Jedna otázka vs. deset velkých benchmarků: jak moc se mini IQ test trefil?
Před pár dny jsem nejnovějším AI modelům položil jen jednu jedinou otázku — ne benchmark, ne tabulku skóre, jen jedinou intelektuální past. Po pár dnech je čas srovnat výsledek s velkými veřejnými benchmarky, které se mezi tím objevily. GPT-5.5 vede, Claude Opus 4.7 mu šlape na paty, Gemini 3.1 Pro byl největší odchylka, DeepSeek V4 Pro nejníž. Otázka, kterou by stálo za to položit každému modelu — než mu začnete věřit.

Před pár dny jsem zkusil malý experiment: dát nejnovějším AI modelům jen jednu jedinou otázku.
Ne benchmark na stovkách úloh. Ne tabulku skóre. Jen jednu intelektuální past.
Model měl odvodit pravidla umělých funkcí mep a dap, spočítat nový případ, přiznat nejednoznačnost, navrhnout nejlepší test, který by jeho hypotézu mohl vyvrátit, a říct, čím si je nejméně jistý.
Pointa nebyla „změřit IQ" v psychologickém smyslu nebo ukázat, že klasické benchmarky jsou k ničemu.
Kdybych měl modelu položit jen jednu otázku, která co nejlépe odkryje jeho analytické myšlení, metakognici a práci s nejistotou — jaká by to byla?
Prohlédlo si to přes 50 tisíc lidí, ale podle komentářů spoustě lidí pointa unikla. A po pár dnech je zajímavé srovnat výsledek s velkými veřejnými benchmarky, které se mezi tím objevily.
📎 Pokud jste původní článek nečetli, najdete ho zde: Jedna otázka místo deseti benchmarků: mini IQ test pro nejnovější AI modely
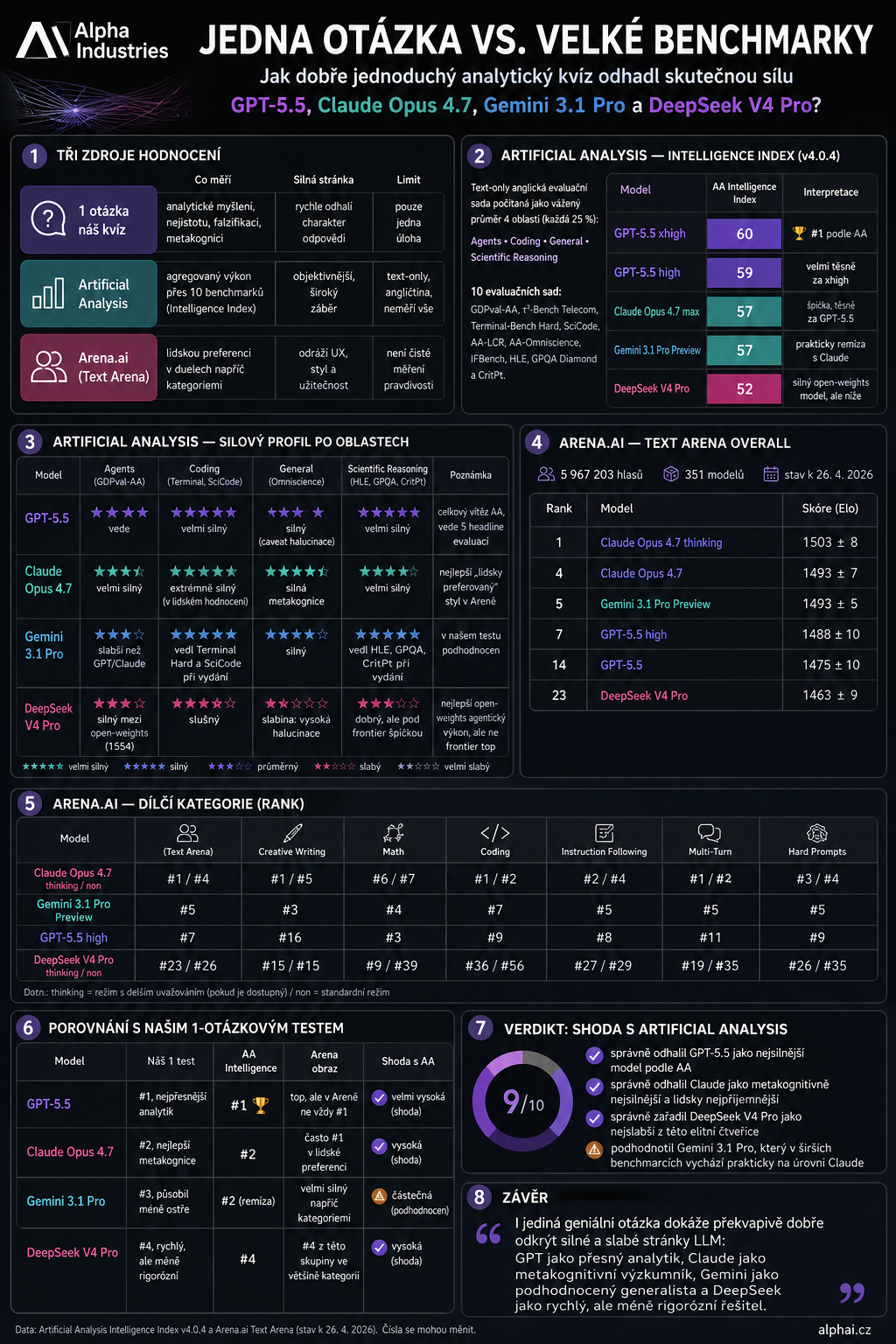
Jak měří „inteligenci" Artificial Analysis
Artificial Analysis Intelligence Index dnes počítá inteligenci modelů jako vážený průměr čtyř oblastí:
- Agents — 25 %
- Coding — 25 %
- General — 25 %
- Scientific Reasoning — 25 %
Dohromady jde o 10 evaluačních sad: GDPval-AA, τ²-Bench Telecom, Terminal-Bench Hard, SciCode, AA-LCR, AA-Omniscience, IFBench, Humanity's Last Exam, GPQA Diamond a CritPt.
Je fér dodat, že jde o text-only anglickou evaluační sadu, takže neměří všechno — neměří třeba češtinu, multimodalitu, hlas nebo reálnou UX použitelnost.
A jak to vyšlo?
🥇 GPT-5.5 — nejjistější analytik
GPT-5.5 je podle Artificial Analysis aktuálně nahoře. GPT-5.5 xhigh má Intelligence Index 60, GPT-5.5 high 59.
To docela dobře odpovídá mému jednootázkovému testu, kde působil jako nejjistější analytik: přesný, kompaktní, matematicky ostrý.
🥈 Claude Opus 4.7 — výzkumník s metakognicí
Claude Opus 4.7 má podle Artificial Analysis 57, tedy těsně za GPT-5.5. V lidském hodnocení je ale často ještě výš — v Text Arena Overall je Claude Opus 4.7 thinking dokonce první.
To je přesně zajímavý rozdíl: GPT působí jako velmi přesný „matematický střelec", Claude jako výzkumník s lepší metakognicí, opatrností a formulací nejistoty.
🥉 Gemini 3.1 Pro — překvapení v širších benchmarcích
Gemini 3.1 Pro byl v mém jednootázkovém testu největší odchylka. V té konkrétní úloze působil méně ostře, trochu méně prioritizoval podstatné a méně dobře pracoval s nejednoznačností.
Jenže širší benchmarky ho staví výrazně výš: Artificial Analysis mu dává 57, tedy prakticky na úroveň Claude Opus 4.7. V Areně je také velmi silný — například v kreativním psaní, matematice, kódování i hard prompts se drží blízko špičky.
4. DeepSeek V4 Pro — silný, ale ne na špičce
DeepSeek V4 Pro vyšel v mém testu jako nejníž z této čtveřice — rychlý, bystrý, schopný pattern recognition, ale méně rigorózní v přesnosti, testování a práci s nejistotou.
To se podle benchmarků potvrdilo nejvíc. Artificial Analysis mu dává 52, tedy pod GPT-5.5, Claude i Gemini. Zároveň je důležité říct, že to není „hloupý model" — naopak je to velmi silný open-weights model, jen v této elitní skupině není na špičce.
Takže jak moc se ta jedna otázka trefila?
Podle mě překvapivě dobře.
Netrefila hlavně to, jak podhodnotila Gemini. Ale trefila hlavní strukturu:
- GPT-5.5 a Claude jsou špička.
- DeepSeek V4 Pro je z této čtveřice nejhorší.
- Rozdíl mezi modely není jen v tom, jestli spočítají výsledek, ale jestli umí přiznat nejistotu, hledat proti-příklad a nezaměnit elegantní domněnku za důkaz.
A to byl přesně cíl.
Nešlo mi o „nový benchmark". Šlo mi o lakmusový papírek inteligence: jednu otázku, která model donutí ukázat nejen výpočet, ale i způsob myšlení.
A tady se ukázalo něco docela povzbudivého:
Jedna dobře navržená otázka benchmarky nenahradí. Ale může překvapivě dobře odhalit charakter modelu.
Detailní pohled — Intelligence Index k 29. 4. 2026
Zde vidíte modely v širším detailu — kompletní rozpis Intelligence Indexu napříč hlavními poskytovateli (k 29. 4. 2026):
Který model teď dává nejlepší výsledky vám? Jste spíš tým GPT, nebo tým Claude? Napište mi do komentářů!
#UmeleInteligence #LLM #ChatGPT #Claude #TechTrendy #Alphai