Eine Frage gegen zehn große Benchmarks: Wie gut hat der Mini-IQ-Test die Realität getroffen?
Vor ein paar Tagen habe ich den neuesten KI-Modellen nur eine einzige Frage gestellt — keinen Benchmark, keine Punktetabelle, nur eine intellektuelle Falle. Jetzt ist es Zeit, das Ergebnis mit den großen öffentlichen Benchmarks zu vergleichen, die seitdem erschienen sind. GPT-5.5 führt, Claude Opus 4.7 folgt dicht auf, Gemini 3.1 Pro war die größte Abweichung in meinem Test, DeepSeek V4 Pro lag am tiefsten. Eine Frage, die es sich lohnt, jedem Modell zu stellen — bevor man ihm vertraut.

Vor ein paar Tagen habe ich ein kleines Experiment gemacht: den neuesten KI-Modellen nur eine einzige Frage zu stellen.
Keinen Benchmark mit hunderten Aufgaben. Keine Punktetabelle. Nur eine intellektuelle Falle.
Das Modell sollte die Regeln der künstlichen Funktionen mep und dap ableiten, einen neuen Fall berechnen, die Mehrdeutigkeit zugeben, den besten Test vorschlagen, der seine Hypothese widerlegen könnte, und sagen, wobei es sich am wenigsten sicher ist.
Es ging mir nicht darum, „IQ" im psychologischen Sinne zu messen oder zu zeigen, dass klassische Benchmarks nutzlos sind.
Wenn ich einem Modell nur eine einzige Frage stellen könnte, die sein analytisches Denken, seine Metakognition und sein Umgang mit Unsicherheit am besten offenlegt — welche wäre das?
Den Beitrag haben über 50 000 Menschen angesehen, aber den Kommentaren zufolge ist vielen die Pointe entgangen. Nach ein paar Tagen lohnt sich der Vergleich mit den großen öffentlichen Benchmarks, die inzwischen erschienen sind.
📎 Falls Sie den ursprünglichen Artikel nicht gelesen haben, finden Sie ihn hier: Eine Frage statt zehn Benchmarks: Mini-IQ-Test für die neuesten KI-Modelle
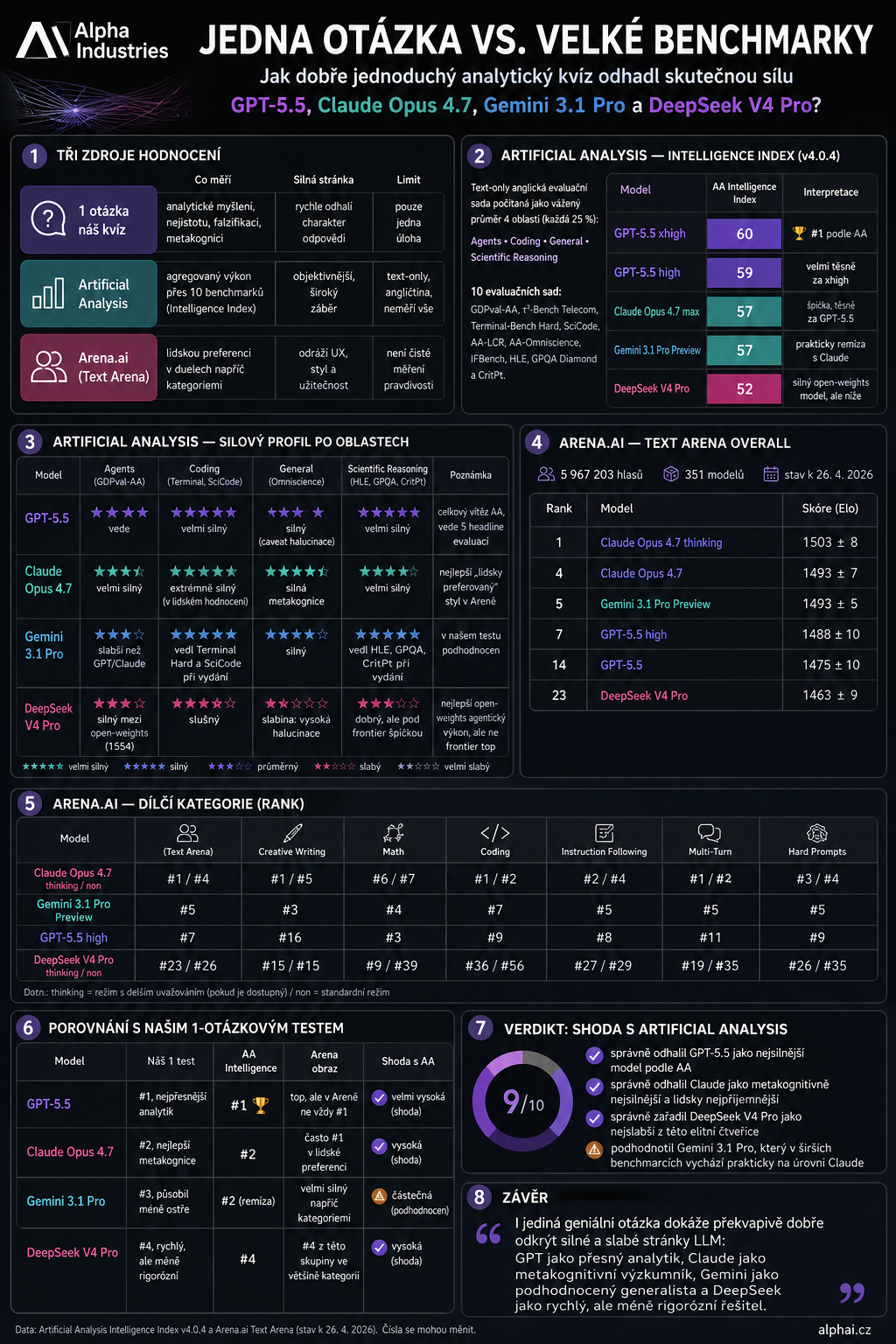
Wie Artificial Analysis „Intelligenz" misst
Der Artificial Analysis Intelligence Index berechnet die Intelligenz eines Modells heute als gewichteten Durchschnitt aus vier Bereichen:
- Agents — 25 %
- Coding — 25 %
- General — 25 %
- Scientific Reasoning — 25 %
Insgesamt sind das 10 Evaluations-Suiten: GDPval-AA, τ²-Bench Telecom, Terminal-Bench Hard, SciCode, AA-LCR, AA-Omniscience, IFBench, Humanity's Last Exam, GPQA Diamond und CritPt.
Fairer Hinweis: Es handelt sich um eine rein textbasierte englische Evaluation — sie misst nicht alles, etwa kein Tschechisch, keine Multimodalität, keine Sprache, keine reale UX-Tauglichkeit.
Und wie ist es ausgegangen?
🥇 GPT-5.5 — der sicherste Analytiker
GPT-5.5 liegt laut Artificial Analysis aktuell vorn. GPT-5.5 xhigh hat einen Intelligence Index von 60, GPT-5.5 high von 59.
Das passt gut zu meinem Ein-Frage-Test, in dem das Modell als sicherster Analytiker wirkte: präzise, kompakt, mathematisch scharf.
🥈 Claude Opus 4.7 — Forscher mit Metakognition
Claude Opus 4.7 liegt laut Artificial Analysis bei 57, also knapp hinter GPT-5.5. In der menschlichen Bewertung steht es jedoch oft noch höher — in der Text Arena Overall ist Claude Opus 4.7 thinking sogar Erster.
Das ist genau der spannende Unterschied: GPT wirkt wie ein sehr präziser „mathematischer Scharfschütze", Claude wie ein Forscher mit besserer Metakognition, mehr Vorsicht und klarerer Formulierung von Unsicherheit.
🥉 Gemini 3.1 Pro — die Überraschung der breiteren Benchmarks
Gemini 3.1 Pro war in meinem Ein-Frage-Test die größte Abweichung. In dieser konkreten Aufgabe wirkte es weniger scharf, priorisierte das Wesentliche etwas schwächer und ging weniger gut mit Mehrdeutigkeit um.
Doch die breiteren Benchmarks setzen es deutlich höher an: Artificial Analysis gibt ihm 57, damit praktisch auf einer Stufe mit Claude Opus 4.7. In der Arena ist es ebenfalls sehr stark — etwa beim kreativen Schreiben, in Mathematik, beim Coding und bei Hard Prompts hält es sich nahe an der Spitze.
4. DeepSeek V4 Pro — stark, aber nicht ganz an der Spitze
DeepSeek V4 Pro kam in meinem Test als Tiefstes der vier heraus — schnell, scharfsinnig, gut in Mustererkennung, aber weniger rigoros in Genauigkeit, Testen und Umgang mit Unsicherheit.
Das hat sich in den Benchmarks am deutlichsten bestätigt. Artificial Analysis gibt ihm 52, also unter GPT-5.5, Claude und Gemini. Dabei ist es wichtig zu sagen, dass es kein „dummes Modell" ist — im Gegenteil, es ist ein sehr starkes Open-Weights-Modell, nur in dieser Elite-Gruppe nicht ganz oben.
Wie gut hat die eine Frage also getroffen?
Aus meiner Sicht überraschend gut.
Hauptsächlich verfehlt hat sie, wie sehr sie Gemini unterschätzt hat. Aber die Hauptstruktur hat sie getroffen:
- GPT-5.5 und Claude sind an der Spitze.
- DeepSeek V4 Pro ist von den vieren das schwächste.
- Der Unterschied zwischen den Modellen liegt nicht nur darin, ob sie ein Ergebnis berechnen, sondern darin, ob sie Unsicherheit zugeben, nach Gegenbeispielen suchen und eine elegante Vermutung nicht mit einem Beweis verwechseln.
Und genau das war das Ziel.
Es ging mir nicht um einen „neuen Benchmark", sondern um einen Lackmustest der Intelligenz: eine Frage, die das Modell zwingt, nicht nur Rechnen, sondern seine Denkweise zu zeigen.
Und dabei zeigte sich etwas durchaus Ermutigendes:
Eine gut entworfene einzelne Frage ersetzt keine Benchmarks. Aber sie kann den Charakter eines Modells überraschend gut offenlegen.
Detailansicht — Intelligence Index zum 29. 4. 2026
Hier sehen Sie die Modelle in größerer Detailtiefe — eine vollständige Aufschlüsselung des Intelligence Index über die wichtigsten Anbieter (Stand 29. 4. 2026):
Welches Modell liefert Ihnen aktuell die besten Ergebnisse? Sind Sie eher Team GPT oder Team Claude? Schreiben Sie es mir in die Kommentare!
#KuenstlicheIntelligenz #LLM #ChatGPT #Claude #TechTrends #Alphai