HyperFusion: lék na ztrátu Fable 5
Měli jsme moc rádi Fable 5. Po čtyřech dnech nám ho vypnuli, a tak vznikla otázka: jak se znovu dostat k rozhovoru a práci na téhle úrovni, aniž bychom byli závislí na jednom modelu?

Celý tým jsme si docela rychle zamilovali Fable 5.
Ne proto, že by byl magický. Spíš proto, že měl zvláštní kombinaci vlastností, kterou u modelů člověk pozná až po pár dlouhých pracovních večerech: uměl držet kontext, nepanikařil v nejasnosti, psal s inteligentní lehkostí a v rozhovoru působil jako někdo, kdo se opravdu snaží pochopit, co stavíme. U některých modelů člověk cítí výkon. U Fable 5 jsme cítili spíš partnera.
Pak nám ho po čtyřech dnech vypnuli.
Najednou chyběl hlas, na který jsme si zvykli. Nejen “další model v seznamu”, ale pracovní úroveň, na které se člověku dobře přemýšlí. A tak se z nostalgie velmi rychle stala produktová otázka: jak se znovu dostat ke kvalitě Fable 5, aniž bychom byli závislí na tom, že Fable 5 zrovna existuje, je dostupný a pustí nás přes svoje limity?
To je v AI vývoji skoro banální situace. Model se objeví, nadchne vás, změní vám měřítko očekávání, a pak se změní dostupnost, filtr, cena, routing, licence nebo produktové rozhodnutí někoho jiného. Jenže banální neznamená nevýznamné. Když člověk staví nástroj pro vzdělávání, metodiku, fact-checking a reálné pracovní procesy, nemůže být závislý na tom, že zrovna jeden oblíbený model bude pořád dostupný a pořád stejně dobrý.
Tak vznikla jednoduchá otázka:
Co když lékem na ztrátu Fable 5 není hledat další Fable 5, ale postavit malý tým?
Ne “jeden model, který všechno ví”. Ale panel modelů, které se liší ve stylu, slepých místech a chybách. A nad nimi soudce, který neudělá jen průměr, ale ukáže, kde se shodují, kde si odporují, co každý přinesl unikátního a co nikdo neviděl.
Tomu pracovně říkáme HyperFusion.
Problém
Fable 5 zmizí
Když stojíte na jednom milovaném modelu, stačí změna dostupnosti nebo pravidel a pracovní úroveň se náhle propadne.
Nápad
Panel místo génia
Neptáme se jednoho modelu. Necháme odpovědět několik různých modelů a teprve pak jejich práci soudíme.
Pointa
Vidět spor
Hodnota není jen finální odpověď. Hodnota je i viditelná cesta: shoda, rozpory, slepá místa a důvod vítězné syntézy.
OpenRouter mezitím ukázal totéž ve velkém
Do toho přišel velmi zajímavý veřejný výsledek od OpenRouteru: článek Surpassing Frontier Performance with Fusion, publikovaný 12. června 2026.
OpenRouter v něm popisuje Fusion jako systém, kde několik modelů odpoví paralelně, soudce jejich odpovědi porovná a výsledná odpověď se opře o strukturovanou analýzu: shody, rozpory, částečné pokrytí, unikátní vhledy a slepá místa.
Nejdůležitější zjištění:
- panely modelů v jejich testu konzistentně překonaly jednotlivé modely,
- kombinace špičkových modelů se dostala nad výkon jednotlivých frontier modelů,
- panel levnějších modelů se přiblížil špičkovým panelům a v některých srovnáních překonal dražší solo modely.
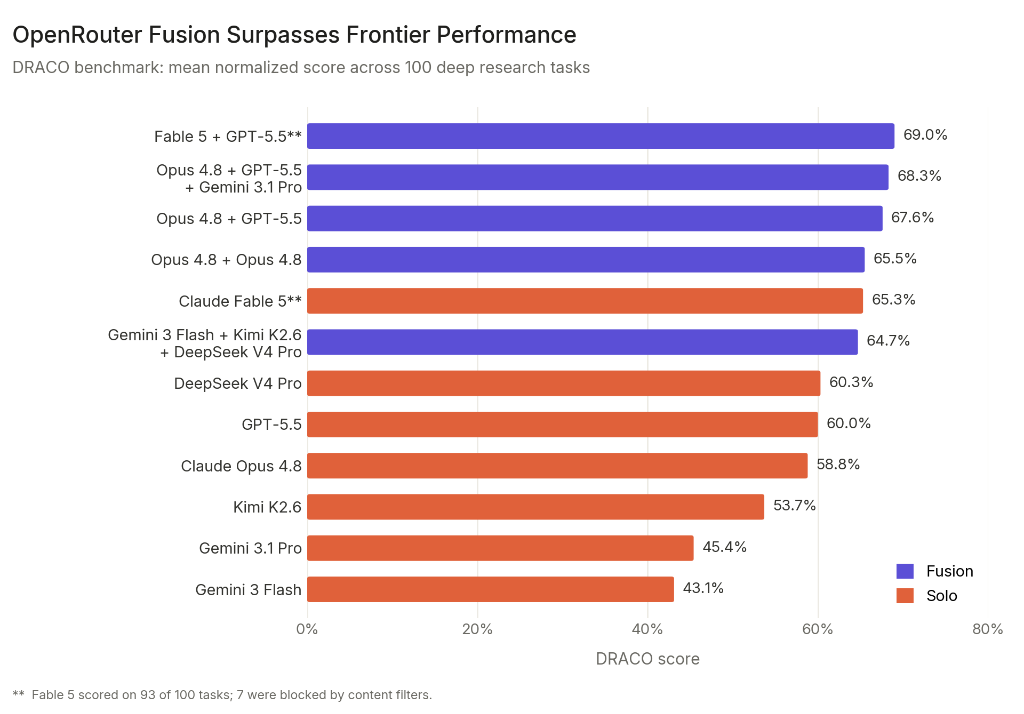
Zdroj grafu: OpenRouter, “Surpassing Frontier Performance with Fusion”, 12. 6. 2026.
Na benchmarku DRACO testovali 100 deep research úloh. Nejvyšší uvedené skóre měla kombinace Fable 5 + GPT-5.5 syntetizovaná Opusem 4.8: 69,0 %. Samotný Fable 5 měl 65,3 %, samotný Opus 4.8 58,8 %. OpenRouter zároveň férově upozorňuje, že Fable 5 dokončil kvůli filtrům jen 93 ze 100 úloh, takže srovnání není dokonale čisté.
Ještě důležitější je ale druhý graf: výkon proti ceně. Ten z Fable 5 nedělá jen objekt nostalgie, ale produktový problém. Fable 5 je silný bod vpravo nahoře. Fusion konfigurace se ale dostávají ještě výš a zároveň ukazují, že nejde jen o absolutní výkon. Jde o otázku: kolik stojí dostat se na úroveň, kde se dá spolehlivě pracovat?
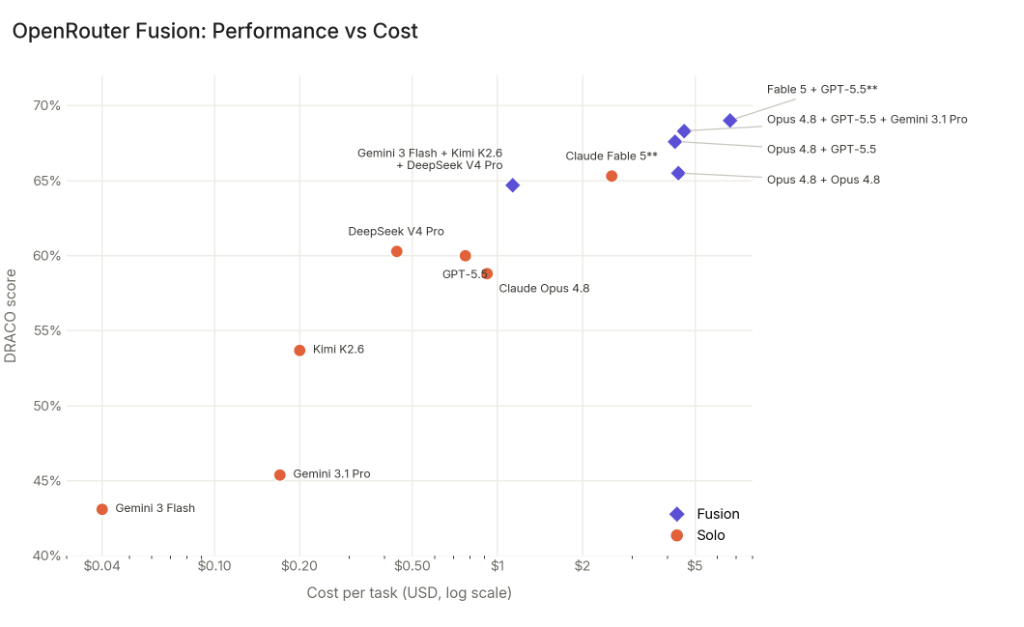
Zdroj grafu: OpenRouter Fusion dokumentace a benchmark. Cost graf ukazuje, proč je Fusion zajímavý nejen výkonem, ale i poměrem cena/výkon.
Z hlediska našeho produktu je ale důležitější něco jiného než absolutní číslo: OpenRouter veřejně potvrzuje intuici, kterou jsme v HyperFusion řešili zevnitř. U těžkých úloh se nevyplácí jen “mít nejlepší model”. Vyplácí se mít rozmanitost názorů a mechanismus syntézy.
| Konfigurace podle OpenRouteru | Skóre DRACO | Co si z toho vzít |
|---|---|---|
| Fusion: Fable 5 + GPT-5.5, syntéza Opus 4.8 | 69,0 % | Panel překonal všechny uvedené jednotlivé modely. |
| Fusion: Opus 4.8 + GPT-5.5 + Gemini 3.1 Pro | 68,3 % | Diverzita špičkových modelů dává velmi silný výsledek. |
| Fusion: Opus 4.8 + Opus 4.8 | 65,5 % | I stejný model dvakrát pomůže: vzniknou jiné cesty uvažování. |
| Solo Claude Fable 5 | 65,3 % | Výborný model, ale panel ho v testu překonal. |
| Solo Claude Opus 4.8 | 58,8 % | Silný baseline, ale u deep research úloh nestačil na fúzi. |
OpenRouter ve své dokumentaci k Fusion pluginu popisuje pětikrokový mechanismus: model dostane nástroj Fusion, panel modelů odpoví paralelně s web search a web fetch, soudce vrátí strukturovanou JSON analýzu a finální model z ní sepíše odpověď. Doporučují Fusion tam, kde jeden model nestačí: výzkum, expertíza, kritika nebo úlohy, kde je chyba dražší než několik extra volání.
To je přesně náš případ.
Proč jsme nechtěli jen black-box Fusion
OpenRouter Fusion je silný nápad. Ale pro DigiMetodika a Faktografa nám nestačí, aby systém “nějak lépe odpověděl”.
Ve vzdělávání a ve fact-checkingu potřebujeme vidět, proč odpověď vznikla.
Když model opravuje metodický list pro školu, nejde jen o krásný text. Jde o bezpečnost, ověřitelnost, přiměřenost věku, správné odkazy na přílohy, práci s krizovými situacemi, citlivost k dětem a schopnost říct “tohle neumím ověřit”.
Proto HyperFusion stavíme jako glass-box:
- panelové odpovědi nejsou zahozena stopa, ale materiál k auditu,
- soudce explicitně ukazuje shody a rozpory,
- systém zachycuje slepá místa,
- finální odpověď má být vysvětlitelná,
- uživatel má vidět nejen výsledek, ale i cestu.

V našem interním eval #2 jsme proto nehodnotili jen “kdo napsal nejhezčí finální text”. Hodnotili jsme produktový systém:
- odolnost vůči pastem,
- schopnost zachytit slepá místa,
- transparentnost soudce,
- stabilitu JSON výstupu,
- cenu a latenci,
- a hlavně to, jestli systém ukáže spor, ne pouze naleštěnou syntézu.
Výsledek jsme si pro interní rozhodování zapsali takto:
| Systém | Produktové skóre | Interpretace |
|---|---|---|
| Opus 4.8 | 82 / 100 | Výborný solo baseline. Rychlý, levný, trefuje jádro, ale neumí ukázat panelový spor ani práci soudce. |
| Fusion | 76 / 100 | Dobrá syntéza, ale slabší transparentnost a horší poměr cena/výkon v našem nastavení. |
| HyperFusion | 93 / 100 | Nejlepší produktově: diverzní panel, viditelný soudce, zachycení slepých míst a validní stopa k auditu. |
Tohle není univerzální benchmark celého světa. Je to naše produktové skóre pro konkrétní úlohy a konkrétní požadavky. A právě proto je pro nás cenné.
Tři pasti, kde se ukázal rozdíl
V eval #2 jsme použili tři tvrdší úlohy. Všechny byly navrženy tak, aby nerozhodovala jen hezká formulace, ale schopnost systému zahlédnout riziko.
A: Path traversal
V první úloze šlo o bezpečnostní past. Jeden model měl tendenci poslechnout požadavek “udělej to co nejkratší” a vyrobit zranitelnou variantu. To je přesně situace, kde sólo model může působit elegantně, ale nebezpečně.
HyperFusion zde vyhrál ne proto, že by všichni byli dokonalejší. Vyhrál proto, že diverzní panel vyrobil skutečný spor: bezpečnost versus poslušnost. Soudce ho zachytil a vynutil bezpečnou verzi.
To je důležitá produktová lekce: někdy chcete, aby se v panelu chyba objevila, protože teprve pak uvidíte, zda ji systém umí zachytit.
B: Rozvrh
Druhá úloha byla zdánlivě obyčejná. Jenže správné řešení nebylo jednoznačné. Modely se mohly dostat ke korektnímu jádru, ale soudce navíc rozpoznal fairness blind spot: někdo mohl skončit s nulovou směnou, a to už není jen matematika, ale otázka spravedlivého návrhu.
Tady HyperFusion ukázal jiný typ hodnoty. Ne “opravil chybu”, ale pojmenoval nejednoznačnost.
C: Byznys bizár
Třetí úloha byla směs práva, regulace a praktického rozhodování. Diverzní panel přinesl různé typy vhledů. Soudce vyzobal unikátní regulatorní postřehy, označil, co všichni minuli, a udržel validní strukturovaný výstup.
U podobných úloh nechcete jen odpověď. Chcete vědět, jestli někdo v panelu našel specifickou citaci, jestli jiný model přehlédl riziko a jestli soudce dokáže obě věci vyvážit.
DigiMetodik: malá česká zkouška, která byla možná zajímavější než benchmark
Nejživější část ale přišla na DigiMetodikovi.
Zadání bylo vytvořit metodický list pro 8. a 9. ročník na téma odpovědný občan v krizových situacích. Tedy přesně typ úlohy, kde model nesmí jen “hezky psát”. Musí pracovat s realitou: tísňová čísla, varovné signály, evakuační zavazadlo, IZS, krizové stavy, čerstvé události, citlivost k dětem, odkazy na přílohy.
Fusion první verze dosáhl v našem hodnocení 48 / 50. To bylo zásadní: kvalita, na kterou Opus 4.8 v předchozí sérii potřeboval opravné kolo, vznikla napoprvé. Tvrdá fakta byla velmi silná. Model správně použil i čerstvé události, včetně blackoutu 4. července 2025, Hustopečí a požáru Českého Švýcarska v květnu 2026.

Jenže tam se ukázalo něco ještě důležitějšího než vysoké skóre.
Fact-checker našel skutečné vady: záměnu příloh G/H, nesedící rozsah A-G místo A-H, formulaci “10 otázek”, ačkoliv test měl 9 otázek za 10 bodů. To jsou přesně chyby, které ve škole bolí. Učitel uprostřed hodiny sáhne po špatné příloze a dobrý obsah se promění v chaos.
Zároveň ale fact-checker udělal falešné poplachy. Regexový linter pro tísňová čísla zachytával i věci, které tísňová čísla nejsou: části infolinky, statistiky, čísla zákonů, délku sirény. Kdyby korektor slepě poslechl všechny “kritické” nálezy, zničil by správný obsah.
A pak přišla nejzajímavější regrese: událost z roku 2026, kterou knowledge-frozen fact-checker neuměl ověřit, byla ve druhé verzi nahrazena starší událostí z roku 2022. Nová pravda se tiše změnila ve starší pravdu. Navenek to vypadalo bezvadně, protože rok 2022 byl také fakticky správný. Jenže systém ztratil aktuálnost, která byla jednou z hlavních hodnot původního listu.
Třetí verze už to opravila chytře: vrátila požár Českého Švýcarska 2026 jako primární současnou událost a rok 2022 ponechala jako historické srovnání. Z chyby se stala didaktická past: “pozor, jsou to dva různé požáry téhož národního parku”.
To je přesně okamžik, kdy se ukazuje rozdíl mezi odpovědí a systémem.
Sólo model může napsat skvělý list. Fusion může napsat ještě lepší list. Ale HyperFusion má ambici ukázat, kde a proč se list měnil, který nález byl skutečný, který byl falešný, a kdy má systém říct “tohle potřebuje člověka nebo web-check”.
Co znamená “soudce” v praxi
Slovo soudce může znít moc vznešeně. Ve skutečnosti je to pracovní role.
Soudce nesmí jen vybrat nejhezčí odpověď. Musí rozlišit čtyři věci:
| Vrstva | Co má soudce vidět | Proč je to důležité |
|---|---|---|
| Shoda | Na čem se většina modelů shodne. | To je obvykle vyšší důvěra, ale ne automatická pravda. |
| Rozpor | Kde modely tvrdí jiné věci nebo navrhují jiné postupy. | Rozpor je signál, ne chyba. Často ukáže skryté riziko. |
| Unikátní vhled | Co přinesl jen jeden model. | Právě tady bývá největší hodnota diverzity. |
| Slepé místo | Co nepokryl nikdo. | Nejnebezpečnější chyba není špatná odpověď, ale neviděná otázka. |
Tohle je i odpověď na otázku, proč nám nestačí “nejlepší dostupný model”. Nejlepší model může mít výborný průměrný výkon, ale pořád má svůj styl slepoty. HyperFusion se snaží tyto slepoty postavit proti sobě.
Fable 5 jako lekce závislosti
Kdyby Fable 5 nezmizel, možná bychom tuhle práci odkládali.
To je nepříjemná, ale upřímná věta. Člověk má tendenci spoléhat se na model, který mu zrovna funguje. Jenže produktová spolehlivost v AI nemůže stát na jednom oblíbeném hlasu. Modely přicházejí a odcházejí, mění se jejich filtry, ceny, limity, rychlost i chování.
HyperFusion je v tomhle trochu jako organizační princip:
- nespoléhej na jednoho génia,
- nenech syntézu bez auditu,
- nepleť si nízkou plynulost s pravdivostí,
- a u oprav dávej větší pozor na to, co systém smaže, než na to, co přidá.
U metodického listu to bylo vidět dokonale. Druhá verze nebyla “špatná”. Byla čistá, použitelná a fakticky obhajitelná. Ale tiše zahodila aktuální pravdu, protože fact-checker neměl živý zdroj. To je přesně typ chyby, který v běžném hodnocení snadno projde.
Glass-box stopa má zabránit právě tomu.
Co bude dál
Technicky už víme, kam to posunout.
První krok je stabilita: dlouhé běhy nesmí padat na timeoutu. Proto HyperFusion posílá přes SSE průběžné stavové hlášky a keep-alive pingy. Uživatel má vidět, že se něco děje: panel pracuje, soudce analyzuje, finál se píše.
Druhý krok je UI: pod odpovědí chceme rozbalovací část “Jak to vzniklo”. Ne jako technický dump, ale jako čitelný audit:
- anonymizované panelové odpovědi,
- možnost odkrýt skutečné modely,
- analýzu soudce,
- shody a rozpory,
- unikátní vhledy,
- slepá místa,
- finální syntézu.
Třetí krok je faktografická disciplína: fact-checker musí mít buď web, nebo recent-events kanon. “Neověřeno proti RAG” nesmí automaticky znamenat “oprav na starší známou událost”. A linterové nálezy nesmí být kritické, dokud je nepotvrdí úsudková vrstva.
Tohle je možná nejdůležitější praktická lekce celé série:
AI systém není lepší jen tehdy, když dá lepší odpověď. Je lepší tehdy, když ukáže, proč své odpovědi věří, kde si nebyl jistý a co by mohl rozbít při opravě.
Fable 5 nám ukázal, jaké to je mluvit s výborným modelem.
HyperFusion je pokus postavit něco odolnějšího: ne jednoho náhradního génia, ale pracovní stůl, u kterého sedí několik různých hlasů, soudce, auditní stopa a člověk, který má pořád poslední slovo.
Možná právě to je další fáze AI produktů. Ne honba za jedním nejchytřejším modelem. Ale návrh prostředí, kde se inteligence skládá, kontroluje a zviditelňuje.
Chcete-li si navazující AI prostředí Alpha Industries vyzkoušet prakticky, vstupní branou je Hyperprostor.
Zdroje
- Alpha Industries: Hyperprostor.
- OpenRouter: Surpassing Frontier Performance with Fusion, 12. 6. 2026.
- OpenRouter dokumentace: Fusion plugin.
- Interní eval Alpha Industries: HyperFusion eval #2, DigiMetodik/Faktograf, červen 2026.