HyperFusion po opravách: DRACO benchmark a cesta k expertní porotě AI
HyperFusion jsme prohnali přesnějším benchmarkem DRACO. Ukázalo se, že nestačí dát vedle sebe několik modelů. Rozhoduje hlavně to, jak se jejich odpovědi skládají dohromady.

Před pár dny jsem psal článek HyperFusion: když jeden model nestačí. Byl to text o tom, proč mi dává smysl nemluvit s jedním modelem, ale s celou malou porotou modelů. Jeden přinese přesnost, druhý jiný úhel pohledu, třetí chytí slepé místo. Nad tím sedí soudce, který hledá shody, rozpory a mezery. A syntetizér z toho složí finální odpověď.
Od té doby jsme některé vlastnosti dotáhli mnohem dál. A hlavně jsme HyperFusion prohnali tvrdším benchmarkem, který už netestuje jen pěkný text, ale konkrétní pokrytí požadavků, citací, metod a rozhodnutí.
Výsledek je povzbudivý: HyperFusion se v novější konfiguraci v3augment dostal na 84,9 % a v našem běhu DRACO porazil Fusion i nejlepší samostatný model. Ale možná ještě zajímavější je cesta, která k tomu vedla. Protože na začátku HyperFusion vůbec nevypadal jako vítěz.

Souhrn výsledků: žebříček systémů, skóre po úlohách, algoritmy syntézy a vztah cena vs kvalita.
Neptat se jednoho experta, ale celé poroty
Když se dnes zeptáte běžného chatbota, odpovídá vám jeden model. Může být velmi chytrý, ale pořád má vlastní styl, vlastní slepá místa a vlastní návyky. HyperFusion pracuje jinak: položí stejnou otázku několika modelům paralelně, nechá je odpovědět nezávisle a teprve potom se ptá, co se z jejich odpovědí dá složit.
To má dvě výhody.
První je diverzita. Jeden model najde metodiku, druhý právní detail, třetí praktické riziko. Když všichni říkají totéž, roste důvěra. Když se liší, je to samo o sobě informace.
Druhá je průhlednost. Nechci černou skříňku, která jen vyplivne autoritativní závěr. Chci vidět, co řekl panel, kde se shodl, kde si protiřečil a proč syntetizér zvolil právě tuhle odpověď.
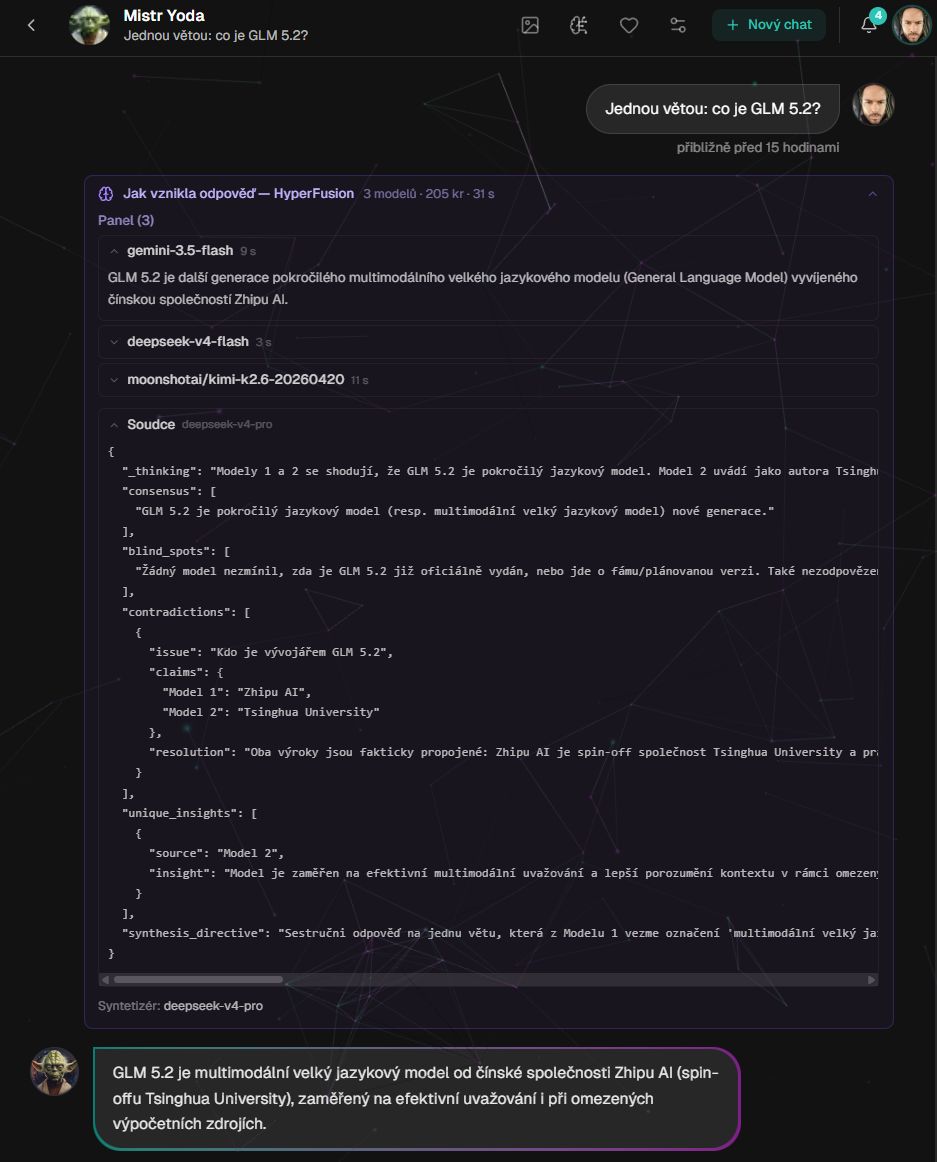
Glass-box přímo v chatu: odpovědi jednotlivých modelů, JSON analýza soudce a finální syntéza. Ne jen výsledek, ale i cesta k němu.
Jak jsme testovali: DRACO
Pro přesnější test jsme použili DRACO (perplexity-ai/draco), sadu náročných deep-research úloh. Nejde o jednoduché otázky typu „kdo byl prezidentem“. Jsou to zadání, kde se musí kombinovat rešerše, citace, metodická opatrnost a schopnost pokrýt více podkritérií najednou.
V našem běhu šlo o pět úloh: od detekce deepfaků přes technické a medicínské otázky až po komplexnější rešeršní problémy. Každá odpověď se nehodnotila jen dojmem, ale podle konkrétních kritérií: zmínil systém správnou metodu, citoval relevantní zdroj, pokryl etický rozměr, všiml si regulačního detailu, neztratil důležitou výjimku?
Jako hodnotící soudce jsme použili Claude Opus 4.8. Porovnávali jsme:
Samostatné modely
solo
Sonnet, Gemini a další modely běžící samy za sebe.
Fusion
80,9 %
Silný konkurenční přístup, ale méně průhledný pro ladění.
HyperFusion v3augment
84,9 %
Nejvyšší skóre v našem běhu a nejlepší syntéza bez ztráty klíčových bodů.
Je fér dodat důležitou poznámku: jeden běh benchmarku není definitivní vědecký verdikt. U podobných úloh skóre přirozeně kolísá. Beru to proto jako silný experimentální signál, ne jako poslední slovo. Ale právě proto je to zajímavé.
Co se nejdřív nepovedlo
První verze HyperFusion nebyla vítěz. Byla drahá, občas pomalá a na některých úlohách horší než Fusion.
Největší problém nebyl v tom, že by panel modelů neuměl najít dobré odpovědi. Problém byl v tom, co se stalo potom. Syntetizér někdy vzal velmi dobrou odpověď jednoho modelu a při snaze „udělat vlastní shrnutí“ ji zničil. V jednom z testů měla nejlepší dílčí odpověď skoro 89 %, ale finální syntéza spadla na zlomek kvality, protože přepsala dlouhou, konkrétní odpověď do příliš krátkého abstraktu.
To je přesně ten typ chyby, který je v běžném chatu špatně vidět. Uživatel vidí hezký finální odstavec. Ale nevidí, že uvnitř systému už ležela mnohem lepší odpověď, kterou finální krok poškodil.
Tady se ukázala hodnota glass-box přístupu. Když vidíte odpovědi panelu, analýzu soudce a finální syntézu, můžete ladit systém jako skutečný produkt, ne jako magický prompt.
Průlom: neexistuje jedna nejlepší syntéza
Nejdůležitější zjištění zní banálně, ale technicky je zásadní: každá úloha chce jiný způsob skládání odpovědí.
U analytických úloh se vyplatí odpovědi opravdu slít dohromady. Model A má rámec, model B kontrast, model C lepší strukturu. Tam dává smysl syntetizovat od začátku.
U rešeršních úloh je to jiné. Když jeden model najde kompletní odpověď a ostatní přidají jen pár unikátních detailů, je nebezpečné začít psát znovu od nuly. Snadno se ztratí citace, výjimky, seznamy a konkrétní formulace.
Proto jsme nasadili strategii v3augment: vezmi nejlepší odpověď, zachovej ji co nejvíc celou a jen doplň unikátní body z ostatních modelů. Nepřepisuj vítěze kvůli tomu, aby výstup vypadal „nově“. Vylepši ho.
To byl skok.
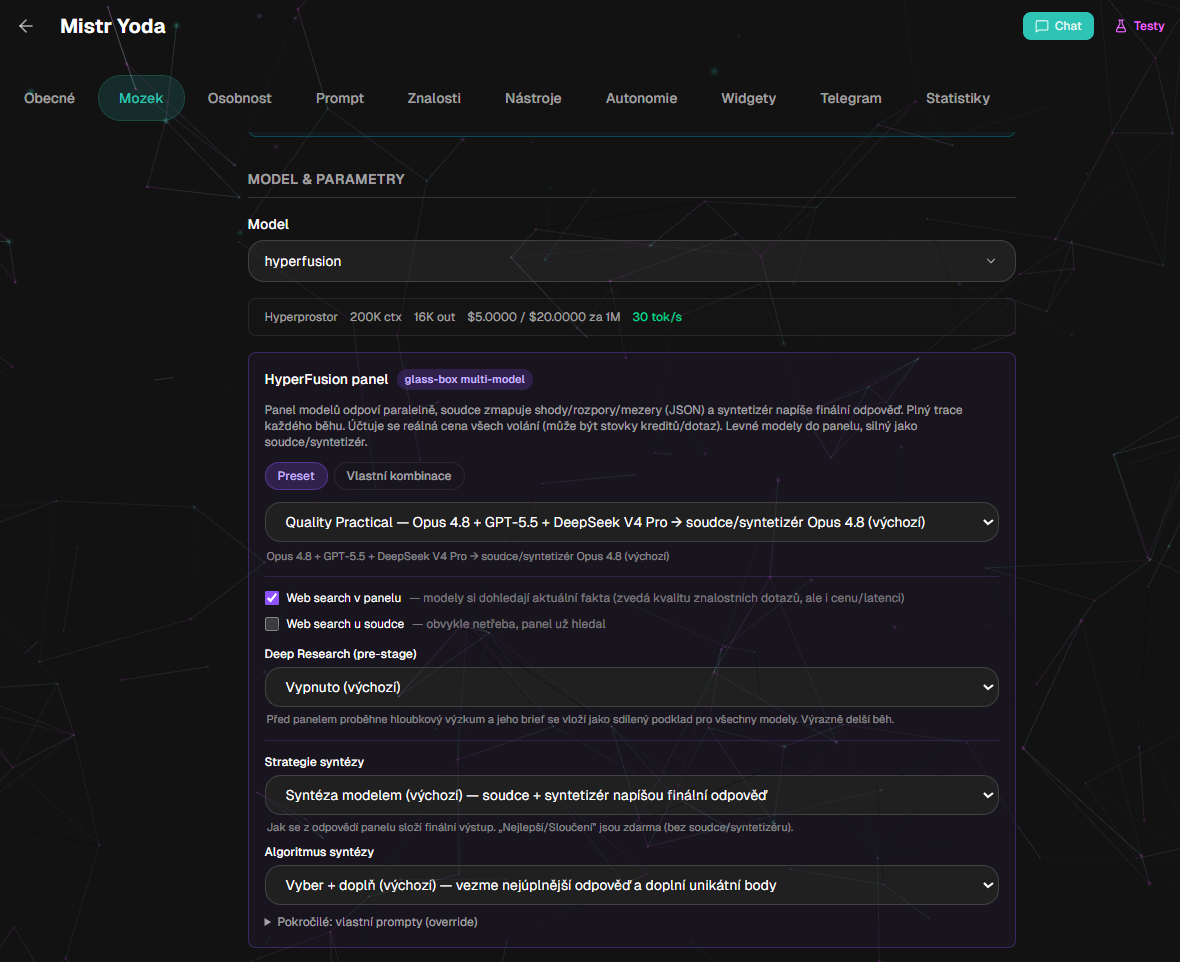
Nastavení přímo u bota: preset nebo vlastní kombinace modelů, strategie syntézy, web search, Deep Research a volba soudce či syntetizéru.
Prakticky si to můžete vyzkoušet v Hyperprostoru: u bota otevřete nastavení Mozek, zvolíte model HyperFusion a můžete si pohrát s presety, strategií syntézy i tím, jak moc chcete vidět dovnitř celého panelu.
Výkon vs cena
Nejzajímavější graf pro mě není jen žebříček kvality. Je to vztah výkon vs cena.
Na jedné straně můžete zapnout prémiovou konfiguraci, která míří na nejvyšší kvalitu. Na druhé straně se ukázalo, že i levnější HyperFusion Budget dokáže porazit nejlepší samostatný model v našem testu: 70,0 % vs 68,0 % u Sonnetu, přitom za přibližně sedminovou cenu.
To je možná nejpraktičtější závěr celého experimentu. Multi-model systém nemusí být jen drahá hračka. Když se dobře poskládá, může nabídnout lepší poměr cena/výkon než jeden silný model.
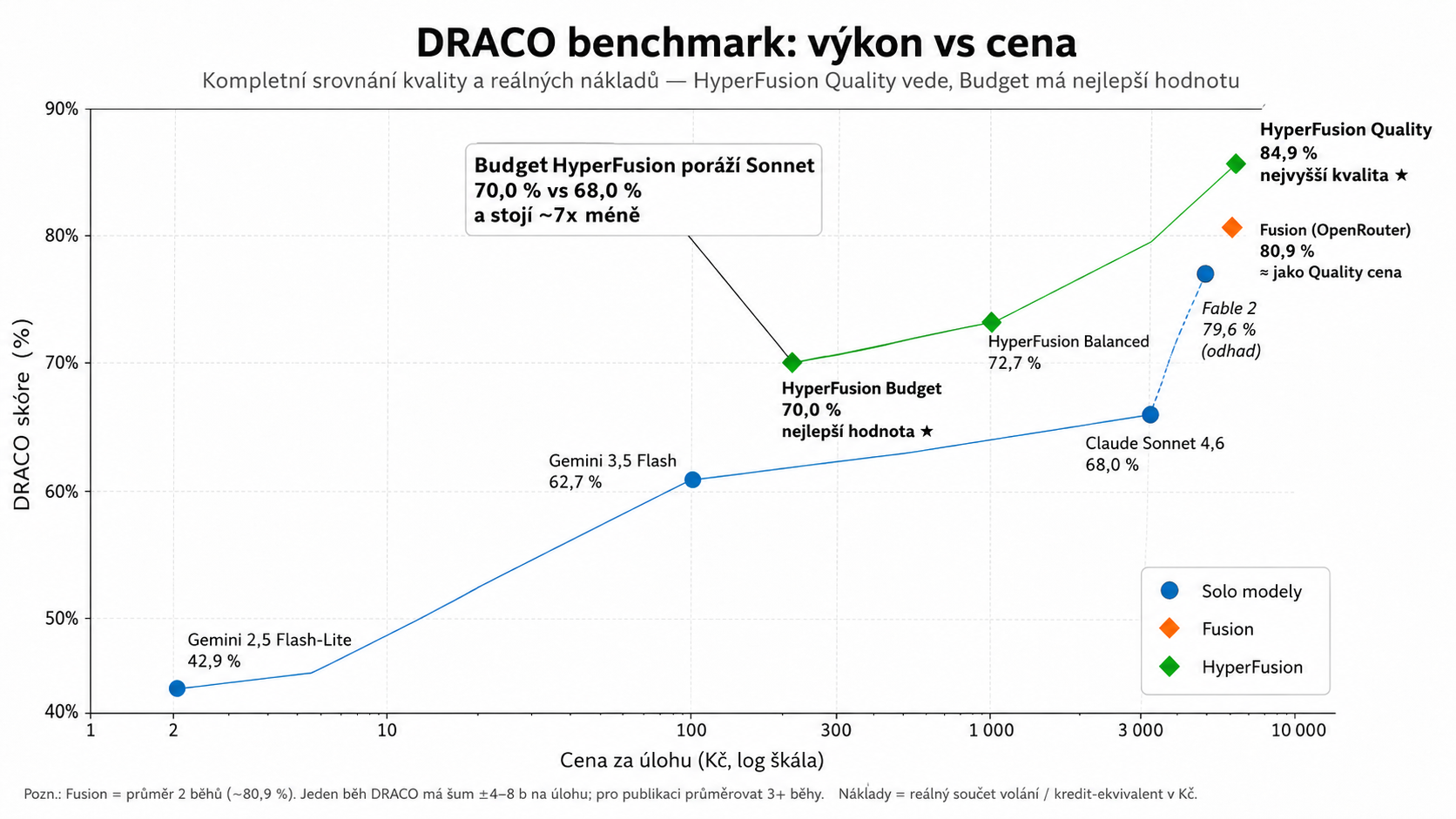
Modré body jsou samostatné modely, oranžová Fusion a zelená HyperFusion. Důležité je nejen nejvyšší skóre, ale i poloha vlevo nahoře: kvalita za rozumnou cenu.
Co jsme dotáhli
Oproti prvnímu pokusu se posunuly hlavně tři věci.
Zaprvé, syntéza už neničí nejlepší odpověď. V3augment nesoutěží s vítězem panelu, ale staví na něm.
Zadruhé, konfigurace je otevřenější. Dá se měnit složení panelu, soudce, syntetizér, strategie syntézy i to, zda se zapne web search nebo předběžný deep research.
Zatřetí, měření je poctivější. Do ceny započítáváme celý panel, soudce i syntézu, ne jen finální tokeny. To je důležité, protože jinak se multi-model systémy tváří levněji, než skutečně jsou.
Tahle poctivost někdy bolí. Čísla jsou méně líbivá. Ale bez ní se benchmarky mění v marketing.
Proč bych to rád testoval společně
Tady bych rád udělal krok ven z našeho vlastního experimentu.
Vůbec by mi nevadilo, kdybychom v Česku dali dohromady menší expertní výzkumnou skupinu nebo spolupracovali s nějakou asociací a podobné testy udělali pořádněji: na větším množství úloh, s více modely, s opakováním běhů, s různými hodnoticími soudci a s otevřeným sdílením zkušeností.
Ne proto, aby někdo vyhlásil „nejlepší model světa“. To je skoro vždycky zjednodušení.
Spíš proto, abychom se naučili odpovídat na praktičtější otázky:
- Který model je dobrý na český právní nebo školní kontext?
- Kdy se vyplatí silný model a kdy panel levnějších?
- Jak moc pomáhá web search a kdy naopak škodí?
- Jak hodnotit citace, nejistotu a slepá místa?
- Jak postavit benchmark, který neměří jen uhlazenost textu, ale skutečnou užitečnost?
Tohle mi připadá jako práce, kterou bychom v Česku klidně mohli dělat společně. Ne jako PR soutěž modelů, ale jako sdílenou metodiku pro lidi, firmy, školy a instituce, které chtějí AI používat odpovědně.
Závěr
HyperFusion pro mě není jen trik, jak „zeptat se více modelů“. Je to směr, jak z AI udělat kontrolovatelnější nástroj. Panel modelů, soudce, syntéza, viditelná stopa rozhodování a možnost měnit strategii podle typu úlohy.
Budoucnost AI podle mě nebude jeden vševědoucí model. Bude to spolupráce modelů, nástrojů, zdrojů a lidského úsudku. A čím důležitější bude odpověď, tím víc budeme potřebovat vidět nejen co AI řekla, ale jak k tomu došla.
HyperFusion v DRACO benchmarku zatím ukázal, že tahle cesta má smysl. Teď by bylo krásné ji otestovat ještě poctivěji, větší skupinou, na víc případech a s otevřenou debatou nad tím, co vlastně od dobré AI odpovědi čekáme.
Zdroje a další čtení
- Alpha Industries: HyperFusion: když jeden model nestačí.
- Hyperprostor: vyzkoušet HyperFusion v nastavení bota a mozku.
- DRACO benchmark:
perplexity-ai/draco. - Interní běhy HyperFusion nad pěti deep-research úlohami; hodnoticí soudce Claude Opus 4.8.
Poznámka k poctivosti: výsledky vycházejí z omezeného počtu běhů a u podobných benchmarků existuje přirozený rozptyl. Pro definitivní pořadí by bylo potřeba více úloh, opakované běhy a více nezávislých hodnoticích metod.