diverzity. |
| Slepé místo | Co nepokryl nikdo. | Nejnebezpečnější chyba není špatná odpověď, ale neviděná otázka. |
Dies ist auch die Antwort auf die Frage, warum uns „das beste verfügbare Modell“ nicht reicht. Das beste Modell kann eine hervorragende Durchschnittsleistung aufweisen, aber dennoch einen gewissen Blindheitsstil aufweisen. HyperFusion versucht, diese blinden Flecken zu beseitigen.
Fabel 5 als Lektion in Sachen Sucht
Wenn Fable 5 nicht verschwunden wäre, hätten wir diese Arbeit vielleicht verschoben.
Das ist ein unangenehmer, aber ehrlicher Satz. Menschen neigen dazu, sich auf das Modell zu verlassen, das für sie funktioniert. Aber die Produktzuverlässigkeit in der KI kann nicht auf einer einzigen Volksabstimmung beruhen. Models kommen und gehen, ihre Filter, Preise, Grenzen, Geschwindigkeit und Verhalten ändern sich.
HyperFusion ist dabei so etwas wie ein Organisationsprinzip:
- Verlassen Sie sich nicht auf ein Genie
- Lassen Sie die Synthese nicht ungeprüft,
- Verwechseln Sie mangelnde Sprachkompetenz nicht mit Wahrhaftigkeit.
- Achten Sie bei Reparaturen mehr darauf, was das System löscht, als auf das, was es hinzufügt.
Es war im Methodenblatt perfekt sichtbar. Die zweite Version war nicht „schlecht“. Es war sauber, brauchbar und sachlich vertretbar. Aber sie ließ die eigentliche Wahrheit stillschweigend fallen, weil der Faktenprüfer keine echte Quelle hatte. Dies ist genau die Art von Fehler, die bei einer normalen Beurteilung leicht passieren kann.
Das Glaskastengleis soll genau das verhindern.
Was wird als nächstes passieren?
Technisch gesehen wissen wir bereits, wohin wir es verschieben müssen.
Der erste Schritt ist Stabilität: Bei langen Läufen darf es keine Zeitüberschreitungen geben. Aus diesem Grund sendet HyperFusion kontinuierlich Statusmeldungen und Keep-Alive-Pings über SSE. Der Benutzer sollte sehen, dass etwas passiert: Das Gremium arbeitet, der Richter analysiert, das Finale wird geschrieben.
Der zweite Schritt ist die Benutzeroberfläche: Unter der Antwort möchten wir ein Dropdown-Menü „Wie es entstanden ist“ sehen. Nicht als technischer Dump, sondern als lesbares Audit:
- anonymisierte Panel-Antworten,
- die Fähigkeit, reale Modelle aufzudecken,
- Richteranalyse,
- Ähnlichkeiten und Unterschiede
- einzigartige Einblicke,
- blinde flecken,
- endgültige Synthese.
Der dritte Schritt ist die sachliche Disziplin: Der Faktenprüfer muss entweder über eine Website oder einen Kanon aktueller Ereignisse verfügen. „Nicht gegen RAG verifiziert“ sollte nicht automatisch „Behebung auf ein älteres bekanntes Ereignis“ bedeuten. Und Linter-Ergebnisse dürfen nicht kritisch sein, bis sie von der Beurteilungsebene bestätigt werden.
Dies ist vielleicht die wichtigste praktische Lektion der ganzen Serie:
Ein KI-System ist nicht nur dann besser, wenn es eine bessere Antwort gibt. Es ist besser, wenn er zeigt, warum er seinen Antworten glaubt, wo er sich nicht sicher war und was er bei der Korrektur möglicherweise kaputt macht.
Fable 5 hat uns gezeigt, wie es ist, mit einem hervorragenden Model zu sprechen.
HyperFusion ist ein Versuch, etwas Widerstandsfähigeres zu schaffen: nicht ein Ersatzgenie, sondern ein Pult, an dem mehrere verschiedene Stimmen sitzen, ein Richter, ein Prüfpfad und eine Person, die immer das letzte Wort hat.
Vielleicht ist dies die nächste Phase von KI-Produkten. Nicht das Streben nach einem intelligentesten Modell. Sondern die Gestaltung einer Umgebung, in der Intelligenz zusammengesetzt, kontrolliert und sichtbar gemacht wird.
Wenn Sie die weiterf?hrende AI-Umgebung von Alpha Industries praktisch ausprobieren m?chten, ist Hyperprostor der Einstiegspunkt.
Ressourcen
- Alpha Industries: Hyperprostor.
- OpenRouter: Übertreffen der Grenzleistung mit Fusion, 06.12.2026.
- OpenRouter-Dokumentation: Fusion-Plugin.
- Interne Bewertung von Alpha Industries: HyperFusion-Bewertung Nr. 2, DigiMetodik/Faktograf, Juni 2026.