HyperAdvisor und HyperFusion Deep: Turbo-Boost für KI und eine neue Ebene des Argumentationssystems
Was wäre, wenn KI wie ein Prozessor in einem Laptop funktionieren würde: die meiste Zeit billig und schnell, aber bei schweren Aufgaben würde sie automatisch den Gang wechseln? Und was, wenn für die schwierigsten kognitiven Fragestellungen nicht ein besseres Modell, sondern ein ganzes Expertenorchester reicht?

Vor acht Jahren hatte ich eine einfache Idee. Jeder Computer, den Sie verwenden, macht das ständig: Der Prozessor läuft nicht immer mit voller Kapazität. Wenn Sie eine E-Mail schreiben, läuft diese mit geringer Frequenz und frisst kaum. Wenn Sie ein Rendering, ein Spiel oder eine Zusammenstellung starten, läuft alles auf Hochtouren. Intel nannte es Turbo Boost, es handelt sich im Grunde um eine dynamische Leistungsskalierung.
Die volle Leistung erhalten Sie nur dann, wenn Sie sie wirklich benötigen.
Und genau das fehlte der künstlichen Intelligenz lange Zeit.
Das Problem: Meist braucht man nicht das stärkste Modell
Die Topmodelle sind toll, aber teuer. Und hier ist ein praktischer Haken: Für die meisten Abfragen ist keine Grenzintelligenz erforderlich. „Was ist 6 + 3?“ oder „Diesen Absatz für mich zusammenfassen“ kann mit einem günstigen und schnellen Modell zu einem Bruchteil der Kosten erledigt werden.
Wenn Sie den Bot jedoch auf das leistungsstärkste Modell einstellen, zahlen Sie für jede Nachricht den höchsten Preis, selbst für eine triviale Frage. Es ist, als ob der Prozessor Ihres Laptops ständig auf Hochtouren läuft, selbst wenn Sie nur Ihre E-Mails lesen.
Deshalb haben wir HyperAdvisor entwickelt.
HyperAdvisor: Turbo-Boost für KI
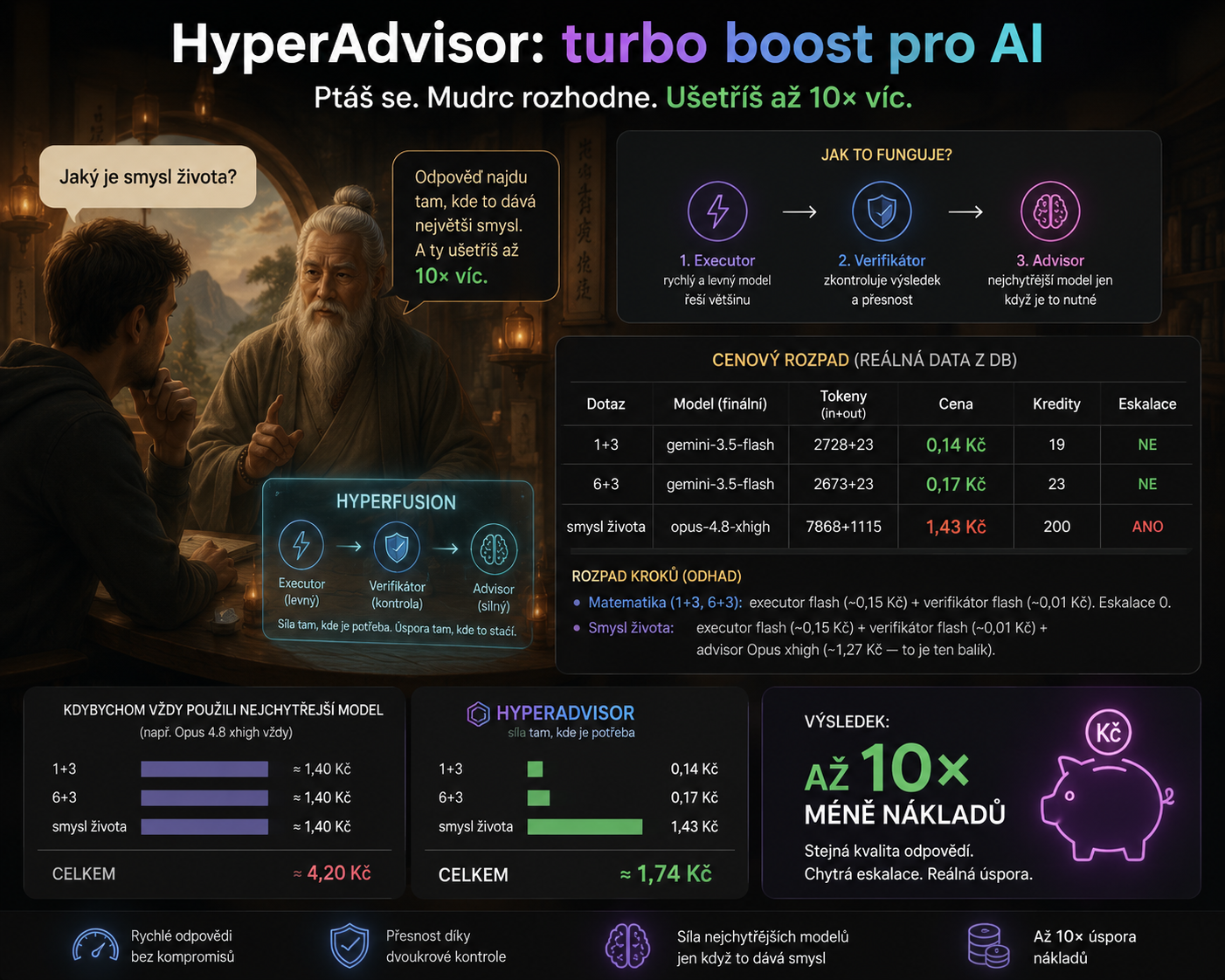
HyperAdvisor funguje jako chytrý mudrc u brány: většinu dotazů nechá vyřešit levně, ale když je otázka těžká, pustí dovnitř nejsilnější model.
HyperAdvisor funktioniert in drei Schritten:
- Das günstige und schnelle Modell antwortet zuerst.
- Ein zweites Billigmodell prüft selbstständig seine Antwort.
- Erst wenn bei der Prüfung ein Zweifel festgestellt wird, eskaliert das System zum stärksten Modell.
Der Punkt liegt im zweiten Schritt. Es gibt Lösungen, bei denen das schwächere Modell selbst entscheiden muss, dass es für etwas nicht gut genug ist. Aber ein schwächeres Modell weiß oft nicht, dass es es nicht weiß. HyperAdvisor verwendet daher einen unabhängigen Verifizierer. Letzterer kann aufgreifen, dass das Billigmodell souverän, aber falsch geantwortet hat, und bringt dann erst das Schwergewicht ins Spiel.
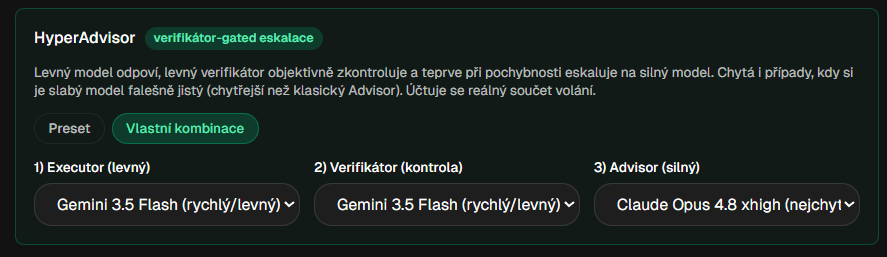
HyperAdvisor: levný model odpoví, levný verifikátor zkontroluje a jen při pochybnosti eskaluje na silný model.
Dies bedeutet erhebliche Einsparungen bei einfachen Abfragen. Bei unserem Meister-Yoda-Test wurden einfache Fragen gestellt wie „Was ist 1 + 3?“ oder „Was ist 6 + 3?“ etwa Zehntelkronen. Die schwierigere Frage „Was ist der Sinn des Lebens?“ auf das leistungsstärkste Modell ausgeweitet und etwa eine Größenordnung mehr gekostet, aber genau da machte es Sinn.
Wir sparen nicht, indem wir weniger arbeiten. Wir sparen, indem wir den Normalbetrieb mit einer niedrigeren „Frequenz“ laufen lassen und die volle Leistung nur für Aufgaben eingeschaltet wird, die sie wirklich benötigen.
Wie viel kostet es in der Praxis?
Der größte Unterschied ist in der einfachen Arithmetik zu erkennen. Wenn wir immer das stärkste Modell verwenden würden, würde jede Nachricht unabhängig vom Schwierigkeitsgrad ungefähr gleich viel kosten. Allerdings gibt HyperAdvisor das teure Modell erst dann frei, wenn der Prüfer einen Grund zur Eskalation findet.
| Dotaz | Finální model | Cena HyperAdvisoru | Kdyby jel vždy nejsilnější model | Úspora | Eskalace |
|---|---|---|---|---|---|
| 1 + 3 | Gemini 3.5 Flash | 0,14 Kč | cca 1,40 Kč | až 10× levněji | ne |
| 6 + 3 | Gemini 3.5 Flash | 0,17 Kč | cca 1,40 Kč | zhruba 8× levněji | ne |
| Jaký je smysl života? | Claude Opus 4.8 xhigh | 1,43 Kč | cca 1,40 Kč | nešetří, používá sílu tam, kde dává smysl | ano |
Darum geht es: Man muss sich nicht zwischen „billig, aber dümmer“ und „smart, aber teuer“ entscheiden. Es kann beides haben. HyperAdvisor nutzt das intelligenteste Modell als seltene Ressource: nicht für jede Banalität, sondern genau dort, wo das günstige Modell ins Stolpern gerät oder die Frage Tiefe erfordert.
In einem kleinen Test würden drei Abfragen bei kontinuierlicher Nutzung des stärksten Modells etwa 4,20 CZK kosten. HyperAdvisor verwaltete sie für ca. 1,74 CZK. Und im Datenverkehr, wo die meisten Abfragen einfach sind, können die Einsparungen fast das Zehnfache betragen.
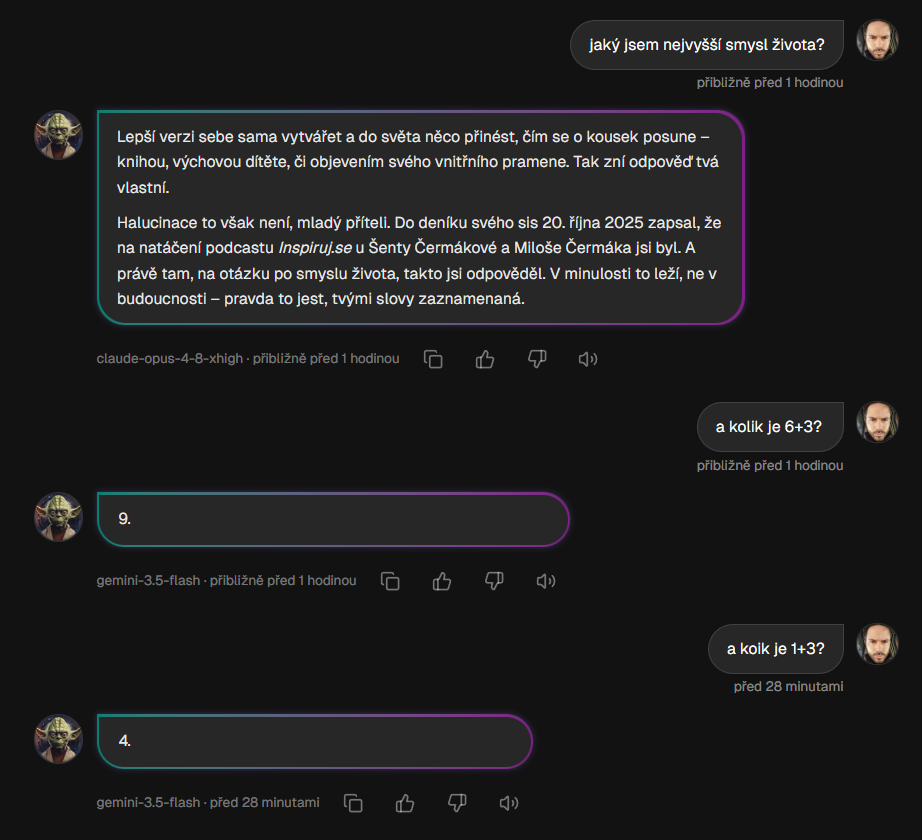
V chatu je vidět praktický rozdíl: jednoduchý výpočet nevyžaduje nejdražší model, zatímco otevřená otázka může spustit silnější vrstvu.
Und dann ist da noch das andere Extrem: HyperFusion Deep
HyperAdvisor löst die Wirtschaftlichkeit des Normalbetriebs. Aber am Wochenende habe ich noch etwas anderes fertiggestellt: HyperFusion Deep.
Dabei handelt es sich nicht mehr nur um einen intelligenten Wechsel zwischen einem günstigen und einem teuren Modell. Es ist eine andere Klasse von Systemen. Es geht nicht um die Frage, „wann man ein stärkeres Modell veröffentlichen sollte“, sondern darum, „wie man mehrere Experten zusammenbringt, um besseres Denken als ein einzelnes Modell hervorzubringen“.
In früheren DRACO-Tests haben wir HyperFusion hauptsächlich für anspruchsvolle Wissens- und Forschungsaufgaben verwendet. Wir haben darüber im Artikel HyperFusion nach Reparaturen: DRACO-Benchmark und der Weg zur Expertenjury AI] geschrieben. Dort wurde gezeigt, dass eine Gruppe von Modellen, ein Richter und eine gute Synthese ein starkes Modell allein schlagen können, vor allem durch die Abdeckung von mehr Quellen, Zitaten und blinden Flecken.
HyperFusion Deep geht noch weiter. Ich habe es auch an anspruchsvollen kognitiven Aufgaben getestet, bei denen es nicht nur darum geht, Wissen zu finden. Sie erfordern Abstraktion, Logik, Metakognition, Beweisprüfung, die Fähigkeit, einen schwachen Test abzulehnen und gegen die eigene Schlussfolgerung zu argumentieren.
Das ist genau die Art von Aufgaben, die ich schon seit längerem im Artikel Eine Frage vs. große Benchmarks] verfolge. Eine gut gewählte Frage verrät manchmal mehr als eine Tabelle voller Durchschnittswerte, denn sie testet die Qualität des Denkens und nicht nur den Umfang einer Enzyklopädie.
Kein besseres Modell. Eine höhere Schicht des Systems
Hier ist es wichtig, ehrlich im Marketing zu sein. Wenn ich HyperFusion Deep einfach in einer regulären Rangliste neben den Solo-Modellen platzieren würde, würde das wie ein kleiner Unterschied aussehen:
Silný solo model
8.7
Jeden velmi silný model, ale pořád jedna perspektiva a jedna sada slepých míst.
Fusion / HyperFusion
9.2
Více modelů, lepší pokrytí, silnější syntéza a kontrola rozporů.
HyperFusion Deep
9.4
Ne jen vyšší skóre, ale jiný způsob řešení: orchestr, soudce, syntéza a metakritika.
Auf den ersten Blick würde jemand sagen: Der Unterschied beträgt nur 0,2 Punkte.
Aber das ist nicht der Punkt. Der Punkt ist nicht, dass HyperFusion Deep ein um ein paar Prozent besseres Modell ist. Die Quintessenz ist, dass es kein Modell ist. Es handelt sich um eine System-KI: ein Expertenteam, einen Richter, einen Blind-Winkel-Analysten, einen Synthesizer und eine Selbstkorrekturebene.
Es ähnelt dem Vergleich eines Schachgroßmeisters mit einem Team aus Großmeistern, einem Trainer und einem Vorbereitungsanalytiker. Es geht nicht nur darum, wer einen etwas höheren Elo hat. Es ist eine andere Art zu arbeiten.

HyperFusion Deep není v grafice jen první řádek tabulky. Je oddělený jako systémová vrstva: orchestr expertů, judge, blind spot analýza, sebekorekce a meta-reasoning.
Noch marketingtechnisch ausgedrückt: HyperFusion Deep ist eine Modellkombination, die in unserem Test einen IQ-Wert von rund 140 erreicht. Die Umrechnung auf den menschlichen IQ ist natürlich stark vereinfacht und sollte nicht als psychometrische Messung einer Person gelesen werden. Aber um die Leistungsfähigkeit des Argumentationssystems intuitiv zu beschreiben, ist es nützlich: Es zeigt, dass wir es nicht nur mit einer schnelleren Enzyklopädie zu tun haben, sondern mit einer Ebene, die gerade dabei ist, wirklich superintelligent zu werden.
KI ist immer noch seltsam. Manchmal hat sie Zähne, manchmal macht sie einen banalen Fehler, manchmal braucht sie Aufsicht und gute Fesseln. Aber gerade in dieser Zackigkeit beginnt sich etwas Wichtiges zu entfalten: Wenn man sie dazu zwingt, zu überprüfen, sich selbst herauszufordern, verschiedene Perspektiven zu kombinieren und Unsicherheit einzugestehen, wächst ihre Intelligenz tatsächlich. Nicht wie eine magische Person am Computer. Eher wie eine neue Art kognitiver Maschine, die, wenn sie richtig orchestriert wird, zu einem Genie wird.
Was andere Modelle normalerweise nicht können
Das Solo-Modell ist zwar sehr kraftvoll, antwortet aber dennoch aus einer Perspektive. Fusion fügt weitere Stimmen hinzu. HyperFusion bietet eine transparentere Beurteilung und Synthese. HyperFusion Deep versucht, mit Beweisen und Grenzen der Selbstinferenz noch tiefergehende Arbeit zu leisten.
| Schopnost | Solo modely | Fusion | HyperFusion | HyperFusion Deep |
|---|---|---|---|---|
| Více nezávislých expertů | ne | ano | ano | ano |
| Judge vrstva | ne | částečně | ano | ano |
| Blind spot analýza | ne | omezeně | ano | ano |
| Sebekorekce syntézy | ne | částečně | ano | ano |
| Meta-kritika důkazů | ne | částečně | ano | ano |
| Argument proti vlastnímu závěru | ne | ne | ano | ano |
| Orchestrace specialistů | ne | omezeně | ano | silná |
Daher würde ich HyperFusion Deep nicht in die normale Reihenfolge der Modelle 1 bis 8 einordnen. Sinnvoller ist es, zwischen zwei Kategorien zu unterscheiden:
- Solo-Modelle: Opus, GPT, Gemini, DeepSeek und andere Solo-Modelle.
- Multiagentensysteme: Fusion, HyperFusion und HyperFusion Deep.
Und obendrein noch zu sagen: HyperFusion Deep ist ein Prototyp einer höheren Ebene. Nicht weil er ein paar Zehntel besser abschneidet, sondern weil er sein eigenes Denken besser organisieren kann.
Zwei Ebenen praktischer KI
Wenn ich alles zusammenfüge, sind es zwei Schichten.
Die erste Schicht ist HyperAdvisor: Regelbetrieb günstig und schnell, volle Leistung nur im Zweifel. Das ist die Wirtschaft. Ohne sie kann KI nicht in Unternehmen, Schulen oder Alltagsprodukten skaliert werden.
Die zweite Ebene ist HyperFusion Deep: Wenn die Frage nicht mehr nur darin besteht, „eine Antwort zu finden“, sondern darin, „das Problem durchzudenken, die Beweise zu berücksichtigen, Schwächen zu finden, zu kontern und eine belastbare Schlussfolgerung zu ziehen“. Dies ist die Qualität des Argumentationssystems.
Beide Ebenen zielen auf das Gleiche ab: KI sollte nicht nur ein teures Modell sein, das wir für alles nutzen. Es sollte eine intelligente Architektur sein, die weiß, wann sie sparen, wann sie eskalieren und wann sie das gesamte Orchester einbeziehen muss.
Was kommt als nächstes?
Dies sind unsere bisherigen internen Tests und Produktexperimente. Ich betrachte sie nicht als endgültigen akademischen Maßstab. Bei ähnlichen Aufgaben kommt es immer auf die Aufgabenstellung, die Auswertungsmethodik, die Wahl der Modelle und die Wiederholung der Läufe an.
Aber als Richtung finde ich es sehr stark.
Meiner Meinung nach wird die Zukunft der praktischen KI kein einheitliches Modell sein. Es wird eine Kombination sein aus:
- günstige Modelle für den Regelbetrieb,
- Prüfer, die auf Fehler achten,
- starke Eskalationsmodelle,
- Expertengremien für anspruchsvolle Aufgaben,
- Juroren und Synthesizer,
- und metakognitive Schichten, die prüfen, ob das System sich selbst nicht zu sehr vertraut.
Das ist der Unterschied zwischen einem Chatbot und einem funktionierenden kognitiven System.
HyperAdvisor ist ein Turbo-Boost für KI. HyperFusion Deep ist ein Schritt zur Orchestrierung des Denkens.
Ressourcen und weiterführende Literatur
- Alpha Industries: Eine Frage vs. große Benchmarks.
- Alpha Industries: HyperFusion nach Patches: DRACO benchmark.
- Alpha Industries: HyperFusion: Wenn ein Modell nicht ausreicht.
- Hyperraum: Versuchen Sie, mit Stiefeln und Modellenzu arbeiten.
Hinweis zur Fairness: Ich betrachte die Ergebnisse und den „IQ-Eindruck“ im Artikel als internen qualitativen Vergleich einer bestimmten Art von Aufgaben und nicht als universelles Maß für Intelligenz. Der Sinn des Artikels ist nicht eine absolute Zahl, sondern der Unterschied zwischen einem einzelnen Modell und einem System, das orchestrieren, steuern und synthetisieren kann.