Unter den besten Modellen der künstlichen Intelligenz für die Verarbeitung natürlicher Sprache (Bert, …
Unter den besten Modellen der künstlichen Intelligenz für die Verarbeitung natürlicher Sprache (Bert, Robert, GPT-2 oder Megatron) kam letzte Woche ein weiterer Spieler hinzu: ALBERT! ALBERT wird von Google Research und dem Toyota Technological Institute bereitgestellt. Interessant ist nicht nur, dass das Modell fantastische Ergebnisse in klassischen Aufgaben wie GLUE, RACE oder SQuAD erzielt, sondern vor allem, dass es kleiner ist als seine Vorgänger!
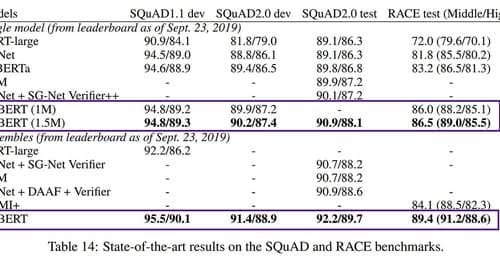
Unter den besten Modellen der künstlichen Intelligenz für die Verarbeitung natürlicher Sprache (Bert, Robert, GPT-2 oder Megatron) kam letzte Woche ein weiterer Spieler hinzu: ALBERT! ALBERT wird von Google Research und dem Toyota Technological Institute bereitgestellt. Interessant ist nicht nur, dass das Modell fantastische Ergebnisse in klassischen Aufgaben wie GLUE, RACE oder SQuAD erzielt, sondern vor allem, dass es kleiner ist als seine Vorgänger! Zum Beispiel hat das alte BERT x-large etwa 1,27 Milliarden Parameter, während ALBERT x-large „nur“ 59 Millionen Parameter hat.
Wie ist es den Autoren gelungen, die Genauigkeit zu erhöhen und gleichzeitig die Anzahl der „Gehirnzellen“ zu verringern?
Dafür gibt es drei Gründe: 1 — Faktorisiertes Einbettungsparameter Das heißt, eine effizientere Nutzung der Parameter. ALBERT verwendet anstelle einer einzigen Einbettungsschicht zwei kleinere. Der One-Hot-Vektor wird in eine kleinere Schicht mit weniger Dimensionen übertragen.
2 — Cross Layer Parameter Sharing Schichten ALBERT optimiert auch die Verteilung der Parameter (Feed Forward Network und Attention) über alle Schichten hinweg. Stellen Sie sich vereinfacht vor, dass das neue Gehirn die einzelnen Gehirnzentren besser miteinander verbunden hat.
3 — SOP (Sentence Order Prediction) Algorithmus ersetzt NSP (Next Sentence Prediction) Bereits die Autoren von RoBERTa bemerkten, dass der NSP-Algorithmus nicht sehr effektiv war. Die Autoren von ALBERT bringen jedoch einen neuen, besseren Algorithmus namens SOP mit. Während sich das Modell bei NSP darauf trainiert, den richtigen Satz zu erkennen, indem es einen aus demselben Dokument und einen falschen aus einem anderen Dokument nimmt, bezieht SOP beide Sätze aus demselben Dokument, wobei das richtige Paar in der korrekten Reihenfolge und das falsche in vertauschter Reihenfolge vorliegt. Dadurch vermeidet ALBERT ungewollte Themenvorhersagen und kann feinere Beziehungen zwischen den einzelnen Sätzen lernen.
Zusammenfassend lässt sich sagen, dass eine neue Reihe von Modellen für die Textverarbeitung entstanden ist, die sehr präzise ist und gleichzeitig weniger Platz benötigt.
Quellen: https://medium.com/@lessw/meet-albert-a-new-lite-bert-from-google-toyota-with-state-of-the-art-nlp-performance-and-18x-df8f7b58fa28
https://arxiv.org/abs/1909.11942v1
Ursprünglich veröffentlicht auf Facebook — Link zum Beitrag
Původní zdroj: facebook