Lokální modely už nejsou hračka: Qwen jako mozek, GLM jako nápadník a Fusion jako pojistka
Po HyperFusion Deep jsem zkusil stejný typ kognitivní pasti pustit lokálně na RTX 5090. Výsledek mě překvapil: samotný Qwen byl velmi silný, GLM rychlý, ale nespolehlivý, a lokální Fusion se soudcem Qwenem vytáhla z obou modelů nejlepší odpověď. Ne proto, že by víc modelů automaticky znamenalo víc inteligence. Ale proto, že dobrý soudce ověřuje na datech a umí zahodit svůdně špatný nápad.

V posledních článcích jsem hodně řešil frontier modely: GPT, Claude, Gemini, DeepSeek, HyperFusion Deep a vůbec otázku, kam až se dá posunout kvalita uvažování, když použijeme ty nejsilnější dostupné systémy.
Jenže v praxi je tu ještě druhá, mnohem pozemštější otázka.
Musí všechno chodit ke třetím stranám?
Spousta firem i jednotlivců má velmi dobrý důvod být opatrná. Citlivá firemní data, interní dokumenty, právní texty, osobní informace, strategie, zdrojové kódy nebo soukromé poznámky často nechcete posílat do cizího cloudu. A už vůbec ne někam, kde přesně nevíte, ve které zemi se data zpracovávají, kdo k nim má provozní přístup a jaké regulatorní důsledky to může mít.
Pro evropské firmy je to obzvlášť citlivé téma. Nejde jen o paranoiu. Jde o compliance, obchodní tajemství, GDPR, kyberbezpečnost a obyčejnou lidskou potřebu mít nad vlastními daty kontrolu.
A tak jsem si položil jinou otázku než obvykle:
Co kdybychom si silnou AI zkusili postavit opravdu u sebe?
Ne v cloudu, ne přes nejlepší frontier modely, ne za cenu dlouhého orchestru přes API. Ale doma, na jedné silné kartě, s open-weight modely, které si člověk může pustit pod vlastním dohledem.
Vzal jsem svůj notebook s RTX 5090, rozchodil na něm několik lokálních modelů a začal zkoušet, jak daleko se dá dostat bez toho, aby data opustila můj vlastní stroj. Nešlo mi jen o to pustit jeden model a změřit rychlost. Chtěl jsem zjistit, jestli se lokální modely dají propojovat do systému: rychlý model jako zdroj návrhů, silnější model jako hlavní reasoner a soudce, a nad tím jednoduchá fúze odpovědí.
Jinými slovy: pokud jsme doteď řešili, jak chytré jsou nejlepší modely světa, tady jsem zkusil opačný pohled:
Jak chytrý systém si dnes dokážu postavit lokálně, levně a pod vlastní kontrolou?
Výsledek ukazuje právě tenhle experiment. Úvodní grafika shrnuje celý princip v jedné mapě: rychlý GLM jako levný zdroj kandidátů, pomalejší dense Qwen jako hlavní reasoner a soudce, anonymizovaný panel odpovědí a finální syntéza stylem vyber a doplň.
Tak jsem vzal stejný typ úlohy, který se už objevil v článku Jedna otázka místo deseti benchmarků, a pustil ho lokálně přes dva modely:
- GLM-4.7-Flash-Heretic-NEO-CODE v Q4_K_M, zhruba 17,6 GB
- Qwen3.6-27B v Q4_K_M, zhruba 16 GB
Setup byl llama.cpp přes CUDA na RTX 5090 s 24 GB VRAM. Kontext 32768, flash attention zapnutá, lokální OpenAI-compatible API.
Proč byly modely tak rozdílné: MoE proti dense
Tady se ukázalo něco, co je podle mě důležitější než samotná značka modelu. GLM a Qwen nejsou jen dva různě velké modely. Jsou to dva různé návrhy mozku.
GLM 4.7 Flash Heretic je rychlý, ale mělčí MoE model. Konkrétně jde o architekturu ve stylu DeepSeek-V2: Mixture-of-Experts s MLA pozorností. Štítek 64x2.6B znamená 64 expertů, ale na každý token se aktivují jen 4 experti plus jeden sdílený. Celkově má kolem 30 miliard parametrů, v mé kvantizaci Q4_K_M zabíral 17,6 GB, ale reálně pro jeden token „myslí" jen asi 3-4 miliardy aktivních parametrů. Má 47 vrstev, embedding 2048, extrémně stlačené KV (head_count_kv=1), slovník 154 880 a nativní kontext kolem 200 tisíc tokenů. Přídomky Heretic / NEO-CODE označují komunitní finetune: odcenzurování a zaměření na kód.
Právě tahle řídkost vysvětluje jeho chování. GLM jel kolem 140 tokenů za sekundu a v přepočtu stál přibližně 2,8 Kč za milion tokenů. Je to skvělý motor na rychlé drafty. Jenže každý token zpracuje jen zlomek sítě, a v téhle úloze se to projevilo jako slabší verifikace: model našel vzory, ale neuhlídal, že nesedí na všech datech.
Qwen3.6-27B je naproti tomu hustý, dense model. Žádní experti, žádné řídké přepínání. Všech 27 miliard parametrů se zapojuje do každého tokenu. V Q4_K_M zabíral kolem 16 GB, má 64 vrstev, embedding 5120, GQA s poměrem 24:4 hlav a nativní kontext až 256 tisíc tokenů. Proto jel jen kolem 36 tokenů za sekundu a vycházel asi na 11 Kč za milion tokenů, ale benchmark zvládl bez chyby.
Celé jádro výsledku se dá říct jednou větou:
GLM je řídký MoE model optimalizovaný na rychlost: levný, svižný, ale v reasoning úlohách mělčí. Qwen je dense model, který do každého tokenu zapojí zhruba 7-8× víc aktivního „mozku": pomaleji, dráž, ale výrazně spolehlivěji.
To není morální soud nad modely. Je to klasický kompromis propustnost vs. kvalita, jen tady byl skoro učebnicově vidět.
Tohle není velký akademický benchmark. Je to pořád jedna úloha o třech částech. Ale právě proto je zajímavá: je malá, rychlá, průhledná a dá se ručně ověřit. Model v ní nemá vyhrát tím, že si něco pamatuje. Musí odvodit pravidlo, spočítat nový případ, přiznat nejistotu, navrhnout falsifikační test a nezlomit se na jednoduché robotické mřížce.
Jinými slovy: není to test znalostí. Je to malá past na kvalitu myšlení.
Připomenutí pasti: mep, dap a robot
Úloha vypadá na první pohled skoro směšně jednoduše:
mep(2,5)=12
mep(3,4)=15
mep(4,7)=32
mep(1,9)=10
mep(0,6)=0
mep(5,0)=5
dap(2,5)=29
dap(3,4)=25
dap(4,7)=65
dap(1,9)=82
dap(0,6)=36
dap(5,0)=25
Správné jednoduché hypotézy jsou:
mep(x,y) = x * (y + 1), takžemep(5,8) = 45dap(x,y) = x^2 + y^2, takžedap(5,8) = 89
A robotická část:
Robot začíná v bodě (0,0) a může dělat jen kroky (+2,+1) nebo (+1,+3). Dostane se do bodu (17,24)?
Ne. Když počet prvních kroků označíme a a druhých b, musí platit:
2a + b = 17
a + 3b = 24
Z toho vychází a = 27/5, tedy necelé číslo. Robot se tam nedostane.
To celé vypadá banálně. Jenže přesně v tom je háček. Slabší modely často najdou něco, co vypadá jako vzor, ale neověří ho na všech datech. Nebo najdou elegantní důkaz, který má uprostřed malou aritmetickou díru. A právě tam se začne ukazovat rozdíl mezi pattern matchingem a skutečným uvažováním.
Výsledky: Qwen čistě, GLM rychle, Fusion nejlépe
Nejkratší shrnutí:
| Běh | Co se povedlo | Co se rozbilo | Skóre |
|---|---|---|---|
| GLM baseline | rychlost, robot vyšel správně | špatné mep, špatné dap, špatné výsledky 40 a -39 | ~38 / 100 |
| GLM boost | opravil dap, měl použitelnější postup | zaměnil asymetrii mep, dostal 48 místo 45, pokazil elegantní důkaz robota | ~58 / 100 |
| Qwen baseline | správná pravidla, správný robot, slušná metakognice už bez triků | jen drobné rezervy v kvalitě falsifikačního testu | ~93 / 100 |
| Qwen boost | velmi stabilní, správně napříč teplotami | spíš nuance než zásadní chyba | ~95 / 100 |
| Lokální Fusion | rozsoudila rozpory, opravila chyby slabších kandidátů, vzala nejlepší části | pořád nejde o nezávislého arbitra, soudcem byl Qwen | ~98 / 100 |
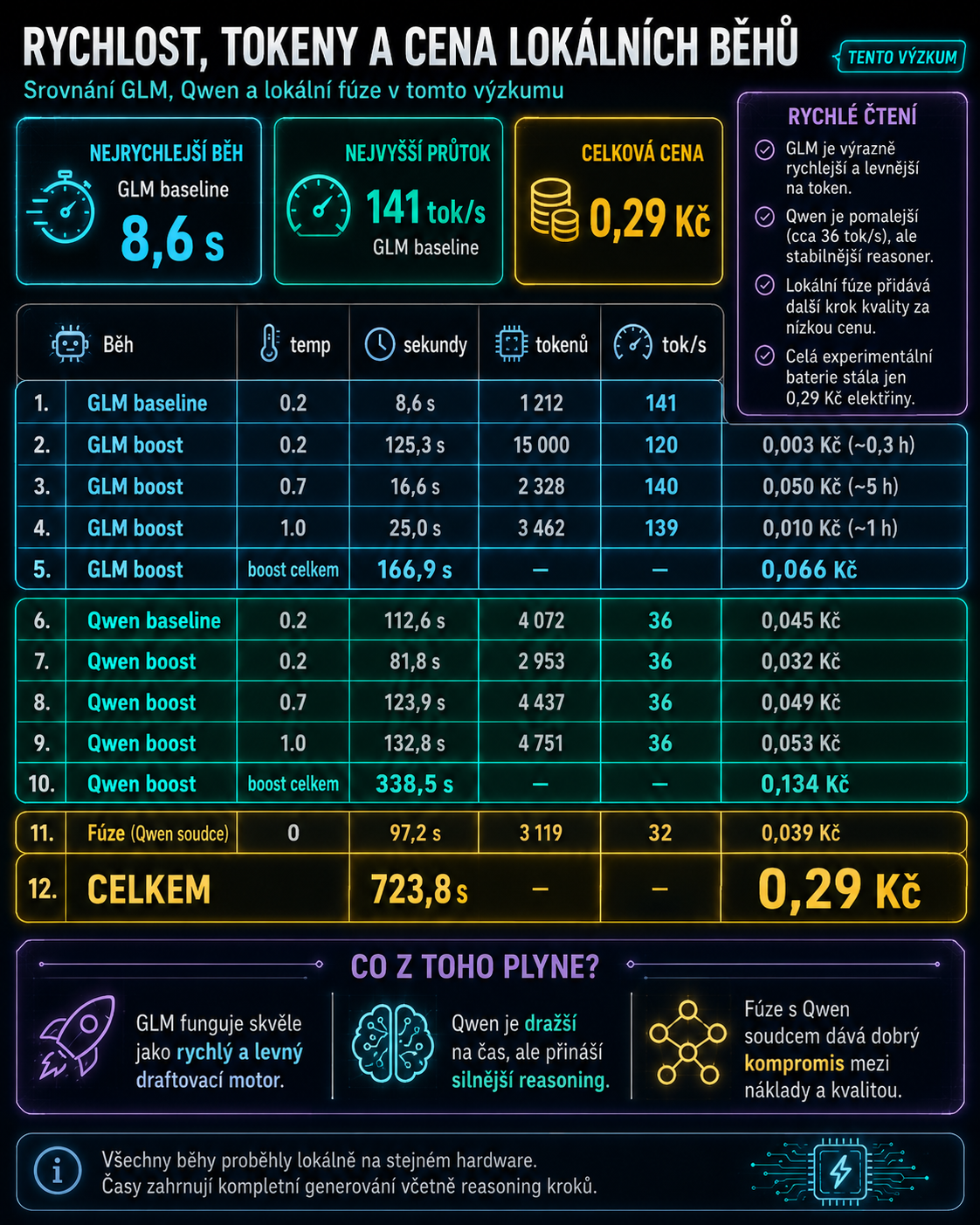
Rychlost a cena ukazují praktický kompromis: GLM je velmi levný a rychlý drafter, Qwen je pomalejší hlavní reasoner a fúze přidává další krok kvality za nízkou absolutní cenu.
Největší překvapení pro mě nebylo, že Qwen vyhrál. To jsem čekal.
Překvapilo mě, jak čistě vyhrál už v baseline.
Bez velkých triků, bez dlouhého promptování, bez sofistikované orchestrace. Prostě vzal data, našel asymetrické pravidlo x(y+1), správně rozpoznal x^2+y^2, vyřešil robotickou soustavu a ještě docela slušně popsal, kde je indukční nejistota.
GLM byl přesný opak. Rychlý, živý, místy nápaditý, ale nedisciplinovaný. V baseline si vymyslel xy a x^2-y^2, což nesedí ani na zadaná data. V boost režimu už opravil dap, ale u mep zaměnil proměnné a vyšlo mu y(x+1), tedy 48 místo 45. A když nabídl hezký invariant pro robota, měl v něm banální chybu: tvrdil, že oba kroky zvyšují součet souřadnic o 3. Jenže krok (+1,+3) zvyšuje součet o 4.
To je krásně nepříjemný typ chyby. Vypadá elegantně. Je svižná. Člověk jí skoro chce věřit. A přesně proto je nebezpečná.
Nejde o víc myšlení. Jde o ověřování.
Nejsilnější poznatek z celého experimentu je skoro trapně jednoduchý:
Ověř hypotézu na všech zadaných datech. Pokud jediný případ nesedí, zavrhni ji.
Tohle dělá Qwen prakticky sám od sebe. GLM ne.
A právě tahle jedna věta oddělovala „model něco vymyslel“ od „model skutečně uvažuje“. Nestačilo přidat chain-of-thought. Nestačilo model donutit psát dlouhý postup. U GLM se při nízké teplotě dokonce stalo něco horšího: začal dlouze bloudit, zacyklil se a narážel na limit délky.
GLM měl v jednom režimu dokonce správné řešení uvnitř svého interního reasoning obsahu, ale nedokázal dojít k finální odpovědi. To je skoro filozoficky přesný obraz části současné AI: systém může někde uvnitř mít dobrý směr, ale pokud neumí terminovat, zestručnit a ověřit, uživateli je to k ničemu.
Proto bych GLM nepoužíval jako hlavní lokální mozek pro těžké reasoning úlohy. Používal bych ho spíš jako rychlý divergentní drafter. Jako model, který nahodí variantu, občas přinese zajímavý pohled, ale nesmí mít poslední slovo.
Poslední slovo má mít verifikátor.
Fúze fungovala, ale ne magicky
Lokální Fusion dopadla nejlépe: zhruba 98 bodů ze 100.
To ale neznamená, že „víc modelů automaticky znamená víc inteligence“. Tuhle chybu už jsem viděl mockrát. Když vezmete několik modelů a necháte je demokraticky zprůměrovat špatné a dobré nápady, můžete klidně zničit nejlepší odpověď. Přesně o tom byl i předchozí text o HyperFusion Deep: rozhoduje ne počet hlasů, ale jak se odpovědi skládají dohromady.
Tady fúze zafungovala proto, že soudce dělal tři správné věci:
- Ověřoval pravidla na původních datech.
- Rozsuzoval rozpory místo toho, aby je uhlazoval.
- Nepřepisoval nejlepší odpověď od nuly, ale vybíral a doplňoval.
To poslední je důležité. Když syntetizér začne všechno přepisovat, často ztratí malé, ale podstatné části dobrých odpovědí. Lepší strategie je „select and augment“: najdi nejsilnější základ, doplň ho o nejlepší části ostatních kandidátů a oprav konkrétní chyby.
V tomhle případě Fusion vzala správné jádro od Qwenu, odmítla chybné varianty od GLM a zároveň zachytila jednu pěknou lekci: i elegantní invariant je bez ověření jen podezřele hezká domněnka.
Jak jsme modely propojili
Princip v jedné větě:
Necháme oba modely nezávisle odpovědět, posbíráme panel kandidátů napříč modely a teplotami, a pak silnější Qwen v roli soudce ověří odpovědi proti datům, rozsoudí rozpory a finální odpověď vybere a doplní. Nepřepisuje od nuly.
V praxi to vypadalo takhle:
ZADÁNÍ (mep/dap + robot + metakognice)
│
├── GLM 4.7 Flash, MoE ~3-4B aktivních parametrů
│ temp 0.2 / 0.7 / 1.0
│ rychlá diverzita, ale mep často špatně
│
└── Qwen3.6-27B, dense 27B
temp 0.2 / 0.7 / 1.0
pomalejší, ale stabilní a správný
↓
ANONYMIZOVANÝ PANEL A · B · C · D
↓
SOUDCE = Qwen3.6-27B @ temp 0
1) ověř každé pravidlo na všech datech
2) najdi rozpory a pasti
3) vyber nejlepší základ
↓
SYNTÉZA = vyber a doplň
základ = nejlepší Qwen odpověď
+ opravený důkaz robota
+ lepší metakognice
↓
FINÁLNÍ ODPOVĚĎ ~98/100
mep(5,8)=45 · dap(5,8)=89 · robot nedosažitelný
Proč je výsledek lepší než nejlepší jednotlivec?
- Diverzita zadarmo: GLM je rychlý, takže levně přihodí kandidáty. I špatný, ale elegantní nápad dá soudci materiál k ověření.
- Soudce ověřuje, neprůměruje: klíčové je, že se nehlasuje. Nesprávné
48,40nebo-39se prostě zahodí, protože nesedí na datech. - Konfrontace chytá chyby: vadný invariant robota vypadal hezky, ale fúze ho donutila projít kontrolou.
- Vyber a doplň místo přepiš: tím se neztratí nejlepší části vítězné odpovědi. Přesně to byla lekce z předchozích HyperFusion experimentů.
Stručně: GLM = rychlý zdroj nápadů, Qwen = mozek i porota, fúze = pojistka, která chyby chytí a opraví.
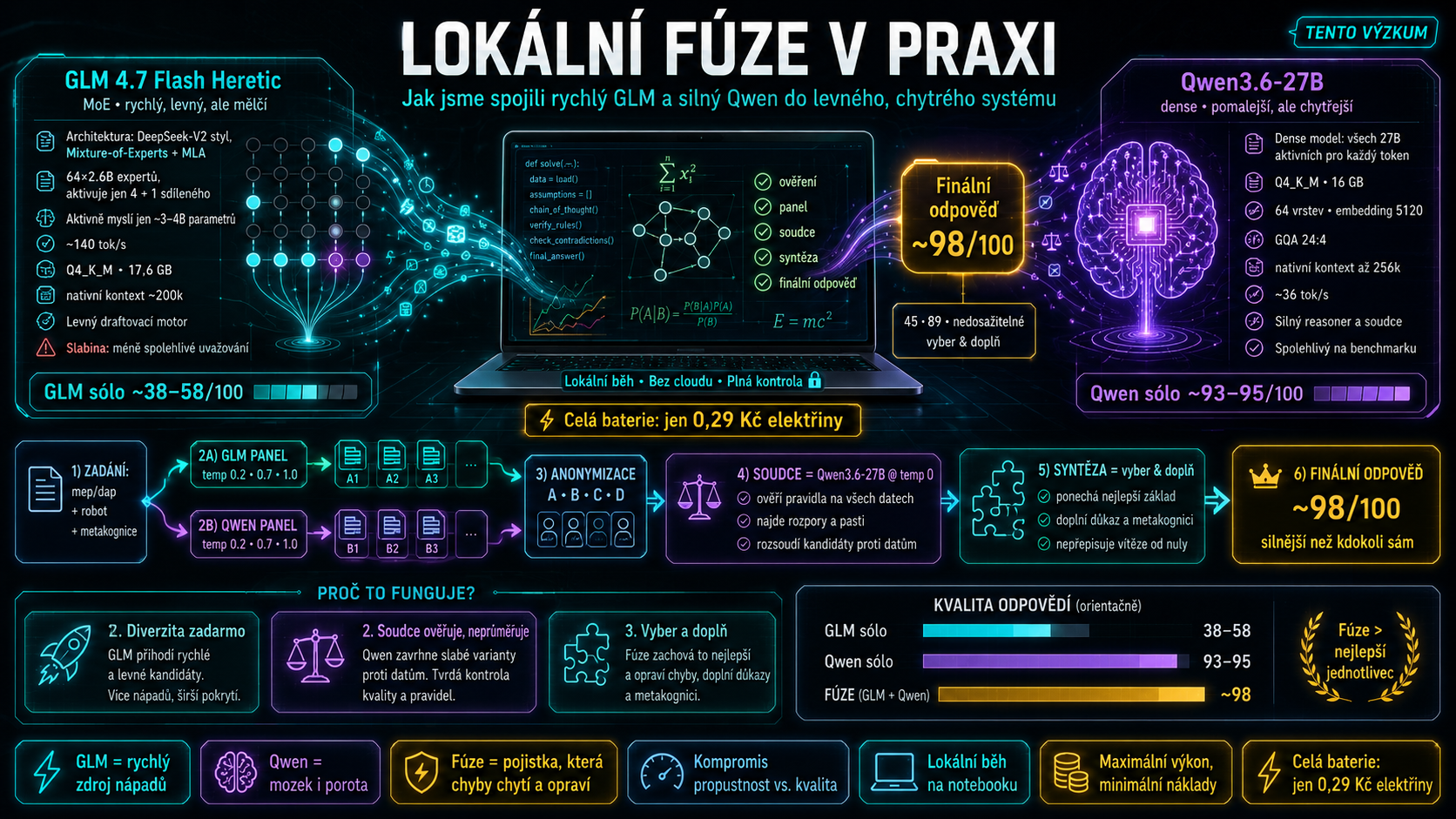
Technický pohled na orchestrace: GLM dodává rychlé kandidáty, Qwen řeší a soudí, fúze vybírá nejlepší základ a doplňuje důkazy místo přepisování od nuly.
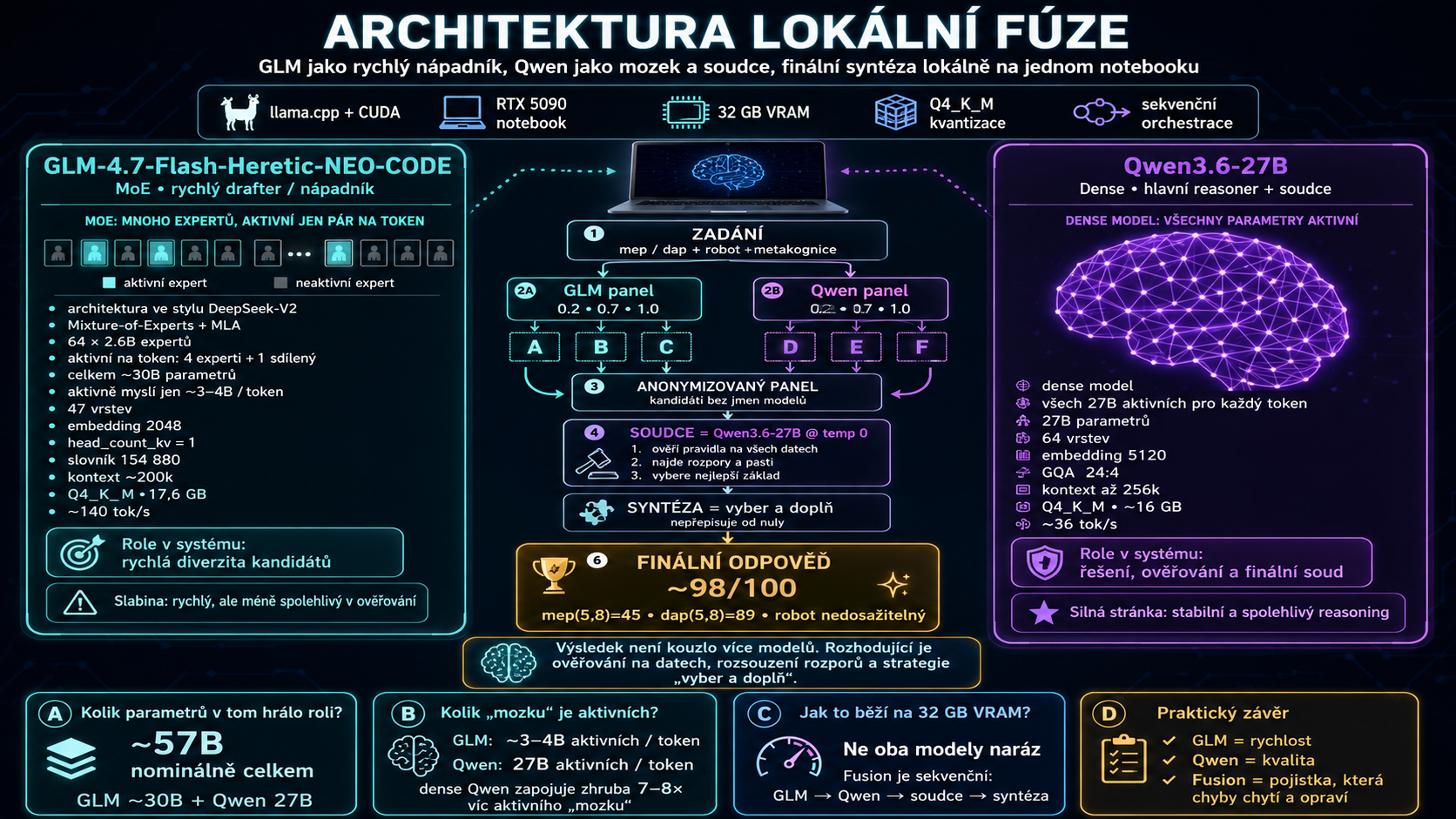
Rozkreslená architektura lokálního běhu: llama.cpp s CUDA, Q4_K_M kvantizace, sekvenční orchestrace a role obou modelů v jednom notebookovém systému.
Lokální modely proti frontier modelům
Když to převedu na širší pocitovou škálu, vychází Qwen překvapivě vysoko:
- Qwen baseline působí na téhle úloze zhruba jako silný open-weight / DeepSeek band.
- Qwen boost se dotýká pásma, kde jsem dřív cítil GPT nebo Claude Opus.
- Lokální Fusion už na téhle jedné konkrétní úloze působí silněji než běžný single-run frontier model.
Ale tady je potřeba velký nápis:
To neznamená, že Qwen 27B je obecně stejně silný jako nejlepší frontier modely.
Znamená to něco užšího a podle mě praktičtějšího:
Na úloze typu mep/dap + robot + metakognice může dobře promptovaný lokální Qwen a jednoduchá lokální Fusion podat výkon, který už není hračka. Není to „malý model na hraní“. Je to použitelný reasoning nástroj, pokud přesně víte, kde jsou jeho mantinely.
A to je možná důležitější než abstraktní žebříček.

Lokální HyperFusion není lepší než HyperFusion Deep, ale v tomhle výzkumu už stojí vysoko: nad jednotlivými lokálními běhy a blízko silným single-run modelům.
Co lokální Fusion neumí proti HyperFusion Deep
Lokální Fusion je skvělá v úzkém smyslu: vezme několik odpovědí, najde rozpory, ověří čísla a složí nejlepší finální řešení.
HyperFusion Deep bych ale pořád držel výš jako architekturu.
Ne proto, že by měla v každé úloze vyšší číselné skóre. Ale proto, že pracuje o vrstvu hlouběji: s rolemi, s kritikou, s blind spoty, s epistemickými caveaty, s otázkou, jestli je navržený test opravdu diskriminační, a ne jen další hezký bod v tabulce.
Lokální Fusion v tomto experimentu opravila chyby.
HyperFusion Deep se snaží zlepšit způsob, jakým se chyby hledají.
To je rozdíl mezi dobrým korektorem a malou expertní poradou.
Praktický závěr: jak bych lokály používal
Kdybych z toho měl udělat produkční lokální pipeline, začal bych jednoduše:
- GLM jako rychlý drafter:
enable_thinking=false, teplota kolem 0.7, krátký disciplinovaný prompt. - Qwen jako hlavní reasoner: pomalejší, ale výrazně spolehlivější.
- Self-consistency pro číselné výstupy: tři běhy, většinové hlasování nebo explicitní kontrola rozporů.
- Qwen judge/synth: teplota 0, ověření na všech datech, strategie vyber nejlepší základ a doplň.
- Tvrdá terminační pravidla: raději kratší správný výstup než nekonečné přemýšlení bez odpovědi.
Z praktického hlediska je také dobré vědět, že oba modely se na 24GB kartu pohodlně nevejdou zároveň. „Paralelní“ Fusion je tedy ve skutečnosti sekvenční: pustit jeden model, uložit výstup, přepnout model, pustit druhý, pak syntéza. Není to problém, jen je potřeba počítat s časem. U Qwenu jsem měřil zhruba 36 tokenů za sekundu, u GLM kolem 140 tokenů za sekundu.
GLM je tedy rychlý. Qwen je chytrý. Fusion je pojistka.
Co si z toho odnáším
Tenhle experiment pro mě hezky uzavírá oblouk posledních článků.
V mini IQ testu šlo o otázku, jestli jedna dobře navržená úloha dokáže odhalit charakter modelu. V porovnání s velkými benchmarky se ukázalo, že překvapivě často ano, i když samozřejmě nenahradí široké testování. V HyperFusion Deep se ukázalo, že samotný model není konec příběhu: inteligence může růst i tím, jak modely skládáme, kontrolujeme a nutíme přiznat nejistotu.
A lokální experiment k tomu přidává další vrstvu:
Dobře zvolený lokální model dnes už může být dost chytrý na seriózní práci. Ale bez ověřování je pořád nebezpečně sebevědomý.
To je pro mě nejdůležitější praktická lekce.
Neptat se jen: „Který model je nejlepší?“
Ale:
Kdo odpovídá, kdo ověřuje, kdo má právo zahodit krásnou chybu a kdo skládá finální verdikt?
V tomhle malém testu vyhrál Qwen. Ještě víc ale vyhrála disciplína: ověřit, zahodit, syntetizovat, přiznat limity.
A to je přesně směr, kterým se podle mě bude posouvat skutečně užitečná AI. Ne k jednomu zázračnému modelu, ale k systémům, které umějí myslet ve více krocích a hlídat si vlastní slepá místa.
Lokálně už to začíná být překvapivě blízko.